 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridINR-PCGC: Hybrid Lossless Point Cloud Geometry Compression Bridging Pretrained Model and Implicit Neural Representation
Feb 25, 2026Learning-based point cloud compression presents superior performance to handcrafted codecs. However, pretrained-based methods, which are based on end-to-end training and expected to generalize to all the potential samples, suffer from training data dependency. Implicit neural representation (INR) based methods are distribution-agnostic and more robust, but they require time-consuming online training and suffer from the bitstream overhead from the overfitted model. To address these limitations, we propose HybridINR-PCGC, a novel hybrid framework that bridges the pretrained model and INR. Our framework retains distribution-agnostic properties while leveraging a pretrained network to accelerate convergence and reduce model overhead, which consists of two parts: the Pretrained Prior Network (PPN) and the Distribution Agnostic Refiner (DAR). We leverage the PPN, designed for fast inference and stable performance, to generate a robust prior for accelerating the DAR's convergence. The DAR is decomposed into a base layer and an enhancement layer, and only the enhancement layer needed to be packed into the bitstream. Finally, we propose a supervised model compression module to further supervise and minimize the bitrate of the enhancement layer parameters. Based on experiment results, HybridINR-PCGC achieves a significantly improved compression rate and encoding efficiency. Specifically, our method achieves a Bpp reduction of approximately 20.43% compared to G-PCC on 8iVFB. In the challenging out-of-distribution scenario Cat1B, our method achieves a Bpp reduction of approximately 57.85% compared to UniPCGC. And our method exhibits a superior time-rate trade-off, achieving an average Bpp reduction of 15.193% relative to the LINR-PCGC on 8iVFB.
REPAIR: Robust Editing via Progressive Adaptive Intervention and Reintegration
Oct 02, 2025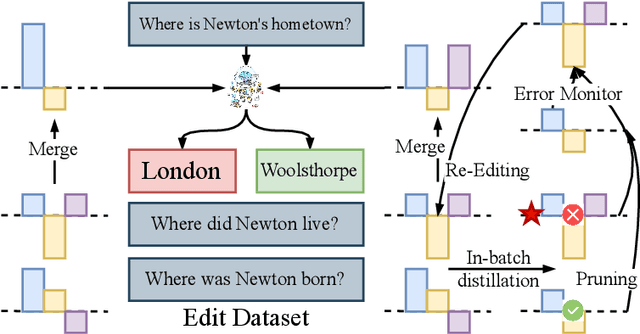
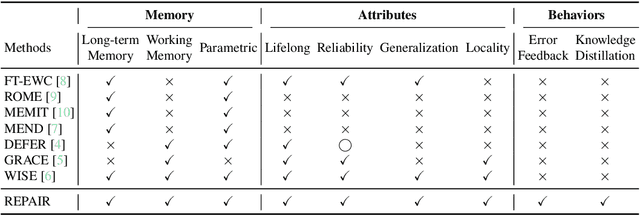
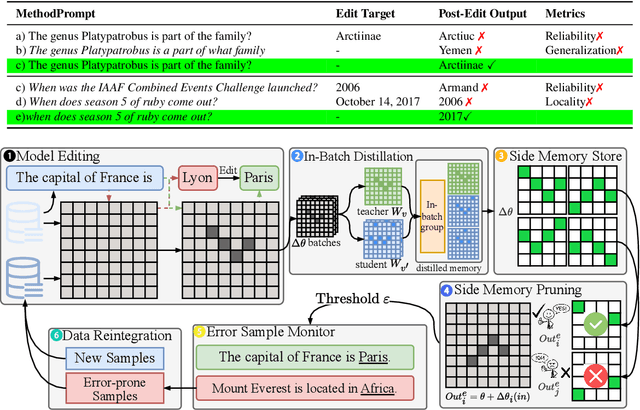
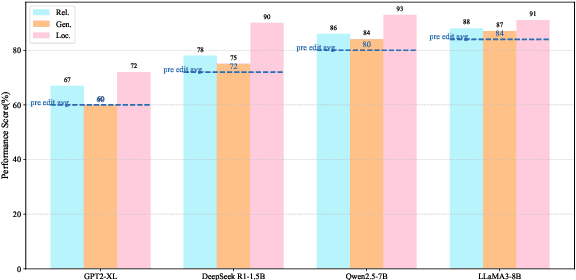
Post-training for large language models (LLMs) is constrained by the high cost of acquiring new knowledge or correcting errors and by the unintended side effects that frequently arise from retraining. To address these issues, we introduce REPAIR (Robust Editing via Progressive Adaptive Intervention and Reintegration), a lifelong editing framework designed to support precise and low-cost model updates while preserving non-target knowledge. REPAIR mitigates the instability and conflicts of large-scale sequential edits through a closed-loop feedback mechanism coupled with dynamic memory management. Furthermore, by incorporating frequent knowledge fusion and enforcing strong locality guards, REPAIR effectively addresses the shortcomings of traditional distribution-agnostic approaches that often overlook unintended ripple effects. Our experiments demonstrate that REPAIR boosts editing accuracy by 10%-30% across multiple model families and significantly reduces knowledge forgetting. This work introduces a robust framework for developing reliable, scalable, and continually evolving LLMs.
3DGS-IEval-15K: A Large-scale Image Quality Evaluation Database for 3D Gaussian-Splatting
Jun 17, 20253D Gaussian Splatting (3DGS) has emerged as a promising approach for novel view synthesis, offering real-time rendering with high visual fidelity. However, its substantial storage requirements present significant challenges for practical applications. While recent state-of-the-art (SOTA) 3DGS methods increasingly incorporate dedicated compression modules, there is a lack of a comprehensive framework to evaluate their perceptual impact. Therefore we present 3DGS-IEval-15K, the first large-scale image quality assessment (IQA) dataset specifically designed for compressed 3DGS representations. Our dataset encompasses 15,200 images rendered from 10 real-world scenes through 6 representative 3DGS algorithms at 20 strategically selected viewpoints, with different compression levels leading to various distortion effects. Through controlled subjective experiments, we collect human perception data from 60 viewers. We validate dataset quality through scene diversity and MOS distribution analysis, and establish a comprehensive benchmark with 30 representative IQA metrics covering diverse types. As the largest-scale 3DGS quality assessment dataset to date, our work provides a foundation for developing 3DGS specialized IQA metrics, and offers essential data for investigating view-dependent quality distribution patterns unique to 3DGS. The database is publicly available at https://github.com/YukeXing/3DGS-IEval-15K.
Generalizable Trajectory Prediction via Inverse Reinforcement Learning with Mamba-Graph Architecture
Jun 14, 2025Accurate driving behavior modeling is fundamental to safe and efficient trajectory prediction, yet remains challenging in complex traffic scenarios. This paper presents a novel Inverse Reinforcement Learning (IRL) framework that captures human-like decision-making by inferring diverse reward functions, enabling robust cross-scenario adaptability. The learned reward function is utilized to maximize the likelihood of output by the encoder-decoder architecture that combines Mamba blocks for efficient long-sequence dependency modeling with graph attention networks to encode spatial interactions among traffic agents. Comprehensive evaluations on urban intersections and roundabouts demonstrate that the proposed method not only outperforms various popular approaches in prediction accuracy but also achieves 2 times higher generalization performance to unseen scenarios compared to other IRL-based method.
High-Throughput LLM inference on Heterogeneous Clusters
Apr 18, 2025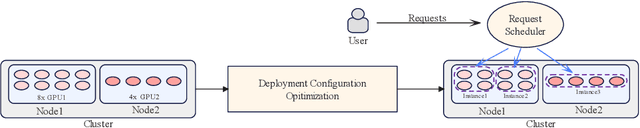
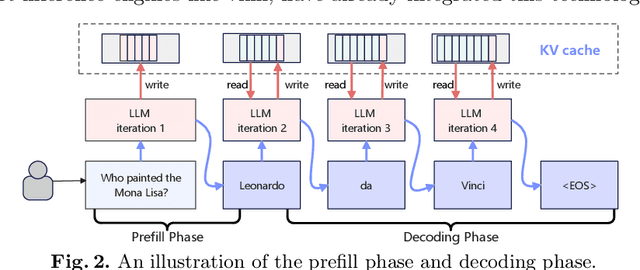


Nowadays, many companies possess various types of AI accelerators, forming heterogeneous clusters. Efficiently leveraging these clusters for high-throughput large language model (LLM) inference services can significantly reduce costs and expedite task processing. However, LLM inference on heterogeneous clusters presents two main challenges. Firstly, different deployment configurations can result in vastly different performance. The number of possible configurations is large, and evaluating the effectiveness of a specific setup is complex. Thus, finding an optimal configuration is not an easy task. Secondly, LLM inference instances within a heterogeneous cluster possess varying processing capacities, leading to different processing speeds for handling inference requests. Evaluating these capacities and designing a request scheduling algorithm that fully maximizes the potential of each instance is challenging. In this paper, we propose a high-throughput inference service system on heterogeneous clusters. First, the deployment configuration is optimized by modeling the resource amount and expected throughput and using the exhaustive search method. Second, a novel mechanism is proposed to schedule requests among instances, which fully considers the different processing capabilities of various instances. Extensive experiments show that the proposed scheduler improves throughput by 122.5% and 33.6% on two heterogeneous clusters, respectively.
Light4GS: Lightweight Compact 4D Gaussian Splatting Generation via Context Model
Mar 18, 2025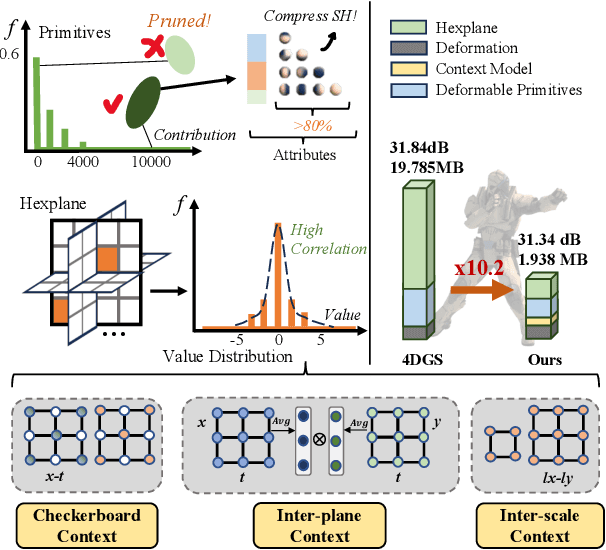



3D Gaussian Splatting (3DGS) has emerged as an efficient and high-fidelity paradigm for novel view synthesis. To adapt 3DGS for dynamic content, deformable 3DGS incorporates temporally deformable primitives with learnable latent embeddings to capture complex motions. Despite its impressive performance, the high-dimensional embeddings and vast number of primitives lead to substantial storage requirements. In this paper, we introduce a \textbf{Light}weight \textbf{4}D\textbf{GS} framework, called Light4GS, that employs significance pruning with a deep context model to provide a lightweight storage-efficient dynamic 3DGS representation. The proposed Light4GS is based on 4DGS that is a typical representation of deformable 3DGS. Specifically, our framework is built upon two core components: (1) a spatio-temporal significance pruning strategy that eliminates over 64\% of the deformable primitives, followed by an entropy-constrained spherical harmonics compression applied to the remainder; and (2) a deep context model that integrates intra- and inter-prediction with hyperprior into a coarse-to-fine context structure to enable efficient multiscale latent embedding compression. Our approach achieves over 120x compression and increases rendering FPS up to 20\% compared to the baseline 4DGS, and also superior to frame-wise state-of-the-art 3DGS compression methods, revealing the effectiveness of our Light4GS in terms of both intra- and inter-prediction methods without sacrificing rendering quality.
Shaping Sparse Rewards in Reinforcement Learning: A Semi-supervised Approach
Jan 31, 2025



In many real-world scenarios, reward signal for agents are exceedingly sparse, making it challenging to learn an effective reward function for reward shaping. To address this issue, our approach performs reward shaping not only by utilizing non-zero-reward transitions but also by employing the Semi-Supervised Learning (SSL) technique combined with a novel data augmentation to learn trajectory space representations from the majority of transitions, zero-reward transitions, thereby improving the efficacy of reward shaping. Experimental results in Atari and robotic manipulation demonstrate that our method effectively generalizes reward shaping to sparse reward scenarios, achieving up to four times better performance in reaching higher best scores compared to curiosity-driven methods. The proposed double entropy data augmentation enhances performance, showcasing a 15.8\% increase in best score over other augmentation methods.
Data-driven inventory management for new products: A warm-start and adjusted Dyna-$Q$ approach
Jan 15, 2025



In this paper, we propose a novel reinforcement learning algorithm for inventory management of newly launched products with no or limited historical demand information. The algorithm follows the classic Dyna-$Q$ structure, balancing the model-based and model-free approaches, while accelerating the training process of Dyna-$Q$ and mitigating the model discrepancy generated by the model-based feedback. Warm-start information from the demand data of existing similar products can be incorporated into the algorithm to further stabilize the early-stage training and reduce the variance of the estimated optimal policy. Our approach is validated through a case study of bakery inventory management with real data. The adjusted Dyna-$Q$ shows up to a 23.7% reduction in average daily cost compared with $Q$-learning, and up to a 77.5% reduction in training time within the same horizon compared with classic Dyna-$Q$. By incorporating the warm-start information, it can be found that the adjusted Dyna-$Q$ has the lowest total cost, lowest variance in total cost, and relatively low shortage percentages among all the algorithms under a 30-day testing.
A Hierarchical Compression Technique for 3D Gaussian Splatting Compression
Nov 11, 2024



3D Gaussian Splatting (GS) demonstrates excellent rendering quality and generation speed in novel view synthesis. However, substantial data size poses challenges for storage and transmission, making 3D GS compression an essential technology. Current 3D GS compression research primarily focuses on developing more compact scene representations, such as converting explicit 3D GS data into implicit forms. In contrast, compression of the GS data itself has hardly been explored. To address this gap, we propose a Hierarchical GS Compression (HGSC) technique. Initially, we prune unimportant Gaussians based on importance scores derived from both global and local significance, effectively reducing redundancy while maintaining visual quality. An Octree structure is used to compress 3D positions. Based on the 3D GS Octree, we implement a hierarchical attribute compression strategy by employing a KD-tree to partition the 3D GS into multiple blocks. We apply farthest point sampling to select anchor primitives within each block and others as non-anchor primitives with varying Levels of Details (LoDs). Anchor primitives serve as reference points for predicting non-anchor primitives across different LoDs to reduce spatial redundancy. For anchor primitives, we use the region adaptive hierarchical transform to achieve near-lossless compression of various attributes. For non-anchor primitives, each is predicted based on the k-nearest anchor primitives. To further minimize prediction errors, the reconstructed LoD and anchor primitives are combined to form new anchor primitives to predict the next LoD. Our method notably achieves superior compression quality and a significant data size reduction of over 4.5 times compared to the state-of-the-art compression method on small scenes datasets.
Utilizing Large Language Models for Event Deconstruction to Enhance Multimodal Aspect-Based Sentiment Analysis
Oct 18, 2024
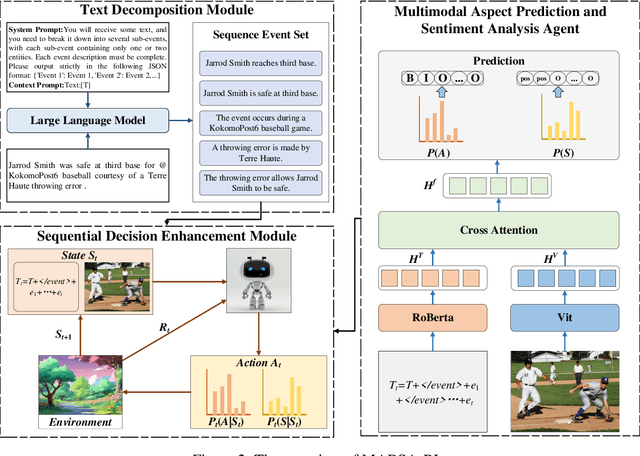
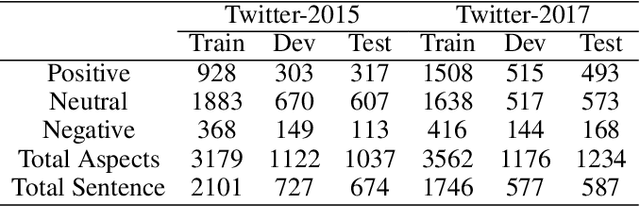

With the rapid development of the internet, the richness of User-Generated Contentcontinues to increase, making Multimodal Aspect-Based Sentiment Analysis (MABSA) a research hotspot. Existing studies have achieved certain results in MABSA, but they have not effectively addressed the analytical challenges in scenarios where multiple entities and sentiments coexist. This paper innovatively introduces Large Language Models (LLMs) for event decomposition and proposes a reinforcement learning framework for Multimodal Aspect-based Sentiment Analysis (MABSA-RL) framework. This framework decomposes the original text into a set of events using LLMs, reducing the complexity of analysis, introducing reinforcement learning to optimize model parameters. Experimental results show that MABSA-RL outperforms existing advanced methods on two benchmark datasets. This paper provides a new research perspective and method for multimodal aspect-level sentiment analysis.