 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametrically Efficient Inference for Kernel Measures of Noise Heterogeneity
May 26, 2026We develop semiparametrically efficient inference for kernel measures of noise heterogeneity in additive noise models. In many applications, the regression function is estimated using flexible machine learning methods. Downstream procedures based on the resulting residuals can then inherit first-stage bias: regression error may induce spurious dependence between covariates and residuals, invalidating the assumptions needed for standard analysis. We construct a novel Hilbert-valued one-step estimator of the kernel covariance operator between covariates and residuals. Our estimator yields bootstrap-calibrated tests for residual independence and goodness of fit in additive noise models, while also providing asymptotically efficient confidence intervals for the kernel dependence measure under noise heterogeneity. The framework extends to settings with additional covariates, enabling inference on distributional heterogeneity of residual noise across treatment groups. Simulations show improved calibration and power relative to naive plug-in residual methods.
Doubly Robust Proxy Causal Learning with Neural Mean Embeddings
May 10, 2026Unobserved confounding prevents standard covariate adjustment from identifying causal response functions in observational studies. Proxy causal learning addresses this problem through bridge equations involving treatment- and outcome-inducing proxies, avoiding direct recovery of the latent confounder. Existing doubly robust proxy estimators combine outcome and treatment bridges, but typically rely on fixed kernels, sieves, or low-dimensional semiparametric models; existing neural proxy methods are more flexible, but are largely single-bridge estimators. We develop a neural doubly robust framework for proxy causal learning with continuous and structured treatments. Our method introduces a neural mean-embedding estimator for the treatment bridge, combines it with a neural outcome bridge, and estimates the doubly robust correction through a final regression stage. The framework covers population, heterogeneous, and conditional dose-response functions, yielding full response-curve estimators rather than binary-treatment effects. The algorithms use two stages for each bridge and history-aware updates of the final linear layers to stabilize stochastic multi-stage training. We prove consistency of the algorithms showing that the doubly robust error is controlled by the final averaging and regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors. Across synthetic and image-valued benchmarks, the proposed estimators outperform existing baselines and single-bridge neural estimators, showing the benefit of combining learned outcome and treatment bridges in a doubly robust construction. Our implementation is available at https://github.com/BariscanBozkurt/DRPCL-Neural-Mean-Embedding.
Instrumental Variable Analysis Without Structural Equations
Apr 27, 2026We consider debiased inference on least-squares solutions to inverse problems as a way to avoid having to assume exact solutions exist. Such assumptions are substantive and not innocuous and their failure may well imperil inference when we impose them on the statistical model. Our approach instead allows us to conduct inference on a quantity that is defined regardless of solutions existing and coincides with the usual estimands when they do. For the case of instrumental variables, this means we can motivate the analysis with structural models but these do not need to hold exactly for the inferential procedure to remain valid.
Demystifying Spectral Feature Learning for Instrumental Variable Regression
Jun 12, 2025We address the problem of causal effect estimation in the presence of hidden confounders, using nonparametric instrumental variable (IV) regression. A leading strategy employs spectral features - that is, learned features spanning the top eigensubspaces of the operator linking treatments to instruments. We derive a generalization error bound for a two-stage least squares estimator based on spectral features, and gain insights into the method's performance and failure modes. We show that performance depends on two key factors, leading to a clear taxonomy of outcomes. In a good scenario, the approach is optimal. This occurs with strong spectral alignment, meaning the structural function is well-represented by the top eigenfunctions of the conditional operator, coupled with this operator's slow eigenvalue decay, indicating a strong instrument. Performance degrades in a bad scenario: spectral alignment remains strong, but rapid eigenvalue decay (indicating a weaker instrument) demands significantly more samples for effective feature learning. Finally, in the ugly scenario, weak spectral alignment causes the method to fail, regardless of the eigenvalues' characteristics. Our synthetic experiments empirically validate this taxonomy.
Density Ratio-Free Doubly Robust Proxy Causal Learning
May 26, 2025We study the problem of causal function estimation in the Proxy Causal Learning (PCL) framework, where confounders are not observed but proxies for the confounders are available. Two main approaches have been proposed: outcome bridge-based and treatment bridge-based methods. In this work, we propose two kernel-based doubly robust estimators that combine the strengths of both approaches, and naturally handle continuous and high-dimensional variables. Our identification strategy builds on a recent density ratio-free method for treatment bridge-based PCL; furthermore, in contrast to previous approaches, it does not require indicator functions or kernel smoothing over the treatment variable. These properties make it especially well-suited for continuous or high-dimensional treatments. By using kernel mean embeddings, we have closed-form solutions and strong consistency guarantees. Our estimators outperform existing methods on PCL benchmarks, including a prior doubly robust method that requires both kernel smoothing and density ratio estimation.
Regularized least squares learning with heavy-tailed noise is minimax optimal
May 20, 2025
This paper examines the performance of ridge regression in reproducing kernel Hilbert spaces in the presence of noise that exhibits a finite number of higher moments. We establish excess risk bounds consisting of subgaussian and polynomial terms based on the well known integral operator framework. The dominant subgaussian component allows to achieve convergence rates that have previously only been derived under subexponential noise - a prevalent assumption in related work from the last two decades. These rates are optimal under standard eigenvalue decay conditions, demonstrating the asymptotic robustness of regularized least squares against heavy-tailed noise. Our derivations are based on a Fuk-Nagaev inequality for Hilbert-space valued random variables.
Density Ratio-based Proxy Causal Learning Without Density Ratios
Mar 11, 2025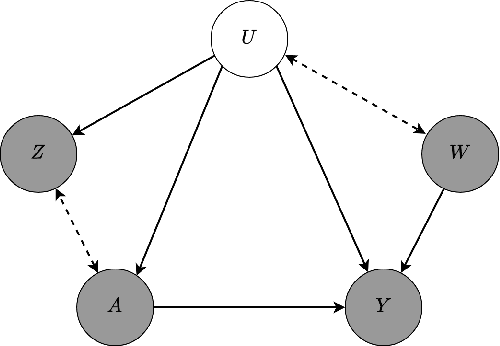
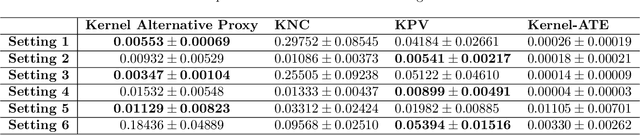
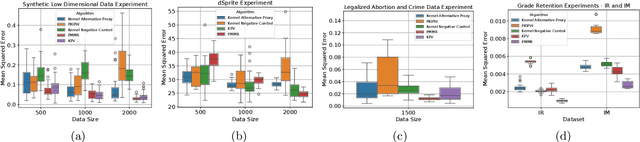
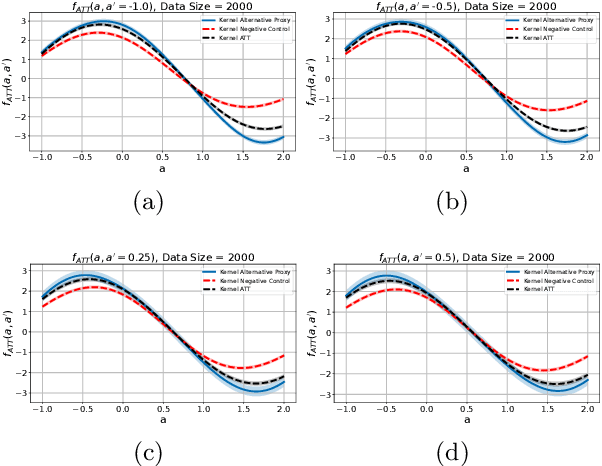
We address the setting of Proxy Causal Learning (PCL), which has the goal of estimating causal effects from observed data in the presence of hidden confounding. Proxy methods accomplish this task using two proxy variables related to the latent confounder: a treatment proxy (related to the treatment) and an outcome proxy (related to the outcome). Two approaches have been proposed to perform causal effect estimation given proxy variables; however only one of these has found mainstream acceptance, since the other was understood to require density ratio estimation - a challenging task in high dimensions. In the present work, we propose a practical and effective implementation of the second approach, which bypasses explicit density ratio estimation and is suitable for continuous and high-dimensional treatments. We employ kernel ridge regression to derive estimators, resulting in simple closed-form solutions for dose-response and conditional dose-response curves, along with consistency guarantees. Our methods empirically demonstrate superior or comparable performance to existing frameworks on synthetic and real-world datasets.
Optimality and Adaptivity of Deep Neural Features for Instrumental Variable Regression
Jan 09, 2025

We provide a convergence analysis of deep feature instrumental variable (DFIV) regression (Xu et al., 2021), a nonparametric approach to IV regression using data-adaptive features learned by deep neural networks in two stages. We prove that the DFIV algorithm achieves the minimax optimal learning rate when the target structural function lies in a Besov space. This is shown under standard nonparametric IV assumptions, and an additional smoothness assumption on the regularity of the conditional distribution of the covariate given the instrument, which controls the difficulty of Stage 1. We further demonstrate that DFIV, as a data-adaptive algorithm, is superior to fixed-feature (kernel or sieve) IV methods in two ways. First, when the target function possesses low spatial homogeneity (i.e., it has both smooth and spiky/discontinuous regions), DFIV still achieves the optimal rate, while fixed-feature methods are shown to be strictly suboptimal. Second, comparing with kernel-based two-stage regression estimators, DFIV is provably more data efficient in the Stage 1 samples.
Nonparametric Instrumental Regression via Kernel Methods is Minimax Optimal
Nov 29, 2024We study the kernel instrumental variable algorithm of \citet{singh2019kernel}, a nonparametric two-stage least squares (2SLS) procedure which has demonstrated strong empirical performance. We provide a convergence analysis that covers both the identified and unidentified settings: when the structural function cannot be identified, we show that the kernel NPIV estimator converges to the IV solution with minimum norm. Crucially, our convergence is with respect to the strong $L_2$-norm, rather than a pseudo-norm. Additionally, we characterize the smoothness of the target function without relying on the instrument, instead leveraging a new description of the projected subspace size (this being closely related to the link condition in inverse learning literature). With the subspace size description and under standard kernel learning assumptions, we derive, for the first time, the minimax optimal learning rate for kernel NPIV in the strong $L_2$-norm. Our result demonstrates that the strength of the instrument is essential to achieve efficient learning. We also improve the original kernel NPIV algorithm by adopting a general spectral regularization in stage 1 regression. The modified regularization can overcome the saturation effect of Tikhonov regularization.
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
May 23, 2024We study theoretical properties of a broad class of regularized algorithms with vector-valued output. These spectral algorithms include kernel ridge regression, kernel principal component regression, various implementations of gradient descent and many more. Our contributions are twofold. First, we rigorously confirm the so-called saturation effect for ridge regression with vector-valued output by deriving a novel lower bound on learning rates; this bound is shown to be suboptimal when the smoothness of the regression function exceeds a certain level. Second, we present the upper bound for the finite sample risk general vector-valued spectral algorithms, applicable to both well-specified and misspecified scenarios (where the true regression function lies outside of the hypothesis space) which is minimax optimal in various regimes. All of our results explicitly allow the case of infinite-dimensional output variables, proving consistency of recent practical applications.