 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoCLIP-XL: Advancing Long Description Understanding for Video CLIP Models
Oct 01, 2024Contrastive Language-Image Pre-training (CLIP) has been widely studied and applied in numerous applications. However, the emphasis on brief summary texts during pre-training prevents CLIP from understanding long descriptions. This issue is particularly acute regarding videos given that videos often contain abundant detailed contents. In this paper, we propose the VideoCLIP-XL (eXtra Length) model, which aims to unleash the long-description understanding capability of video CLIP models. Firstly, we establish an automatic data collection system and gather a large-scale VILD pre-training dataset with VIdeo and Long-Description pairs. Then, we propose Text-similarity-guided Primary Component Matching (TPCM) to better learn the distribution of feature space while expanding the long description capability. We also introduce two new tasks namely Detail-aware Description Ranking (DDR) and Hallucination-aware Description Ranking (HDR) for further understanding improvement. Finally, we construct a Long Video Description Ranking (LVDR) benchmark for evaluating the long-description capability more comprehensively. Extensive experimental results on widely-used text-video retrieval benchmarks with both short and long descriptions and our LVDR benchmark can fully demonstrate the effectiveness of our method.
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
May 30, 2024
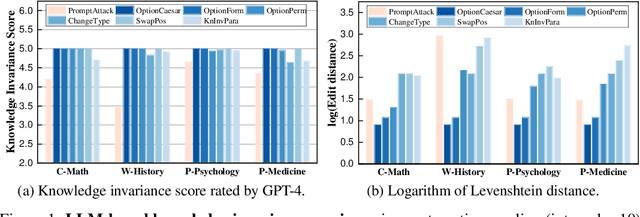

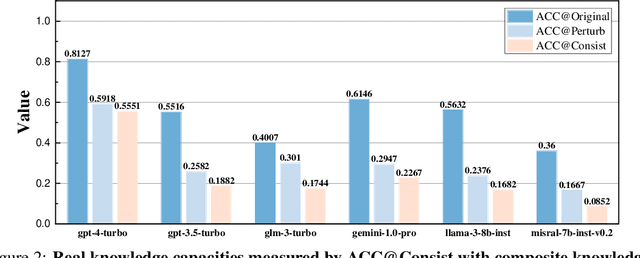
Expert-designed close-ended benchmarks serve as vital tools in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through knowledge-invariant perturbations. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of transition analyses that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six state-of-the-art LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 21% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, potentially being resolved through rote memorization and leading to inflated performance. We also find that the detailed transition analyses by PertEval could illuminate weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Given these insights, we posit that PertEval can act as an essential tool that, when applied alongside any close-ended benchmark, unveils the true knowledge capacity of LLMs, marking a significant step toward more trustworthy LLM evaluation.
EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture
May 29, 2024This paper presents EasyAnimate, an advanced method for video generation that leverages the power of transformer architecture for high-performance outcomes. We have expanded the DiT framework originally designed for 2D image synthesis to accommodate the complexities of 3D video generation by incorporating a motion module block. It is used to capture temporal dynamics, thereby ensuring the production of consistent frames and seamless motion transitions. The motion module can be adapted to various DiT baseline methods to generate video with different styles. It can also generate videos with different frame rates and resolutions during both training and inference phases, suitable for both images and videos. Moreover, we introduce slice VAE, a novel approach to condense the temporal axis, facilitating the generation of long duration videos. Currently, EasyAnimate exhibits the proficiency to generate videos with 144 frames. We provide a holistic ecosystem for video production based on DiT, encompassing aspects such as data pre-processing, VAE training, DiT models training (both the baseline model and LoRA model), and end-to-end video inference. Code is available at: https://github.com/aigc-apps/EasyAnimate. We are continuously working to enhance the performance of our method.
EasyPhoto: Your Smart AI Photo Generator
Oct 07, 2023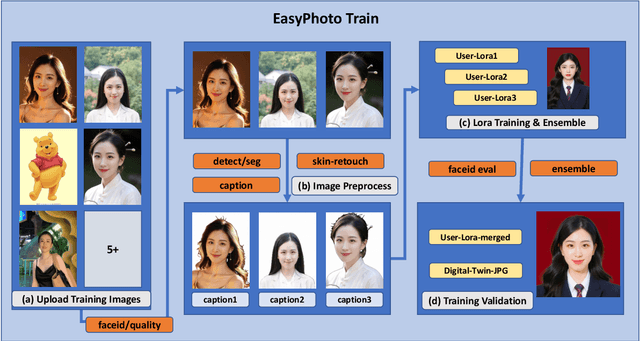
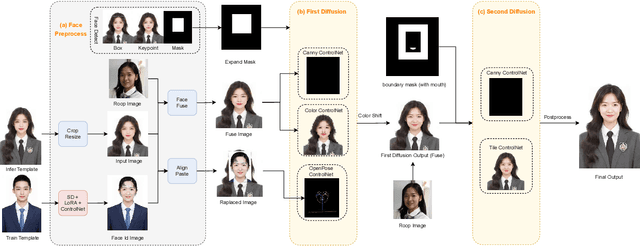
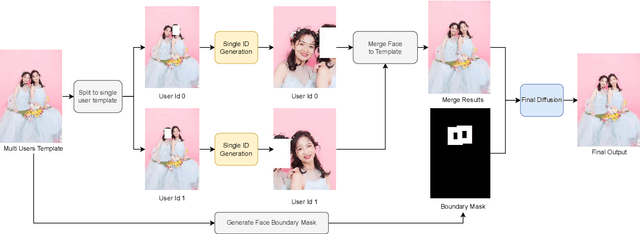

Stable Diffusion web UI (SD-WebUI) is a comprehensive project that provides a browser interface based on Gradio library for Stable Diffusion models. In this paper, We propose a novel WebUI plugin called EasyPhoto, which enables the generation of AI portraits. By training a digital doppelganger of a specific user ID using 5 to 20 relevant images, the finetuned model (according to the trained LoRA model) allows for the generation of AI photos using arbitrary templates. Our current implementation supports the modification of multiple persons and different photo styles. Furthermore, we allow users to generate fantastic template image with the strong SDXL model, enhancing EasyPhoto's capabilities to deliver more diverse and satisfactory results. The source code for EasyPhoto is available at: https://github.com/aigc-apps/sd-webui-EasyPhoto. We also support a webui-free version by using diffusers: https://github.com/aigc-apps/EasyPhoto. We are continuously enhancing our efforts to expand the EasyPhoto pipeline, making it suitable for any identification (not limited to just the face), and we enthusiastically welcome any intriguing ideas or suggestions.
RemovalNet: DNN Fingerprint Removal Attacks
Aug 31, 2023With the performance of deep neural networks (DNNs) remarkably improving, DNNs have been widely used in many areas. Consequently, the DNN model has become a valuable asset, and its intellectual property is safeguarded by ownership verification techniques (e.g., DNN fingerprinting). However, the feasibility of the DNN fingerprint removal attack and its potential influence remains an open problem. In this paper, we perform the first comprehensive investigation of DNN fingerprint removal attacks. Generally, the knowledge contained in a DNN model can be categorized into general semantic and fingerprint-specific knowledge. To this end, we propose a min-max bilevel optimization-based DNN fingerprint removal attack named RemovalNet, to evade model ownership verification. The lower-level optimization is designed to remove fingerprint-specific knowledge. While in the upper-level optimization, we distill the victim model's general semantic knowledge to maintain the surrogate model's performance. We conduct extensive experiments to evaluate the fidelity, effectiveness, and efficiency of the RemovalNet against four advanced defense methods on six metrics. The empirical results demonstrate that (1) the RemovalNet is effective. After our DNN fingerprint removal attack, the model distance between the target and surrogate models is x100 times higher than that of the baseline attacks, (2) the RemovalNet is efficient. It uses only 0.2% (400 samples) of the substitute dataset and 1,000 iterations to conduct our attack. Besides, compared with advanced model stealing attacks, the RemovalNet saves nearly 85% of computational resources at most, (3) the RemovalNet achieves high fidelity that the created surrogate model maintains high accuracy after the DNN fingerprint removal process. Our code is available at: https://github.com/grasses/RemovalNet.
Backdoor Defense via Decoupling the Training Process
Feb 05, 2022



Recent studies have revealed that deep neural networks (DNNs) are vulnerable to backdoor attacks, where attackers embed hidden backdoors in the DNN model by poisoning a few training samples. The attacked model behaves normally on benign samples, whereas its prediction will be maliciously changed when the backdoor is activated. We reveal that poisoned samples tend to cluster together in the feature space of the attacked DNN model, which is mostly due to the end-to-end supervised training paradigm. Inspired by this observation, we propose a novel backdoor defense via decoupling the original end-to-end training process into three stages. Specifically, we first learn the backbone of a DNN model via \emph{self-supervised learning} based on training samples without their labels. The learned backbone will map samples with the same ground-truth label to similar locations in the feature space. Then, we freeze the parameters of the learned backbone and train the remaining fully connected layers via standard training with all (labeled) training samples. Lastly, to further alleviate side-effects of poisoned samples in the second stage, we remove labels of some `low-credible' samples determined based on the learned model and conduct a \emph{semi-supervised fine-tuning} of the whole model. Extensive experiments on multiple benchmark datasets and DNN models verify that the proposed defense is effective in reducing backdoor threats while preserving high accuracy in predicting benign samples. Our code is available at \url{https://github.com/SCLBD/DBD}.