 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4KLSDB: A Large-Scale Dataset for 4K Image Restoration and Generation
May 23, 2026High-resolution datasets are essential for advancing super-resolution (SR) and text-to-image (T2I) diffusion research. However, current publicly available datasets lack both the native 4K resolution and the extensive scale necessary for training state-of-the-art models. To address this gap, we introduce a 4K Large Scale Dataset and Benchmark (4KLSDB), a large-scale, diverse dataset consisting of 129,484 carefully curated 4K resolution images spanning multiple categories such as nature, urban scenes, people, food, artwork, and CGI, alongside distinct validation and test sets containing 2,000 and 1,984 images respectively. Images were sourced from established open datasets including Photo Concept Bucket, Laion2B, and PD12M. 4KLSDB underwent rigorous multi-stage automated filtering and annotation pipelines involving both human annotators and Large Multimodal Models (LMMs) to ensure high aesthetic quality and dataset consistency. We demonstrate 4KLSDB's effectiveness by training representative super-resolution and diffusion models, observing significant improvements in performance on native 4K benchmarks. Comprehensive experiments illustrate a positive correlation between training on true 4K resolution data and improved fidelity in image restoration task, especially on 4K resolution. We provide the research community a valuable resource to drive progress toward genuinely high-fidelity image synthesis and restoration by providing 4KLSDB. Our project page is available at: https://4klsdb.github.io/.
Trust It or Not: Evidential Uncertainty for Feed-Forward 3D Reconstruction with Trust3R
May 19, 2026Geometric foundation models hold promise for unconstrained dense geometry prediction from uncalibrated images. However, in current feed-forward designs, their predicted confidence scores are heuristic, lack probabilistic interpretation, and often fail to indicate where and how much the predicted geometry can be trusted. To address this gap, we present Trust3R, a lightweight evidential uncertainty framework for feed-forward 3D reconstruction. Trust3R combines gated residual mean refinement with a Normal-Inverse-Wishart evidential head, yielding a closed-form multivariate Student-t distribution for per-point geometric uncertainty. This design provides probabilistically grounded pointmap uncertainty estimates while adding moderate inference overhead. We evaluate on diverse indoor and outdoor benchmarks and compare against MASt3R's built-in confidence map as well as common uncertainty-aware baselines spanning single-pass heteroscedastic regression and sampling-based methods such as MC dropout and deep ensembles. Experimental results show that Trust3R consistently improves risk-coverage and sparsification, and generally improves geometric accuracy. These gains are reflected in stronger uncertainty ranking across benchmarks, with 25% lower AURC and 41% lower AUSE on ScanNet++, providing a practical reliability signal for uncertainty-aware weighting in downstream geometry pipelines. The project page and code are available at https://trust3r-z.github.io/.
How Independent are Large Language Models? A Statistical Framework for Auditing Behavioral Entanglement and Reweighting Verifier Ensembles
Apr 08, 2026The rapid growth of the large language model (LLM) ecosystem raises a critical question: are seemingly diverse models truly independent? Shared pretraining data, distillation, and alignment pipelines can induce hidden behavioral dependencies, latent entanglement, that undermine multi-model systems such as LLM-as-a-judge pipelines and ensemble verification, which implicitly assume independent signals. In practice, this manifests as correlated reasoning patterns and synchronized failures, where apparent agreement reflects shared error modes rather than independent validation. To address this, we develop a statistical framework for auditing behavioral entanglement among black-box LLMs. Our approach introduces a multi-resolution hierarchy that characterizes the joint failure manifold through two information-theoretic metrics: (i) a Difficulty-Weighted Behavioral Entanglement Index, which amplifies synchronized failures on easy tasks, and (ii) a Cumulative Information Gain (CIG) metric, which captures directional alignment in erroneous responses. Through extensive experiments on 18 LLMs from six model families, we identify widespread behavioral entanglement and analyze its impact on LLM-as-a-judge evaluation. We find that CIG exhibits a statistically significant association with degradation in judge precision, with Spearman coefficient of 0.64 (p < 0.001) for GPT-4o-mini and 0.71 (p < 0.01) for Llama3-based judges, indicating that stronger dependency corresponds to increased over-endorsement bias. Finally, we demonstrate a practical use case of entanglement through de-entangled verifier ensemble reweighting. By adjusting model contributions based on inferred independence, the proposed method mitigates correlated bias and improves verification performance, achieving up to a 4.5% accuracy gain over majority voting.
BrandFusion: A Multi-Agent Framework for Seamless Brand Integration in Text-to-Video Generation
Mar 03, 2026The rapid advancement of text-to-video (T2V) models has revolutionized content creation, yet their commercial potential remains largely untapped. We introduce, for the first time, the task of seamless brand integration in T2V: automatically embedding advertiser brands into prompt-generated videos while preserving semantic fidelity to user intent. This task confronts three core challenges: maintaining prompt fidelity, ensuring brand recognizability, and achieving contextually natural integration. To address them, we propose BrandFusion, a novel multi-agent framework comprising two synergistic phases. In the offline phase (advertiser-facing), we construct a Brand Knowledge Base by probing model priors and adapting to novel brands via lightweight fine-tuning. In the online phase (user-facing), five agents jointly refine user prompts through iterative refinement, leveraging the shared knowledge base and real-time contextual tracking to ensure brand visibility and semantic alignment. Experiments on 18 established and 2 custom brands across multiple state-of-the-art T2V models demonstrate that BrandFusion significantly outperforms baselines in semantic preservation, brand recognizability, and integration naturalness. Human evaluations further confirm higher user satisfaction, establishing a practical pathway for sustainable T2V monetization.
Towards Reliable Social A/B Testing: Spillover-Contained Clustering with Robust Post-Experiment Analysis
Feb 09, 2026A/B testing is the foundation of decision-making in online platforms, yet social products often suffer from network interference: user interactions cause treatment effects to spill over into the control group. Such spillovers bias causal estimates and undermine experimental conclusions. Existing approaches face key limitations: user-level randomization ignores network structure, while cluster-based methods often rely on general-purpose clustering that is not tailored for spillover containment and has difficulty balancing unbiasedness and statistical power at scale. We propose a spillover-contained experimentation framework with two stages. In the pre-experiment stage, we build social interaction graphs and introduce a Balanced Louvain algorithm that produces stable, size-balanced clusters while minimizing cross-cluster edges, enabling reliable cluster-based randomization. In the post-experiment stage, we develop a tailored CUPAC estimator that leverages pre-experiment behavioral covariates to reduce the variance induced by cluster-level assignment, thereby improving statistical power. Together, these components provide both structural spillover containment and robust statistical inference. We validate our approach through large-scale social sharing experiments on Kuaishou, a platform serving hundreds of millions of users. Results show that our method substantially reduces spillover and yields more accurate assessments of social strategies than traditional user-level designs, establishing a reliable and scalable framework for networked A/B testing.
Agent Banana: High-Fidelity Image Editing with Agentic Thinking and Tooling
Feb 09, 2026We study instruction-based image editing under professional workflows and identify three persistent challenges: (i) editors often over-edit, modifying content beyond the user's intent; (ii) existing models are largely single-turn, while multi-turn edits can alter object faithfulness; and (iii) evaluation at around 1K resolution is misaligned with real workflows that often operate on ultra high-definition images (e.g., 4K). We propose Agent Banana, a hierarchical agentic planner-executor framework for high-fidelity, object-aware, deliberative editing. Agent Banana introduces two key mechanisms: (1) Context Folding, which compresses long interaction histories into structured memory for stable long-horizon control; and (2) Image Layer Decomposition, which performs localized layer-based edits to preserve non-target regions while enabling native-resolution outputs. To support rigorous evaluation, we build HDD-Bench, a high-definition, dialogue-based benchmark featuring verifiable stepwise targets and native 4K images (11.8M pixels) for diagnosing long-horizon failures. On HDD-Bench, Agent Banana achieves the best multi-turn consistency and background fidelity (e.g., IC 0.871, SSIM-OM 0.84, LPIPS-OM 0.12) while remaining competitive on instruction following, and also attains strong performance on standard single-turn editing benchmarks. We hope this work advances reliable, professional-grade agentic image editing and its integration into real workflows.
Unveiling Covert Toxicity in Multimodal Data via Toxicity Association Graphs: A Graph-Based Metric and Interpretable Detection Framework
Feb 03, 2026Detecting toxicity in multimodal data remains a significant challenge, as harmful meanings often lurk beneath seemingly benign individual modalities: only emerging when modalities are combined and semantic associations are activated. To address this, we propose a novel detection framework based on Toxicity Association Graphs (TAGs), which systematically model semantic associations between innocuous entities and latent toxic implications. Leveraging TAGs, we introduce the first quantifiable metric for hidden toxicity, the Multimodal Toxicity Covertness (MTC), which measures the degree of concealment in toxic multimodal expressions. By integrating our detection framework with the MTC metric, our approach enables precise identification of covert toxicity while preserving full interpretability of the decision-making process, significantly enhancing transparency in multimodal toxicity detection. To validate our method, we construct the Covert Toxic Dataset, the first benchmark specifically designed to capture high-covertness toxic multimodal instances. This dataset encodes nuanced cross-modal associations and serves as a rigorous testbed for evaluating both the proposed metric and detection framework. Extensive experiments demonstrate that our approach outperforms existing methods across both low- and high-covertness toxicity regimes, while delivering clear, interpretable, and auditable detection outcomes. Together, our contributions advance the state of the art in explainable multimodal toxicity detection and lay the foundation for future context-aware and interpretable approaches. Content Warning: This paper contains examples of toxic multimodal content that may be offensive or disturbing to some readers. Reader discretion is advised.
SCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025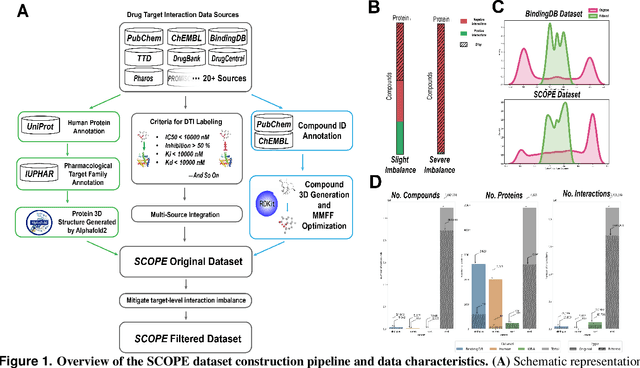
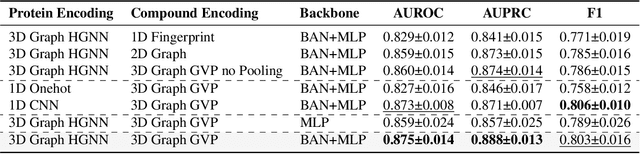
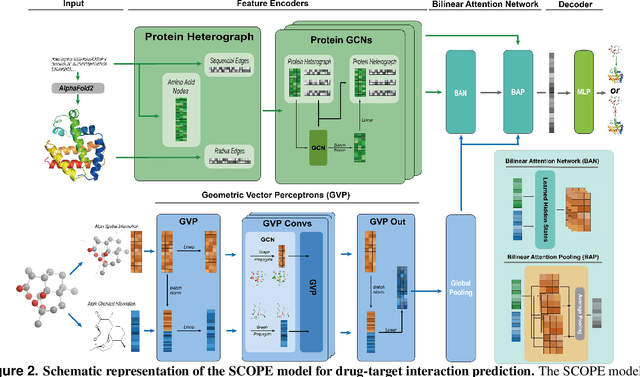
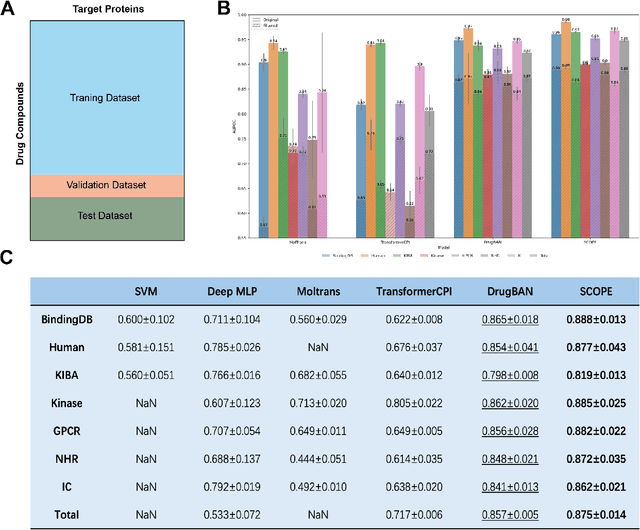
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.
AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features
Jan 07, 2025



Monocular 3D object detection is a challenging task in autonomous systems due to the lack of explicit depth information in single-view images. Existing methods often depend on external depth estimators or expensive sensors, which increase computational complexity and hinder real-time performance. To overcome these limitations, we propose AuxDepthNet, an efficient framework for real-time monocular 3D object detection that eliminates the reliance on external depth maps or pre-trained depth models. AuxDepthNet introduces two key components: the Auxiliary Depth Feature (ADF) module, which implicitly learns depth-sensitive features to improve spatial reasoning and computational efficiency, and the Depth Position Mapping (DPM) module, which embeds depth positional information directly into the detection process to enable accurate object localization and 3D bounding box regression. Leveraging the DepthFusion Transformer architecture, AuxDepthNet globally integrates visual and depth-sensitive features through depth-guided interactions, ensuring robust and efficient detection. Extensive experiments on the KITTI dataset show that AuxDepthNet achieves state-of-the-art performance, with $\text{AP}_{3D}$ scores of 24.72\% (Easy), 18.63\% (Moderate), and 15.31\% (Hard), and $\text{AP}_{\text{BEV}}$ scores of 34.11\% (Easy), 25.18\% (Moderate), and 21.90\% (Hard) at an IoU threshold of 0.7.
HMGIE: Hierarchical and Multi-Grained Inconsistency Evaluation for Vision-Language Data Cleansing
Dec 07, 2024Visual-textual inconsistency (VTI) evaluation plays a crucial role in cleansing vision-language data. Its main challenges stem from the high variety of image captioning datasets, where differences in content can create a range of inconsistencies (\eg, inconsistencies in scene, entities, entity attributes, entity numbers, entity interactions). Moreover, variations in caption length can introduce inconsistencies at different levels of granularity as well. To tackle these challenges, we design an adaptive evaluation framework, called Hierarchical and Multi-Grained Inconsistency Evaluation (HMGIE), which can provide multi-grained evaluations covering both accuracy and completeness for various image-caption pairs. Specifically, the HMGIE framework is implemented by three consecutive modules. Firstly, the semantic graph generation module converts the image caption to a semantic graph for building a structural representation of all involved semantic items. Then, the hierarchical inconsistency evaluation module provides a progressive evaluation procedure with a dynamic question-answer generation and evaluation strategy guided by the semantic graph, producing a hierarchical inconsistency evaluation graph (HIEG). Finally, the quantitative evaluation module calculates the accuracy and completeness scores based on the HIEG, followed by a natural language explanation about the detection results. Moreover, to verify the efficacy and flexibility of the proposed framework on handling different image captioning datasets, we construct MVTID, an image-caption dataset with diverse types and granularities of inconsistencies. Extensive experiments on MVTID and other benchmark datasets demonstrate the superior performance of the proposed HMGIE to current state-of-the-art methods.