 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTs: A Dual-Path Robust Framework for Anomaly Detection in High-Dimensional Multivariate Time Series
Dec 14, 2025Multivariate time series anomaly detection (MTSAD) aims to accurately identify and localize complex abnormal patterns in the large-scale industrial control systems. While existing approaches excel in recognizing the distinct patterns under the low-dimensional scenarios, they often fail to robustly capture long-range spatiotemporal dependencies when learning representations from the high-dimensional noisy time series. To address these limitations, we propose DARTs, a robust long short-term dual-path framework with window-aware spatiotemporal soft fusion mechanism, which can be primarily decomposed into three complementary components. Specifically, in the short-term path, we introduce a Multi-View Sparse Graph Learner and a Diffusion Multi-Relation Graph Unit that collaborate to adaptively capture hierarchical discriminative short-term spatiotemporal patterns in the high-noise time series. While in the long-term path, we design a Multi-Scale Spatiotemporal Graph Constructor to model salient long-term dynamics within the high-dimensional representation space. Finally, a window-aware spatiotemporal soft-fusion mechanism is introduced to filter the residual noise while seamlessly integrating anomalous patterns. Extensive qualitative and quantitative experimental results across mainstream datasets demonstrate the superiority and robustness of our proposed DARTs. A series of ablation studies are also conducted to explore the crucial design factors of our proposed components. Our code and model will be made publicly open soon.
HOLA: Enhancing Audio-visual Deepfake Detection via Hierarchical Contextual Aggregations and Efficient Pre-training
Jul 30, 2025Advances in Generative AI have made video-level deepfake detection increasingly challenging, exposing the limitations of current detection techniques. In this paper, we present HOLA, our solution to the Video-Level Deepfake Detection track of 2025 1M-Deepfakes Detection Challenge. Inspired by the success of large-scale pre-training in the general domain, we first scale audio-visual self-supervised pre-training in the multimodal video-level deepfake detection, which leverages our self-built dataset of 1.81M samples, thereby leading to a unified two-stage framework. To be specific, HOLA features an iterative-aware cross-modal learning module for selective audio-visual interactions, hierarchical contextual modeling with gated aggregations under the local-global perspective, and a pyramid-like refiner for scale-aware cross-grained semantic enhancements. Moreover, we propose the pseudo supervised singal injection strategy to further boost model performance. Extensive experiments across expert models and MLLMs impressivly demonstrate the effectiveness of our proposed HOLA. We also conduct a series of ablation studies to explore the crucial design factors of our introduced components. Remarkably, our HOLA ranks 1st, outperforming the second by 0.0476 AUC on the TestA set.
Utilizing Large Language Models for Event Deconstruction to Enhance Multimodal Aspect-Based Sentiment Analysis
Oct 18, 2024
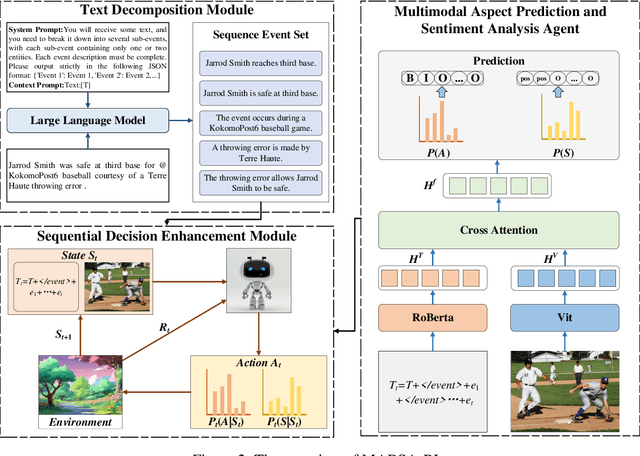
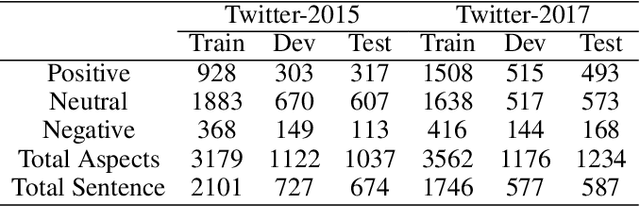

With the rapid development of the internet, the richness of User-Generated Contentcontinues to increase, making Multimodal Aspect-Based Sentiment Analysis (MABSA) a research hotspot. Existing studies have achieved certain results in MABSA, but they have not effectively addressed the analytical challenges in scenarios where multiple entities and sentiments coexist. This paper innovatively introduces Large Language Models (LLMs) for event decomposition and proposes a reinforcement learning framework for Multimodal Aspect-based Sentiment Analysis (MABSA-RL) framework. This framework decomposes the original text into a set of events using LLMs, reducing the complexity of analysis, introducing reinforcement learning to optimize model parameters. Experimental results show that MABSA-RL outperforms existing advanced methods on two benchmark datasets. This paper provides a new research perspective and method for multimodal aspect-level sentiment analysis.
eMotions: A Large-Scale Dataset for Emotion Recognition in Short Videos
Nov 29, 2023
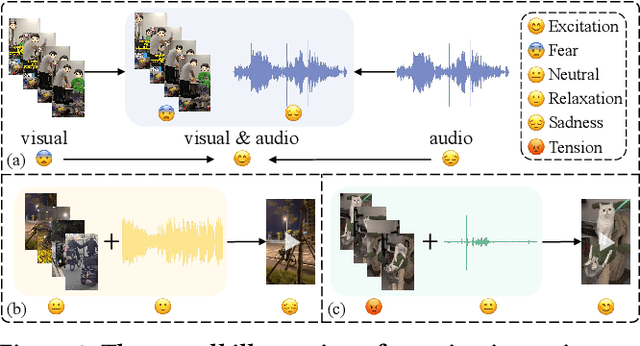
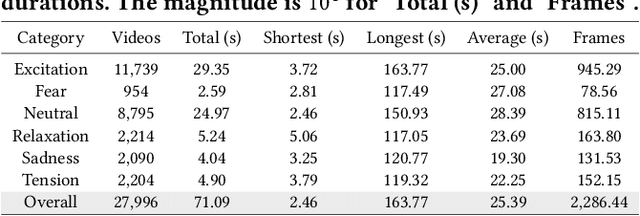
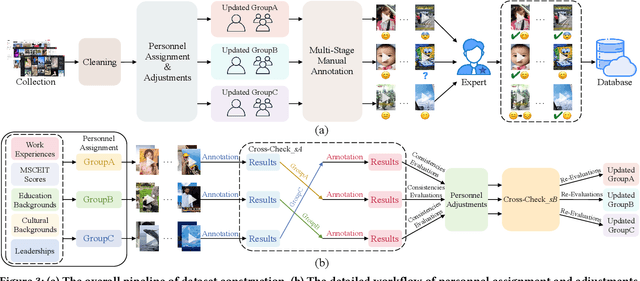
Nowadays, short videos (SVs) are essential to information acquisition and sharing in our life. The prevailing use of SVs to spread emotions leads to the necessity of emotion recognition in SVs. Considering the lack of SVs emotion data, we introduce a large-scale dataset named eMotions, comprising 27,996 videos. Meanwhile, we alleviate the impact of subjectivities on labeling quality by emphasizing better personnel allocations and multi-stage annotations. In addition, we provide the category-balanced and test-oriented variants through targeted data sampling. Some commonly used videos (e.g., facial expressions and postures) have been well studied. However, it is still challenging to understand the emotions in SVs. Since the enhanced content diversity brings more distinct semantic gaps and difficulties in learning emotion-related features, and there exists information gaps caused by the emotion incompleteness under the prevalently audio-visual co-expressions. To tackle these problems, we present an end-to-end baseline method AV-CPNet that employs the video transformer to better learn semantically relevant representations. We further design the two-stage cross-modal fusion module to complementarily model the correlations of audio-visual features. The EP-CE Loss, incorporating three emotion polarities, is then applied to guide model optimization. Extensive experimental results on nine datasets verify the effectiveness of AV-CPNet. Datasets and code will be open on https://github.com/XuecWu/eMotions.
A Feature Subset Selection Algorithm Automatic Recommendation Method
Feb 04, 2014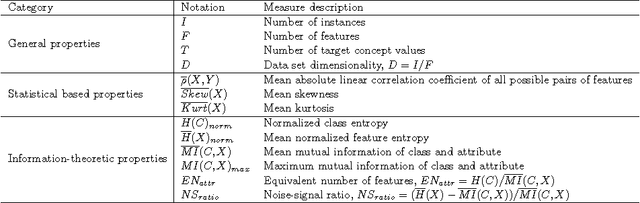
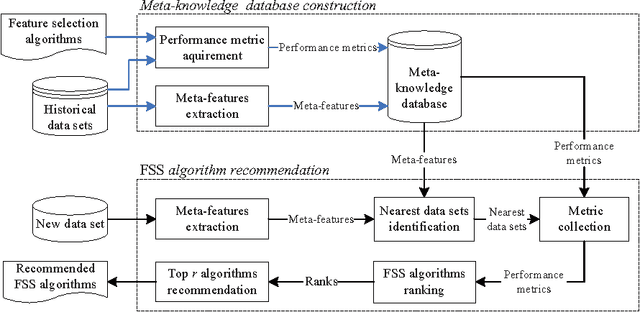
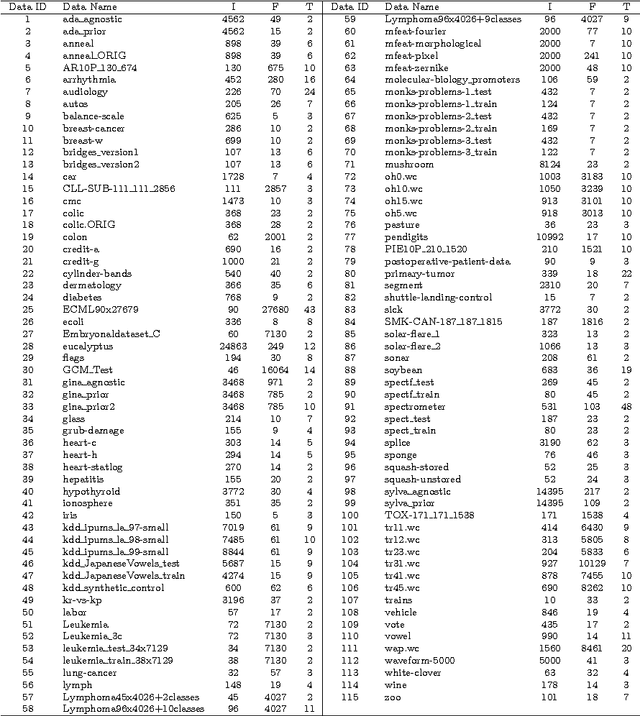
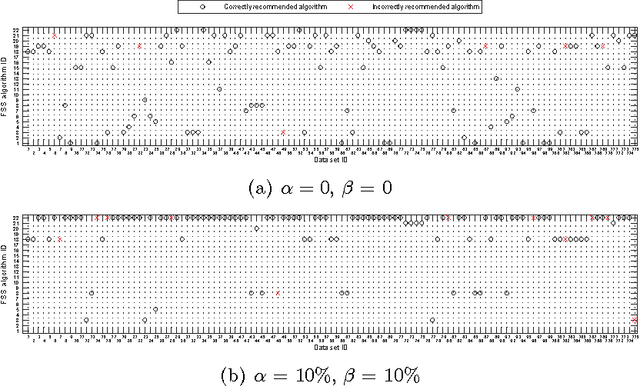
Many feature subset selection (FSS) algorithms have been proposed, but not all of them are appropriate for a given feature selection problem. At the same time, so far there is rarely a good way to choose appropriate FSS algorithms for the problem at hand. Thus, FSS algorithm automatic recommendation is very important and practically useful. In this paper, a meta learning based FSS algorithm automatic recommendation method is presented. The proposed method first identifies the data sets that are most similar to the one at hand by the k-nearest neighbor classification algorithm, and the distances among these data sets are calculated based on the commonly-used data set characteristics. Then, it ranks all the candidate FSS algorithms according to their performance on these similar data sets, and chooses the algorithms with best performance as the appropriate ones. The performance of the candidate FSS algorithms is evaluated by a multi-criteria metric that takes into account not only the classification accuracy over the selected features, but also the runtime of feature selection and the number of selected features. The proposed recommendation method is extensively tested on 115 real world data sets with 22 well-known and frequently-used different FSS algorithms for five representative classifiers. The results show the effectiveness of our proposed FSS algorithm recommendation method.