 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMGIE: Hierarchical and Multi-Grained Inconsistency Evaluation for Vision-Language Data Cleansing
Dec 07, 2024Visual-textual inconsistency (VTI) evaluation plays a crucial role in cleansing vision-language data. Its main challenges stem from the high variety of image captioning datasets, where differences in content can create a range of inconsistencies (\eg, inconsistencies in scene, entities, entity attributes, entity numbers, entity interactions). Moreover, variations in caption length can introduce inconsistencies at different levels of granularity as well. To tackle these challenges, we design an adaptive evaluation framework, called Hierarchical and Multi-Grained Inconsistency Evaluation (HMGIE), which can provide multi-grained evaluations covering both accuracy and completeness for various image-caption pairs. Specifically, the HMGIE framework is implemented by three consecutive modules. Firstly, the semantic graph generation module converts the image caption to a semantic graph for building a structural representation of all involved semantic items. Then, the hierarchical inconsistency evaluation module provides a progressive evaluation procedure with a dynamic question-answer generation and evaluation strategy guided by the semantic graph, producing a hierarchical inconsistency evaluation graph (HIEG). Finally, the quantitative evaluation module calculates the accuracy and completeness scores based on the HIEG, followed by a natural language explanation about the detection results. Moreover, to verify the efficacy and flexibility of the proposed framework on handling different image captioning datasets, we construct MVTID, an image-caption dataset with diverse types and granularities of inconsistencies. Extensive experiments on MVTID and other benchmark datasets demonstrate the superior performance of the proposed HMGIE to current state-of-the-art methods.
Missing Value Imputation Based on Deep Generative Models
Aug 05, 2018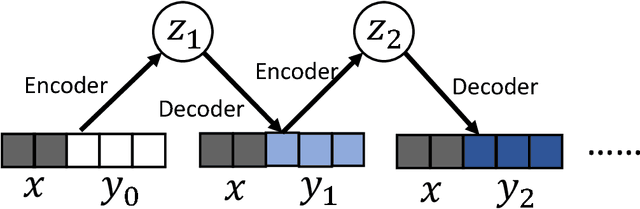
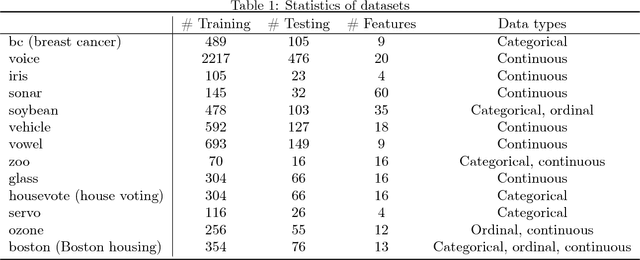
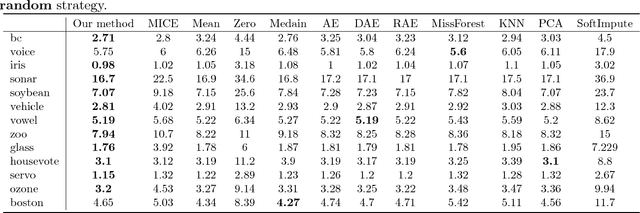
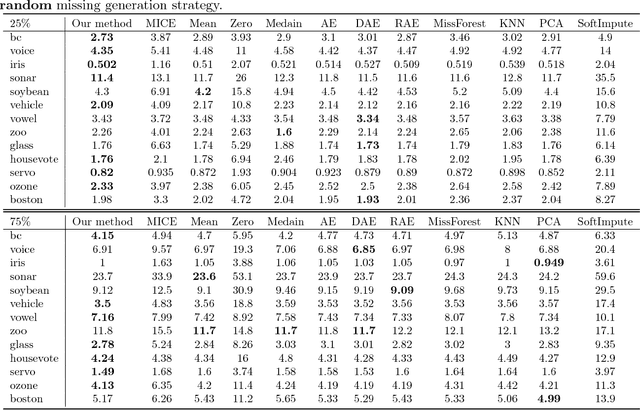
Missing values widely exist in many real-world datasets, which hinders the performing of advanced data analytics. Properly filling these missing values is crucial but challenging, especially when the missing rate is high. Many approaches have been proposed for missing value imputation (MVI), but they are mostly heuristics-based, lacking a principled foundation and do not perform satisfactorily in practice. In this paper, we propose a probabilistic framework based on deep generative models for MVI. Under this framework, imputing the missing entries amounts to seeking a fixed-point solution between two conditional distributions defined on the missing entries and latent variables respectively. These distributions are parameterized by deep neural networks (DNNs) which possess high approximation power and can capture the nonlinear relationships between missing entries and the observed values. The learning of weight parameters of DNNs is performed by maximizing an approximation of the log-likelihood of observed values. We conducted extensive evaluation on 13 datasets and compared with 11 baselines methods, where our methods largely outperforms the baselines.
Predicting Discharge Medications at Admission Time Based on Deep Learning
Dec 05, 2017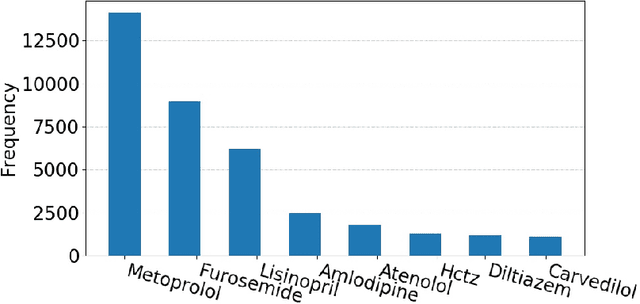

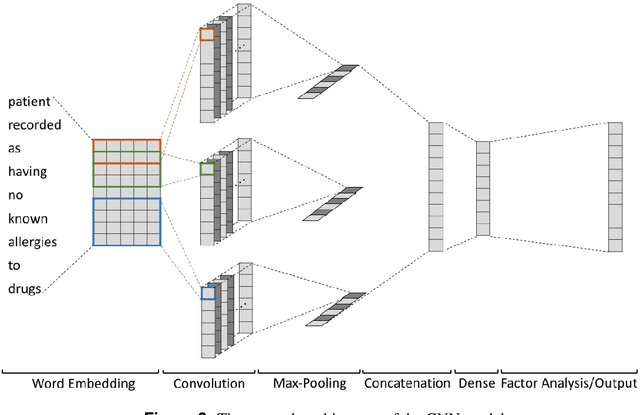
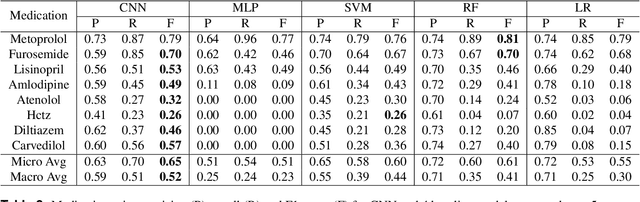
Predicting discharge medications right after a patient being admitted is an important clinical decision, which provides physicians with guidance on what type of medication regimen to plan for and what possible changes on initial medication may occur during an inpatient stay. It also facilitates medication reconciliation process with easy detection of medication discrepancy at discharge time to improve patient safety. However, since the information available upon admission is limited and patients' condition may evolve during an inpatient stay, these predictions could be a difficult decision for physicians to make. In this work, we investigate how to leverage deep learning technologies to assist physicians in predicting discharge medications based on information documented in the admission note. We build a convolutional neural network which takes an admission note as input and predicts the medications placed on the patient at discharge time. Our method is able to distill semantic patterns from unstructured and noisy texts, and is capable of capturing the pharmacological correlations among medications. We evaluate our method on 25K patient visits and compare with 4 strong baselines. Our methods demonstrate a 20% increase in macro-averaged F1 score than the best baseline.
Learning Less-Overlapping Representations
Nov 25, 2017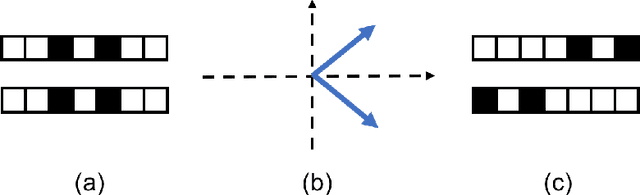
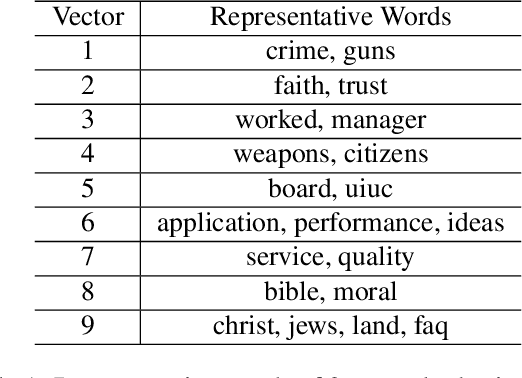
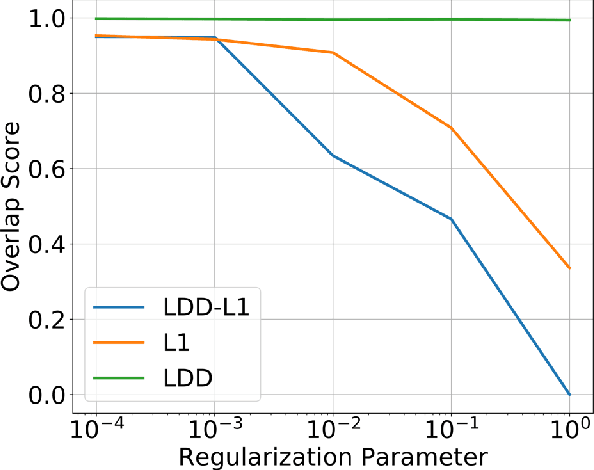
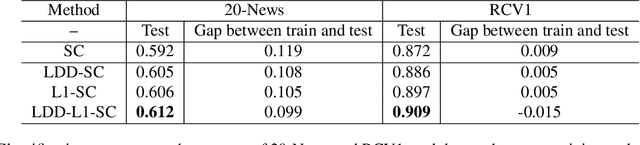
In representation learning (RL), how to make the learned representations easy to interpret and less overfitted to training data are two important but challenging issues. To address these problems, we study a new type of regulariza- tion approach that encourages the supports of weight vectors in RL models to have small overlap, by simultaneously promoting near-orthogonality among vectors and sparsity of each vector. We apply the proposed regularizer to two models: neural networks (NNs) and sparse coding (SC), and develop an efficient ADMM-based algorithm for regu- larized SC. Experiments on various datasets demonstrate that weight vectors learned under our regularizer are more interpretable and have better generalization performance.