 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrandFusion: A Multi-Agent Framework for Seamless Brand Integration in Text-to-Video Generation
Mar 03, 2026The rapid advancement of text-to-video (T2V) models has revolutionized content creation, yet their commercial potential remains largely untapped. We introduce, for the first time, the task of seamless brand integration in T2V: automatically embedding advertiser brands into prompt-generated videos while preserving semantic fidelity to user intent. This task confronts three core challenges: maintaining prompt fidelity, ensuring brand recognizability, and achieving contextually natural integration. To address them, we propose BrandFusion, a novel multi-agent framework comprising two synergistic phases. In the offline phase (advertiser-facing), we construct a Brand Knowledge Base by probing model priors and adapting to novel brands via lightweight fine-tuning. In the online phase (user-facing), five agents jointly refine user prompts through iterative refinement, leveraging the shared knowledge base and real-time contextual tracking to ensure brand visibility and semantic alignment. Experiments on 18 established and 2 custom brands across multiple state-of-the-art T2V models demonstrate that BrandFusion significantly outperforms baselines in semantic preservation, brand recognizability, and integration naturalness. Human evaluations further confirm higher user satisfaction, establishing a practical pathway for sustainable T2V monetization.
Unveiling Covert Toxicity in Multimodal Data via Toxicity Association Graphs: A Graph-Based Metric and Interpretable Detection Framework
Feb 03, 2026Detecting toxicity in multimodal data remains a significant challenge, as harmful meanings often lurk beneath seemingly benign individual modalities: only emerging when modalities are combined and semantic associations are activated. To address this, we propose a novel detection framework based on Toxicity Association Graphs (TAGs), which systematically model semantic associations between innocuous entities and latent toxic implications. Leveraging TAGs, we introduce the first quantifiable metric for hidden toxicity, the Multimodal Toxicity Covertness (MTC), which measures the degree of concealment in toxic multimodal expressions. By integrating our detection framework with the MTC metric, our approach enables precise identification of covert toxicity while preserving full interpretability of the decision-making process, significantly enhancing transparency in multimodal toxicity detection. To validate our method, we construct the Covert Toxic Dataset, the first benchmark specifically designed to capture high-covertness toxic multimodal instances. This dataset encodes nuanced cross-modal associations and serves as a rigorous testbed for evaluating both the proposed metric and detection framework. Extensive experiments demonstrate that our approach outperforms existing methods across both low- and high-covertness toxicity regimes, while delivering clear, interpretable, and auditable detection outcomes. Together, our contributions advance the state of the art in explainable multimodal toxicity detection and lay the foundation for future context-aware and interpretable approaches. Content Warning: This paper contains examples of toxic multimodal content that may be offensive or disturbing to some readers. Reader discretion is advised.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
Aug 06, 2025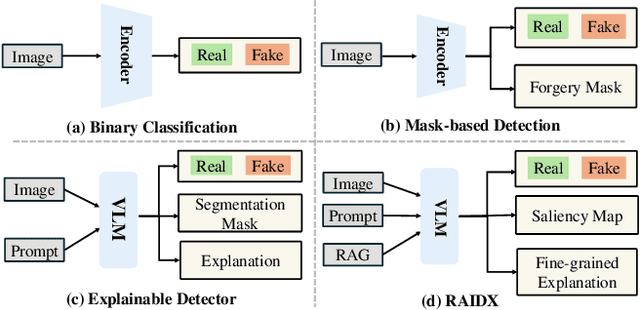
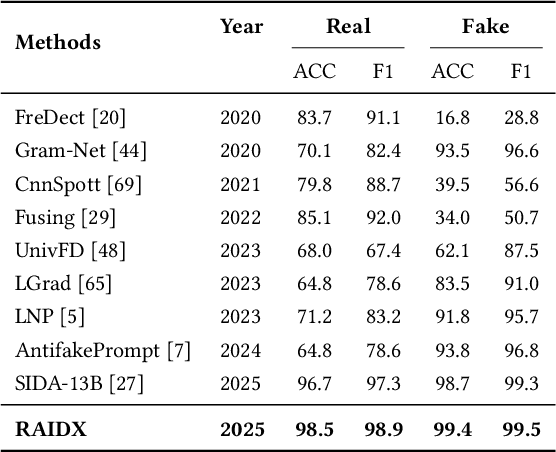
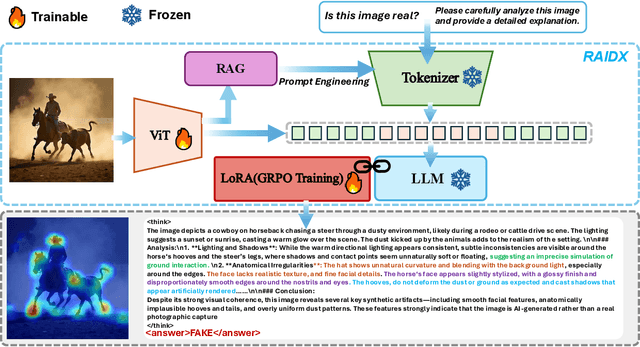
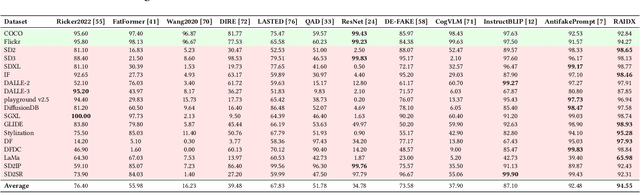
The rapid advancement of AI-generation models has enabled the creation of hyperrealistic imagery, posing ethical risks through widespread misinformation. Current deepfake detection methods, categorized as face specific detectors or general AI-generated detectors, lack transparency by framing detection as a classification task without explaining decisions. While several LLM-based approaches offer explainability, they suffer from coarse-grained analyses and dependency on labor-intensive annotations. This paper introduces RAIDX (Retrieval-Augmented Image Deepfake Detection and Explainability), a novel deepfake detection framework integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO) to enhance detection accuracy and decision explainability. Specifically, RAIDX leverages RAG to incorporate external knowledge for improved detection accuracy and employs GRPO to autonomously generate fine-grained textual explanations and saliency maps, eliminating the need for extensive manual annotations. Experiments on multiple benchmarks demonstrate RAIDX's effectiveness in identifying real or fake, and providing interpretable rationales in both textual descriptions and saliency maps, achieving state-of-the-art detection performance while advancing transparency in deepfake identification. RAIDX represents the first unified framework to synergize RAG and GRPO, addressing critical gaps in accuracy and explainability. Our code and models will be publicly available.
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
May 19, 2025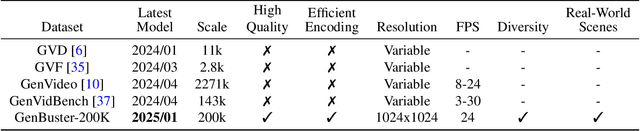
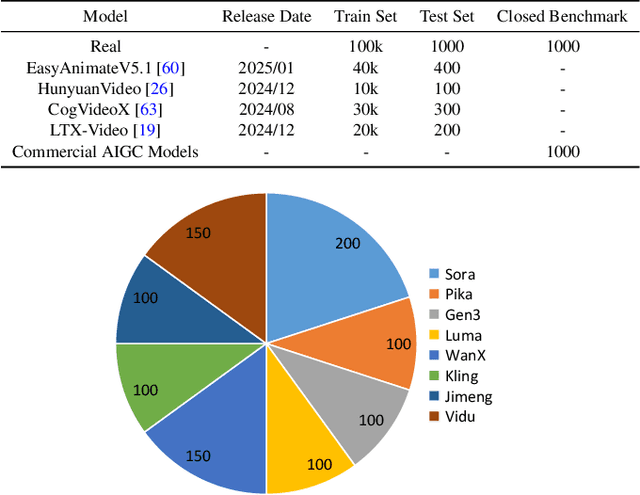
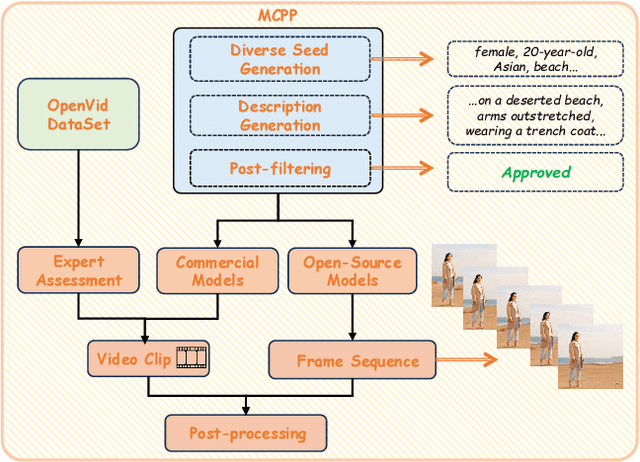
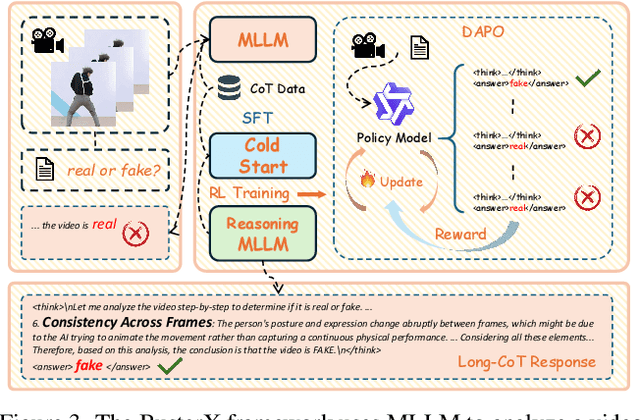
Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, and real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning for authenticity determination and explainable rationale. To our knowledge, GenBuster-200K is the {\it \textbf{first}} large-scale, high-quality AI-generated video dataset that incorporates the latest generative techniques for real-world scenarios. BusterX is the {\it \textbf{first}} framework to integrate MLLM with reinforcement learning for explainable AI-generated video detection. Extensive comparisons with state-of-the-art methods and ablation studies validate the effectiveness and generalizability of BusterX. The code, models, and datasets will be released.
FauForensics: Boosting Audio-Visual Deepfake Detection with Facial Action Units
May 13, 2025The rapid evolution of generative AI has increased the threat of realistic audio-visual deepfakes, demanding robust detection methods. Existing solutions primarily address unimodal (audio or visual) forgeries but struggle with multimodal manipulations due to inadequate handling of heterogeneous modality features and poor generalization across datasets. To this end, we propose a novel framework called FauForensics by introducing biologically invariant facial action units (FAUs), which is a quantitative descriptor of facial muscle activity linked to emotion physiology. It serves as forgery-resistant representations that reduce domain dependency while capturing subtle dynamics often disrupted in synthetic content. Besides, instead of comparing entire video clips as in prior works, our method computes fine-grained frame-wise audiovisual similarities via a dedicated fusion module augmented with learnable cross-modal queries. It dynamically aligns temporal-spatial lip-audio relationships while mitigating multi-modal feature heterogeneity issues. Experiments on FakeAVCeleb and LAV-DF show state-of-the-art (SOTA) performance and superior cross-dataset generalizability with up to an average of 4.83\% than existing methods.
BadVideo: Stealthy Backdoor Attack against Text-to-Video Generation
Apr 23, 2025Text-to-video (T2V) generative models have rapidly advanced and found widespread applications across fields like entertainment, education, and marketing. However, the adversarial vulnerabilities of these models remain rarely explored. We observe that in T2V generation tasks, the generated videos often contain substantial redundant information not explicitly specified in the text prompts, such as environmental elements, secondary objects, and additional details, providing opportunities for malicious attackers to embed hidden harmful content. Exploiting this inherent redundancy, we introduce BadVideo, the first backdoor attack framework tailored for T2V generation. Our attack focuses on designing target adversarial outputs through two key strategies: (1) Spatio-Temporal Composition, which combines different spatiotemporal features to encode malicious information; (2) Dynamic Element Transformation, which introduces transformations in redundant elements over time to convey malicious information. Based on these strategies, the attacker's malicious target seamlessly integrates with the user's textual instructions, providing high stealthiness. Moreover, by exploiting the temporal dimension of videos, our attack successfully evades traditional content moderation systems that primarily analyze spatial information within individual frames. Extensive experiments demonstrate that BadVideo achieves high attack success rates while preserving original semantics and maintaining excellent performance on clean inputs. Overall, our work reveals the adversarial vulnerability of T2V models, calling attention to potential risks and misuse. Our project page is at https://wrt2000.github.io/BadVideo2025/.
Seeking Flat Minima over Diverse Surrogates for Improved Adversarial Transferability: A Theoretical Framework and Algorithmic Instantiation
Apr 23, 2025



The transfer-based black-box adversarial attack setting poses the challenge of crafting an adversarial example (AE) on known surrogate models that remain effective against unseen target models. Due to the practical importance of this task, numerous methods have been proposed to address this challenge. However, most previous methods are heuristically designed and intuitively justified, lacking a theoretical foundation. To bridge this gap, we derive a novel transferability bound that offers provable guarantees for adversarial transferability. Our theoretical analysis has the advantages of \textit{(i)} deepening our understanding of previous methods by building a general attack framework and \textit{(ii)} providing guidance for designing an effective attack algorithm. Our theoretical results demonstrate that optimizing AEs toward flat minima over the surrogate model set, while controlling the surrogate-target model shift measured by the adversarial model discrepancy, yields a comprehensive guarantee for AE transferability. The results further lead to a general transfer-based attack framework, within which we observe that previous methods consider only partial factors contributing to the transferability. Algorithmically, inspired by our theoretical results, we first elaborately construct the surrogate model set in which models exhibit diverse adversarial vulnerabilities with respect to AEs to narrow an instantiated adversarial model discrepancy. Then, a \textit{model-Diversity-compatible Reverse Adversarial Perturbation} (DRAP) is generated to effectively promote the flatness of AEs over diverse surrogate models to improve transferability. Extensive experiments on NIPS2017 and CIFAR-10 datasets against various target models demonstrate the effectiveness of our proposed attack.
Class-Conditional Neural Polarizer: A Lightweight and Effective Backdoor Defense by Purifying Poisoned Features
Feb 23, 2025Recent studies have highlighted the vulnerability of deep neural networks to backdoor attacks, where models are manipulated to rely on embedded triggers within poisoned samples, despite the presence of both benign and trigger information. While several defense methods have been proposed, they often struggle to balance backdoor mitigation with maintaining benign performance.In this work, inspired by the concept of optical polarizer-which allows light waves of specific polarizations to pass while filtering others-we propose a lightweight backdoor defense approach, NPD. This method integrates a neural polarizer (NP) as an intermediate layer within the compromised model, implemented as a lightweight linear transformation optimized via bi-level optimization. The learnable NP filters trigger information from poisoned samples while preserving benign content. Despite its effectiveness, we identify through empirical studies that NPD's performance degrades when the target labels (required for purification) are inaccurately estimated. To address this limitation while harnessing the potential of targeted adversarial mitigation, we propose class-conditional neural polarizer-based defense (CNPD). The key innovation is a fusion module that integrates the backdoored model's predicted label with the features to be purified. This architecture inherently mimics targeted adversarial defense mechanisms without requiring label estimation used in NPD. We propose three implementations of CNPD: the first is r-CNPD, which trains a replicated NP layer for each class and, during inference, selects the appropriate NP layer for defense based on the predicted class from the backdoored model. To efficiently handle a large number of classes, two variants are designed: e-CNPD, which embeds class information as additional features, and a-CNPD, which directs network attention using class information.
Reliable Imputed-Sample Assisted Vertical Federated Learning
Jan 11, 2025Vertical Federated Learning (VFL) is a well-known FL variant that enables multiple parties to collaboratively train a model without sharing their raw data. Existing VFL approaches focus on overlapping samples among different parties, while their performance is constrained by the limited number of these samples, leaving numerous non-overlapping samples unexplored. Some previous work has explored techniques for imputing missing values in samples, but often without adequate attention to the quality of the imputed samples. To address this issue, we propose a Reliable Imputed-Sample Assisted (RISA) VFL framework to effectively exploit non-overlapping samples by selecting reliable imputed samples for training VFL models. Specifically, after imputing non-overlapping samples, we introduce evidence theory to estimate the uncertainty of imputed samples, and only samples with low uncertainty are selected. In this way, high-quality non-overlapping samples are utilized to improve VFL model. Experiments on two widely used datasets demonstrate the significant performance gains achieved by the RISA, especially with the limited overlapping samples, e.g., a 48% accuracy gain on CIFAR-10 with only 1% overlapping samples.