 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRasterizing Wireless Radiance Field via Deformable 2D Gaussian Splatting
Jun 15, 2025Modeling the wireless radiance field (WRF) is fundamental to modern communication systems, enabling key tasks such as localization, sensing, and channel estimation. Traditional approaches, which rely on empirical formulas or physical simulations, often suffer from limited accuracy or require strong scene priors. Recent neural radiance field (NeRF-based) methods improve reconstruction fidelity through differentiable volumetric rendering, but their reliance on computationally expensive multilayer perceptron (MLP) queries hinders real-time deployment. To overcome these challenges, we introduce Gaussian splatting (GS) to the wireless domain, leveraging its efficiency in modeling optical radiance fields to enable compact and accurate WRF reconstruction. Specifically, we propose SwiftWRF, a deformable 2D Gaussian splatting framework that synthesizes WRF spectra at arbitrary positions under single-sided transceiver mobility. SwiftWRF employs CUDA-accelerated rasterization to render spectra at over 100000 fps and uses a lightweight MLP to model the deformation of 2D Gaussians, effectively capturing mobility-induced WRF variations. In addition to novel spectrum synthesis, the efficacy of SwiftWRF is further underscored in its applications in angle-of-arrival (AoA) and received signal strength indicator (RSSI) prediction. Experiments conducted on both real-world and synthetic indoor scenes demonstrate that SwiftWRF can reconstruct WRF spectra up to 500x faster than existing state-of-the-art methods, while significantly enhancing its signal quality. Code and datasets will be released.
ADC-GS: Anchor-Driven Deformable and Compressed Gaussian Splatting for Dynamic Scene Reconstruction
May 13, 2025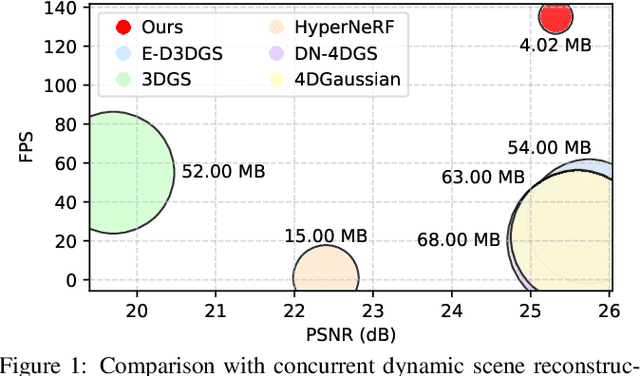


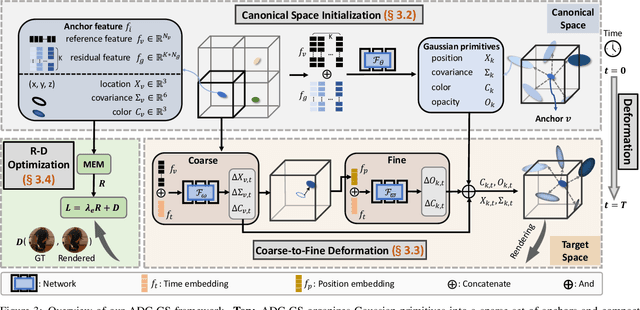
Existing 4D Gaussian Splatting methods rely on per-Gaussian deformation from a canonical space to target frames, which overlooks redundancy among adjacent Gaussian primitives and results in suboptimal performance. To address this limitation, we propose Anchor-Driven Deformable and Compressed Gaussian Splatting (ADC-GS), a compact and efficient representation for dynamic scene reconstruction. Specifically, ADC-GS organizes Gaussian primitives into an anchor-based structure within the canonical space, enhanced by a temporal significance-based anchor refinement strategy. To reduce deformation redundancy, ADC-GS introduces a hierarchical coarse-to-fine pipeline that captures motions at varying granularities. Moreover, a rate-distortion optimization is adopted to achieve an optimal balance between bitrate consumption and representation fidelity. Experimental results demonstrate that ADC-GS outperforms the per-Gaussian deformation approaches in rendering speed by 300%-800% while achieving state-of-the-art storage efficiency without compromising rendering quality. The code is released at https://github.com/H-Huang774/ADC-GS.git.
Light4GS: Lightweight Compact 4D Gaussian Splatting Generation via Context Model
Mar 18, 2025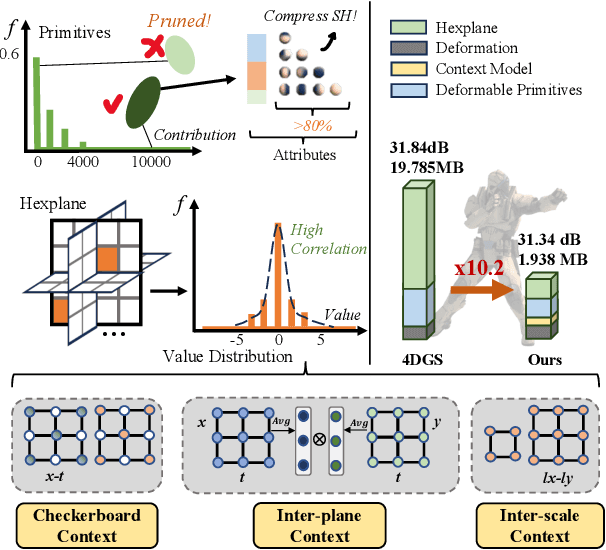



3D Gaussian Splatting (3DGS) has emerged as an efficient and high-fidelity paradigm for novel view synthesis. To adapt 3DGS for dynamic content, deformable 3DGS incorporates temporally deformable primitives with learnable latent embeddings to capture complex motions. Despite its impressive performance, the high-dimensional embeddings and vast number of primitives lead to substantial storage requirements. In this paper, we introduce a \textbf{Light}weight \textbf{4}D\textbf{GS} framework, called Light4GS, that employs significance pruning with a deep context model to provide a lightweight storage-efficient dynamic 3DGS representation. The proposed Light4GS is based on 4DGS that is a typical representation of deformable 3DGS. Specifically, our framework is built upon two core components: (1) a spatio-temporal significance pruning strategy that eliminates over 64\% of the deformable primitives, followed by an entropy-constrained spherical harmonics compression applied to the remainder; and (2) a deep context model that integrates intra- and inter-prediction with hyperprior into a coarse-to-fine context structure to enable efficient multiscale latent embedding compression. Our approach achieves over 120x compression and increases rendering FPS up to 20\% compared to the baseline 4DGS, and also superior to frame-wise state-of-the-art 3DGS compression methods, revealing the effectiveness of our Light4GS in terms of both intra- and inter-prediction methods without sacrificing rendering quality.
SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint
Mar 17, 2025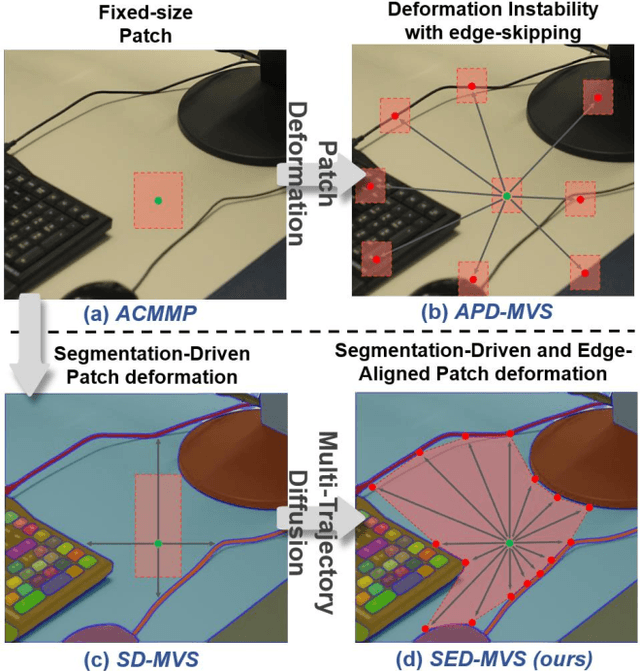
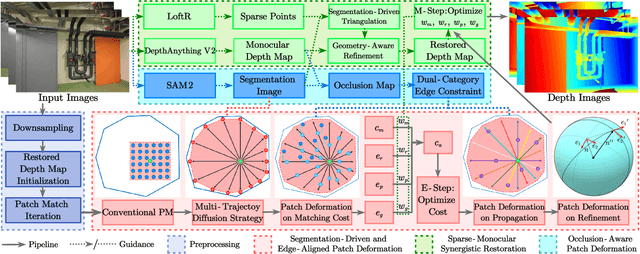
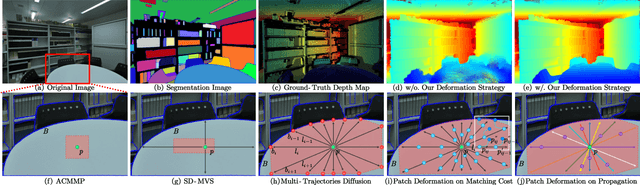

Recently, patch-deformation methods have exhibited significant effectiveness in multi-view stereo owing to the deformable and expandable patches in reconstructing textureless areas. However, such methods primarily emphasize broadening the receptive field in textureless areas, while neglecting deformation instability caused by easily overlooked edge-skipping, potentially leading to matching distortions. To address this, we propose SED-MVS, which adopts panoptic segmentation and multi-trajectory diffusion strategy for segmentation-driven and edge-aligned patch deformation. Specifically, to prevent unanticipated edge-skipping, we first employ SAM2 for panoptic segmentation as depth-edge guidance to guide patch deformation, followed by multi-trajectory diffusion strategy to ensure patches are comprehensively aligned with depth edges. Moreover, to avoid potential inaccuracy of random initialization, we combine both sparse points from LoFTR and monocular depth map from DepthAnything V2 to restore reliable and realistic depth map for initialization and supervised guidance. Finally, we integrate segmentation image with monocular depth map to exploit inter-instance occlusion relationship, then further regard them as occlusion map to implement two distinct edge constraint, thereby facilitating occlusion-aware patch deformation. Extensive results on ETH3D, Tanks & Temples, BlendedMVS and Strecha datasets validate the state-of-the-art performance and robust generalization capability of our proposed method.
D2GV: Deformable 2D Gaussian Splatting for Video Representation in 400FPS
Mar 07, 2025Implicit Neural Representations (INRs) have emerged as a powerful approach for video representation, offering versatility across tasks such as compression and inpainting. However, their implicit formulation limits both interpretability and efficacy, undermining their practicality as a comprehensive solution. We propose a novel video representation based on deformable 2D Gaussian splatting, dubbed D2GV, which aims to achieve three key objectives: 1) improved efficiency while delivering superior quality; 2) enhanced scalability and interpretability; and 3) increased friendliness for downstream tasks. Specifically, we initially divide the video sequence into fixed-length Groups of Pictures (GoP) to allow parallel training and linear scalability with video length. For each GoP, D2GV represents video frames by applying differentiable rasterization to 2D Gaussians, which are deformed from a canonical space into their corresponding timestamps. Notably, leveraging efficient CUDA-based rasterization, D2GV converges fast and decodes at speeds exceeding 400 FPS, while delivering quality that matches or surpasses state-of-the-art INRs. Moreover, we incorporate a learnable pruning and quantization strategy to streamline D2GV into a more compact representation. We demonstrate D2GV's versatility in tasks including video interpolation, inpainting and denoising, underscoring its potential as a promising solution for video representation. Code is available at: \href{https://github.com/Evan-sudo/D2GV}{https://github.com/Evan-sudo/D2GV}.