 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025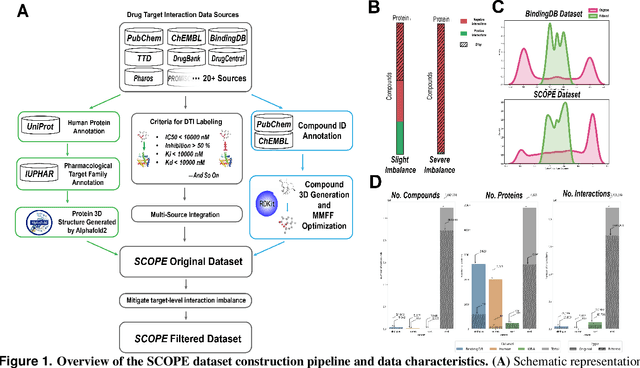
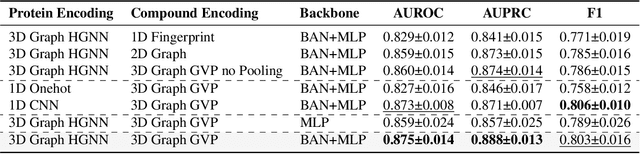
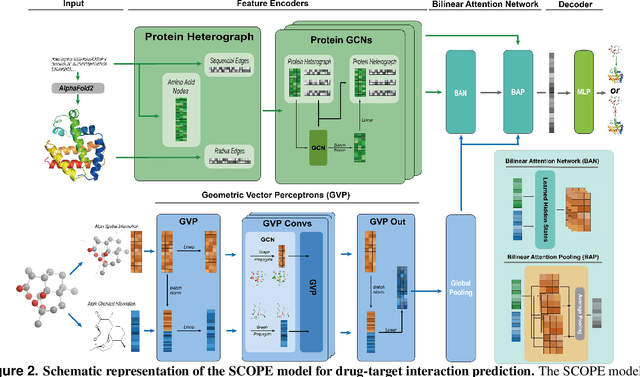
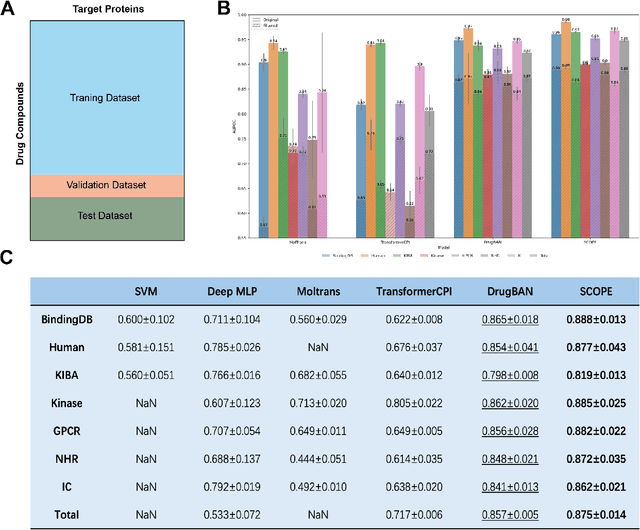
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.
Measuring Discrimination to Boost Comparative Testing for Multiple Deep Learning Models
Mar 09, 2021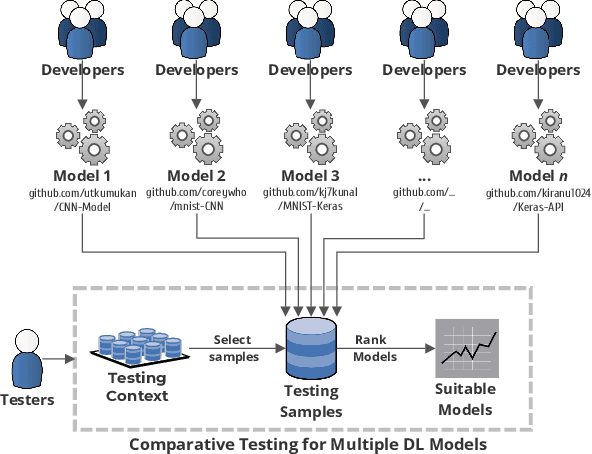
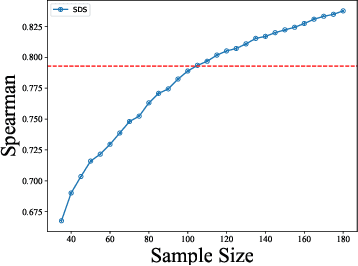
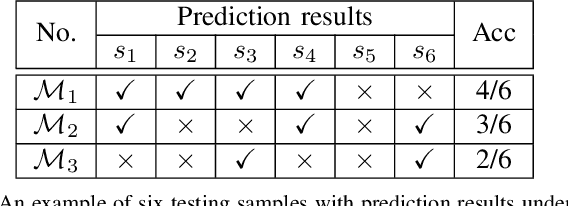
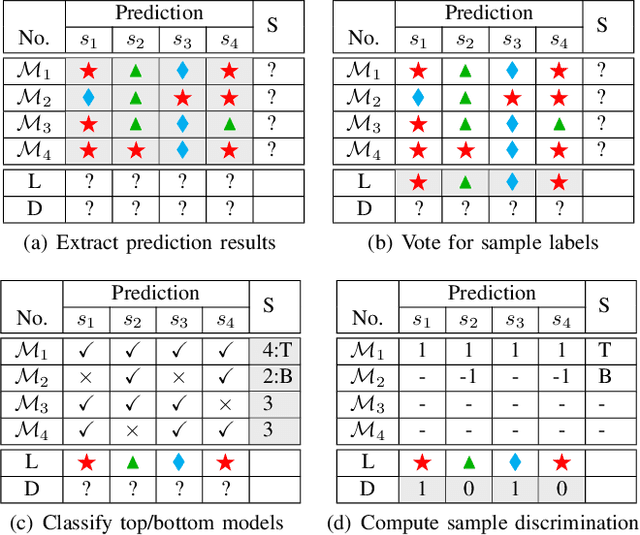
The boom of DL technology leads to massive DL models built and shared, which facilitates the acquisition and reuse of DL models. For a given task, we encounter multiple DL models available with the same functionality, which are considered as candidates to achieve this task. Testers are expected to compare multiple DL models and select the more suitable ones w.r.t. the whole testing context. Due to the limitation of labeling effort, testers aim to select an efficient subset of samples to make an as precise rank estimation as possible for these models. To tackle this problem, we propose Sample Discrimination based Selection (SDS) to select efficient samples that could discriminate multiple models, i.e., the prediction behaviors (right/wrong) of these samples would be helpful to indicate the trend of model performance. To evaluate SDS, we conduct an extensive empirical study with three widely-used image datasets and 80 real world DL models. The experimental results show that, compared with state-of-the-art baseline methods, SDS is an effective and efficient sample selection method to rank multiple DL models.
Connecting Software Metrics across Versions to Predict Defects
Dec 28, 2017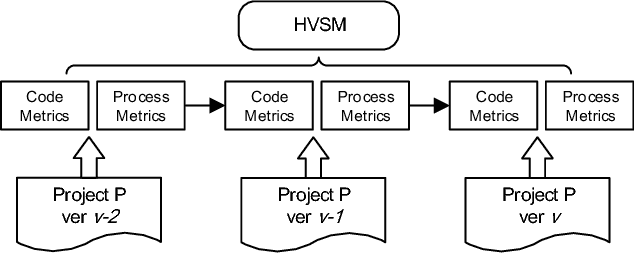
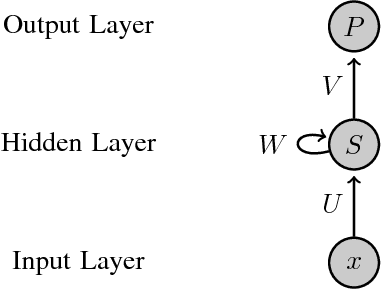
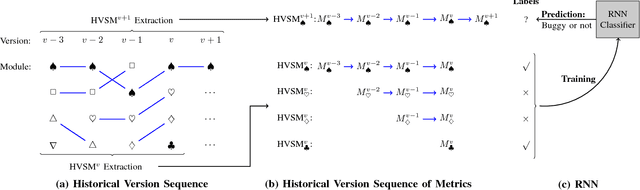
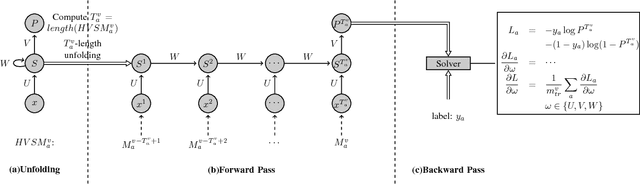
Accurate software defect prediction could help software practitioners allocate test resources to defect-prone modules effectively and efficiently. In the last decades, much effort has been devoted to build accurate defect prediction models, including developing quality defect predictors and modeling techniques. However, current widely used defect predictors such as code metrics and process metrics could not well describe how software modules change over the project evolution, which we believe is important for defect prediction. In order to deal with this problem, in this paper, we propose to use the Historical Version Sequence of Metrics (HVSM) in continuous software versions as defect predictors. Furthermore, we leverage Recurrent Neural Network (RNN), a popular modeling technique, to take HVSM as the input to build software prediction models. The experimental results show that, in most cases, the proposed HVSM-based RNN model has a significantly better effort-aware ranking effectiveness than the commonly used baseline models.
A Feature Subset Selection Algorithm Automatic Recommendation Method
Feb 04, 2014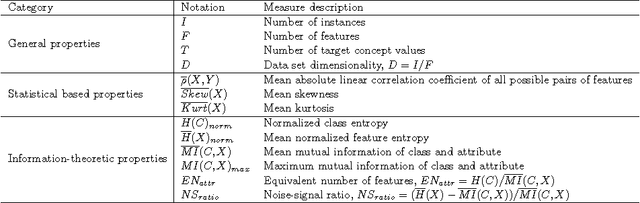
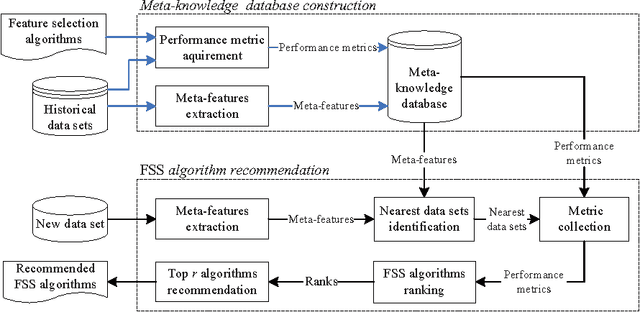
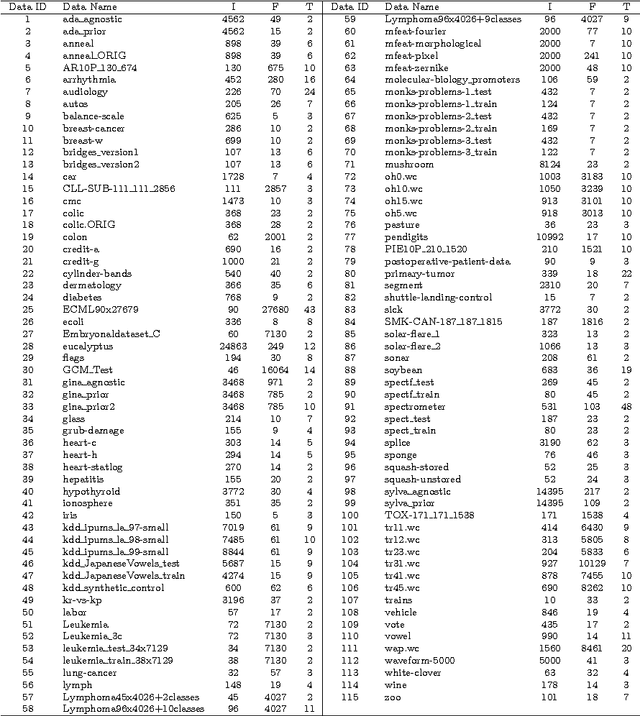
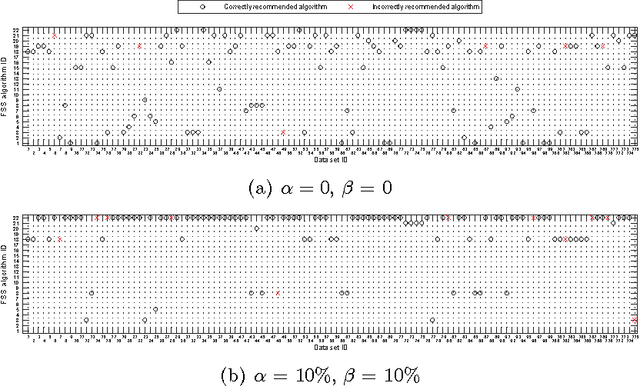
Many feature subset selection (FSS) algorithms have been proposed, but not all of them are appropriate for a given feature selection problem. At the same time, so far there is rarely a good way to choose appropriate FSS algorithms for the problem at hand. Thus, FSS algorithm automatic recommendation is very important and practically useful. In this paper, a meta learning based FSS algorithm automatic recommendation method is presented. The proposed method first identifies the data sets that are most similar to the one at hand by the k-nearest neighbor classification algorithm, and the distances among these data sets are calculated based on the commonly-used data set characteristics. Then, it ranks all the candidate FSS algorithms according to their performance on these similar data sets, and chooses the algorithms with best performance as the appropriate ones. The performance of the candidate FSS algorithms is evaluated by a multi-criteria metric that takes into account not only the classification accuracy over the selected features, but also the runtime of feature selection and the number of selected features. The proposed recommendation method is extensively tested on 115 real world data sets with 22 well-known and frequently-used different FSS algorithms for five representative classifiers. The results show the effectiveness of our proposed FSS algorithm recommendation method.