 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSarcasmMiner: A Dual-Track Post-Training Framework for Robust Audio-Visual Sarcasm Reasoning
Mar 05, 2026Multimodal sarcasm detection requires resolving pragmatic incongruity across textual, acoustic, and visual cues through cross-modal reasoning. To enable robust sarcasm reasoning with foundation models, we propose SarcasmMiner, a reinforcement learning based post-training framework that resists hallucination in multimodal reasoning. We reformulate sarcasm detection as structured reasoning and adopt a dual-track distillation strategy: high-quality teacher trajectories initialize the student model, while the full set of trajectories trains a generative reward model (GenRM) to evaluate reasoning quality. The student is optimized with group relative policy optimization (GRPO) using decoupled rewards for accuracy and reasoning quality. On MUStARD++, SarcasmMiner increases F1 from 59.83% (zero-shot), 68.23% (supervised finetuning) to 70.22%. These findings suggest that reasoning-aware reward modeling enhances both performance and multimodal grounding.
Seeking Necessary and Sufficient Information from Multimodal Medical Data
Feb 27, 2026Learning multimodal representations from medical images and other data sources can provide richer information for decision-making. While various multimodal models have been developed for this, they overlook learning features that are both necessary (must be present for the outcome to occur) and sufficient (enough to determine the outcome). We argue learning such features is crucial as they can improve model performance by capturing essential predictive information, and enhance model robustness to missing modalities as each modality can provide adequate predictive signals. Such features can be learned by leveraging the Probability of Necessity and Sufficiency (PNS) as a learning objective, an approach that has proven effective in unimodal settings. However, extending PNS to multimodal scenarios remains underexplored and is non-trivial as key conditions of PNS estimation are violated. We address this by decomposing multimodal representations into modality-invariant and modality-specific components, then deriving tractable PNS objectives for each. Experiments on synthetic and real-world medical datasets demonstrate our method's effectiveness. Code will be available on GitHub.
HybridINR-PCGC: Hybrid Lossless Point Cloud Geometry Compression Bridging Pretrained Model and Implicit Neural Representation
Feb 25, 2026Learning-based point cloud compression presents superior performance to handcrafted codecs. However, pretrained-based methods, which are based on end-to-end training and expected to generalize to all the potential samples, suffer from training data dependency. Implicit neural representation (INR) based methods are distribution-agnostic and more robust, but they require time-consuming online training and suffer from the bitstream overhead from the overfitted model. To address these limitations, we propose HybridINR-PCGC, a novel hybrid framework that bridges the pretrained model and INR. Our framework retains distribution-agnostic properties while leveraging a pretrained network to accelerate convergence and reduce model overhead, which consists of two parts: the Pretrained Prior Network (PPN) and the Distribution Agnostic Refiner (DAR). We leverage the PPN, designed for fast inference and stable performance, to generate a robust prior for accelerating the DAR's convergence. The DAR is decomposed into a base layer and an enhancement layer, and only the enhancement layer needed to be packed into the bitstream. Finally, we propose a supervised model compression module to further supervise and minimize the bitrate of the enhancement layer parameters. Based on experiment results, HybridINR-PCGC achieves a significantly improved compression rate and encoding efficiency. Specifically, our method achieves a Bpp reduction of approximately 20.43% compared to G-PCC on 8iVFB. In the challenging out-of-distribution scenario Cat1B, our method achieves a Bpp reduction of approximately 57.85% compared to UniPCGC. And our method exhibits a superior time-rate trade-off, achieving an average Bpp reduction of 15.193% relative to the LINR-PCGC on 8iVFB.
RAP: Fast Feedforward Rendering-Free Attribute-Guided Primitive Importance Score Prediction for Efficient 3D Gaussian Splatting Processing
Feb 23, 20263D Gaussian Splatting (3DGS) has emerged as a leading technology for high-quality 3D scene reconstruction. However, the iterative refinement and densification process leads to the generation of a large number of primitives, each contributing to the reconstruction to a substantially different extent. Estimating primitive importance is thus crucial, both for removing redundancy during reconstruction and for enabling efficient compression and transmission. Existing methods typically rely on rendering-based analyses, where each primitive is evaluated through its contribution across multiple camera viewpoints. However, such methods are sensitive to the number and selection of views, rely on specialized differentiable rasterizers, and have long calculation times that grow linearly with view count, making them difficult to integrate as plug-and-play modules and limiting scalability and generalization. To address these issues, we propose RAP, a fast feedforward rendering-free attribute-guided method for efficient importance score prediction in 3DGS. RAP infers primitive significance directly from intrinsic Gaussian attributes and local neighborhood statistics, avoiding rendering-based or visibility-dependent computations. A compact MLP predicts per-primitive importance scores using rendering loss, pruning-aware loss, and significance distribution regularization. After training on a small set of scenes, RAP generalizes effectively to unseen data and can be seamlessly integrated into reconstruction, compression, and transmission pipelines. Our code is publicly available at https://github.com/yyyykf/RAP.
HPC: Hierarchical Point-based Latent Representation for Streaming Dynamic Gaussian Splatting Compression
Jan 31, 2026While dynamic Gaussian Splatting has driven significant advances in free-viewpoint video, maintaining its rendering quality with a small memory footprint for efficient streaming transmission still presents an ongoing challenge. Existing streaming dynamic Gaussian Splatting compression methods typically leverage a latent representation to drive the neural network for predicting Gaussian residuals between frames. Their core latent representations can be categorized into structured grid-based and unstructured point-based paradigms. However, the former incurs significant parameter redundancy by inevitably modeling unoccupied space, while the latter suffers from limited compactness as it fails to exploit local correlations. To relieve these limitations, we propose HPC, a novel streaming dynamic Gaussian Splatting compression framework. It employs a hierarchical point-based latent representation that operates on a per-Gaussian basis to avoid parameter redundancy in unoccupied space. Guided by a tailored aggregation scheme, these latent points achieve high compactness with low spatial redundancy. To improve compression efficiency, we further undertake the first investigation to compress neural networks for streaming dynamic Gaussian Splatting through mining and exploiting the inter-frame correlation of parameters. Combined with latent compression, this forms a fully end-to-end compression framework. Comprehensive experimental evaluations demonstrate that HPC substantially outperforms state-of-the-art methods. It achieves a storage reduction of 67% against its baseline while maintaining high reconstruction fidelity.
DALD-PCAC: Density-Adaptive Learning Descriptor for Point Cloud Lossless Attribute Compression
Jan 18, 2026Recently, deep learning has significantly advanced the performance of point cloud geometry compression. However, the learning-based lossless attribute compression of point clouds with varying densities is under-explored. In this paper, we develop a learning-based framework, namely DALD-PCAC that leverages Levels of Detail (LoD) to tailor for point cloud lossless attribute compression. We develop a point-wise attention model using a permutation-invariant Transformer to tackle the challenges of sparsity and irregularity of point clouds during context modeling. We also propose a Density-Adaptive Learning Descriptor (DALD) capable of capturing structure and correlations among points across a large range of neighbors. In addition, we develop a prior-guided block partitioning to reduce the attribute variance within blocks and enhance the performance. Experiments on LiDAR and object point clouds show that DALD-PCAC achieves the state-of-the-art performance on most data. Our method boosts the compression performance and is robust to the varying densities of point clouds. Moreover, it guarantees a good trade-off between performance and complexity, exhibiting great potential in real-world applications. The source code is available at https://github.com/zb12138/DALD_PCAC.
DeepRAHT: Learning Predictive RAHT for Point Cloud Attribute Compression
Jan 18, 2026Regional Adaptive Hierarchical Transform (RAHT) is an effective point cloud attribute compression (PCAC) method. However, its application in deep learning lacks research. In this paper, we propose an end-to-end RAHT framework for lossy PCAC based on the sparse tensor, called DeepRAHT. The RAHT transform is performed within the learning reconstruction process, without requiring manual RAHT for preprocessing. We also introduce the predictive RAHT to reduce bitrates and design a learning-based prediction model to enhance performance. Moreover, we devise a bitrate proxy that applies run-length coding to entropy model, achieving seamless variable-rate coding and improving robustness. DeepRAHT is a reversible and distortion-controllable framework, ensuring its lower bound performance and offering significant application potential. The experiments demonstrate that DeepRAHT is a high-performance, faster, and more robust solution than the baseline methods. Project Page: https://github.com/zb12138/DeepRAHT.
Lightweight 3D Gaussian Splatting Compression via Video Codec
Dec 12, 2025Current video-based GS compression methods rely on using Parallel Linear Assignment Sorting (PLAS) to convert 3D GS into smooth 2D maps, which are computationally expensive and time-consuming, limiting the application of GS on lightweight devices. In this paper, we propose a Lightweight 3D Gaussian Splatting (GS) Compression method based on Video codec (LGSCV). First, a two-stage Morton scan is proposed to generate blockwise 2D maps that are friendly for canonical video codecs in which the coding units (CU) are square blocks. A 3D Morton scan is used to permute GS primitives, followed by a 2D Morton scan to map the ordered GS primitives to 2D maps in a blockwise style. However, although the blockwise 2D maps report close performance to the PLAS map in high-bitrate regions, they show a quality collapse at medium-to-low bitrates. Therefore, a principal component analysis (PCA) is used to reduce the dimensionality of spherical harmonics (SH), and a MiniPLAS, which is flexible and fast, is designed to permute the primitives within certain block sizes. Incorporating SH PCA and MiniPLAS leads to a significant gain in rate-distortion (RD) performance, especially at medium and low bitrates. MiniPLAS can also guide the setting of the codec CU size configuration and significantly reduce encoding time. Experimental results on the MPEG dataset demonstrate that the proposed LGSCV achieves over 20% RD gain compared with state-of-the-art methods, while reducing 2D map generation time to approximately 1 second and cutting encoding time by 50%. The code is available at https://github.com/Qi-Yangsjtu/LGSCV .
J-SGFT: Joint Spatial and Graph Fourier Domain Learning for Point Cloud Attribute Deblocking
Nov 07, 2025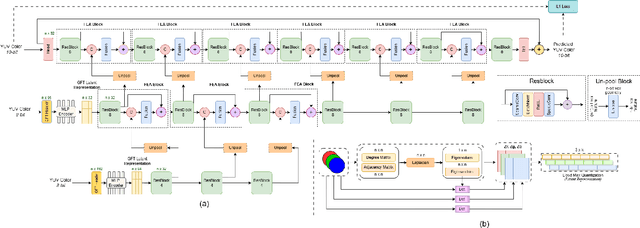
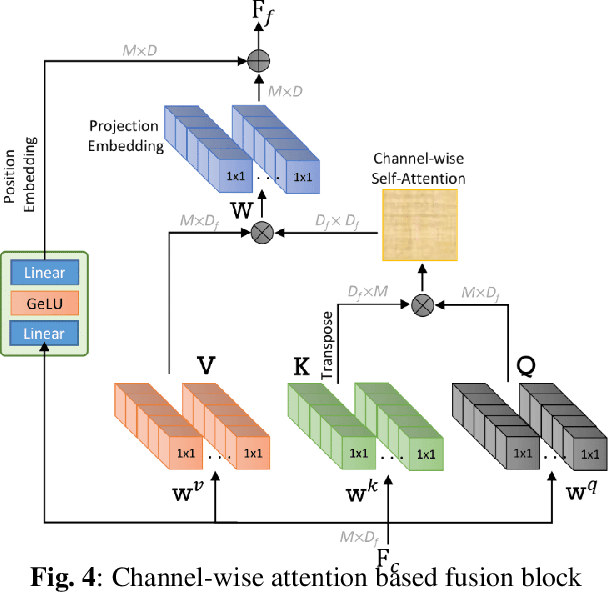
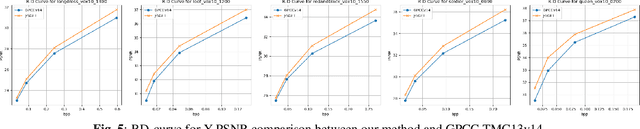

Point clouds (PC) are essential for AR/VR and autonomous driving but challenge compression schemes with their size, irregular sampling, and sparsity. MPEG's Geometry-based Point Cloud Compression (GPCC) methods successfully reduce bitrate; however, they introduce significant blocky artifacts in the reconstructed point cloud. We introduce a novel multi-scale postprocessing framework that fuses graph-Fourier latent attribute representations with sparse convolutions and channel-wise attention to efficiently deblock reconstructed point clouds. Against the GPCC TMC13v14 baseline, our approach achieves BD-rate reduction of 18.81\% in the Y channel and 18.14\% in the joint YUV on the 8iVFBv2 dataset, delivering markedly improved visual fidelity with minimal overhead.
TVMC: Time-Varying Mesh Compression via Multi-Stage Anchor Mesh Generation
Oct 26, 2025Time-varying meshes, characterized by dynamic connectivity and varying vertex counts, hold significant promise for applications such as augmented reality. However, their practical utilization remains challenging due to the substantial data volume required for high-fidelity representation. While various compression methods attempt to leverage temporal redundancy between consecutive mesh frames, most struggle with topological inconsistency and motion-induced artifacts. To address these issues, we propose Time-Varying Mesh Compression (TVMC), a novel framework built on multi-stage coarse-to-fine anchor mesh generation for inter-frame prediction. Specifically, the anchor mesh is progressively constructed in three stages: initial, coarse, and fine. The initial anchor mesh is obtained through fast topology alignment to exploit temporal coherence. A Kalman filter-based motion estimation module then generates a coarse anchor mesh by accurately compensating inter-frame motions. Subsequently, a Quadric Error Metric-based refinement step optimizes vertex positions to form a fine anchor mesh with improved geometric fidelity. Based on the refined anchor mesh, the inter-frame motions relative to the reference base mesh are encoded, while the residual displacements between the subdivided fine anchor mesh and the input mesh are adaptively quantized and compressed. This hierarchical strategy preserves consistent connectivity and high-quality surface approximation, while achieving an efficient and compact representation of dynamic geometry. Extensive experiments on standard MPEG dynamic mesh sequences demonstrate that TVMC achieves state-of-the-art compression performance. Compared to the latest V-DMC standard, it delivers a significant BD-rate gain of 10.2% ~ 16.9%, while preserving high reconstruction quality. The code is available at https://github.com/H-Huang774/TVMC.