 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Features for Operator-Valued Kernels: Bridging Kernel Methods and Neural Operators
Mar 01, 2026In this work, we investigate the generalization properties of random feature methods. Our analysis extends prior results for Tikhonov regularization to a broad class of spectral regularization techniques and further generalizes the setting to operator-valued kernels. This unified framework enables a rigorous theoretical analysis of neural operators and neural networks through the lens of the Neural Tangent Kernel (NTK). In particular, it allows us to establish optimal learning rates and provides a good understanding of how many neurons are required to achieve a given accuracy. Furthermore, we establish minimax rates in the well-specified case and also in the misspecified case, where the target is not contained in the reproducing kernel Hilbert space. These results sharpen and complete earlier findings for specific kernel algorithms.
Regularized least squares learning with heavy-tailed noise is minimax optimal
May 20, 2025
This paper examines the performance of ridge regression in reproducing kernel Hilbert spaces in the presence of noise that exhibits a finite number of higher moments. We establish excess risk bounds consisting of subgaussian and polynomial terms based on the well known integral operator framework. The dominant subgaussian component allows to achieve convergence rates that have previously only been derived under subexponential noise - a prevalent assumption in related work from the last two decades. These rates are optimal under standard eigenvalue decay conditions, demonstrating the asymptotic robustness of regularized least squares against heavy-tailed noise. Our derivations are based on a Fuk-Nagaev inequality for Hilbert-space valued random variables.
Optimal Convergence Rates for Neural Operators
Dec 23, 2024We introduce the neural tangent kernel (NTK) regime for two-layer neural operators and analyze their generalization properties. For early-stopped gradient descent (GD), we derive fast convergence rates that are known to be minimax optimal within the framework of non-parametric regression in reproducing kernel Hilbert spaces (RKHS). We provide bounds on the number of hidden neurons and the number of second-stage samples necessary for generalization. To justify our NTK regime, we additionally show that any operator approximable by a neural operator can also be approximated by an operator from the RKHS. A key application of neural operators is learning surrogate maps for the solution operators of partial differential equations (PDEs). We consider the standard Poisson equation to illustrate our theoretical findings with simulations.
Gradient-Based Non-Linear Inverse Learning
Dec 21, 2024We study statistical inverse learning in the context of nonlinear inverse problems under random design. Specifically, we address a class of nonlinear problems by employing gradient descent (GD) and stochastic gradient descent (SGD) with mini-batching, both using constant step sizes. Our analysis derives convergence rates for both algorithms under classical a priori assumptions on the smoothness of the target function. These assumptions are expressed in terms of the integral operator associated with the tangent kernel, as well as through a bound on the effective dimension. Additionally, we establish stopping times that yield minimax-optimal convergence rates within the classical reproducing kernel Hilbert space (RKHS) framework. These results demonstrate the efficacy of GD and SGD in achieving optimal rates for nonlinear inverse problems in random design.
Statistical inverse learning problems with random observations
Dec 23, 2023We provide an overview of recent progress in statistical inverse problems with random experimental design, covering both linear and nonlinear inverse problems. Different regularization schemes have been studied to produce robust and stable solutions. We discuss recent results in spectral regularization methods and regularization by projection, exploring both approaches within the context of Hilbert scales and presenting new insights particularly in regularization by projection. Additionally, we overview recent advancements in regularization using convex penalties. Convergence rates are analyzed in terms of the sample size in a probabilistic sense, yielding minimax rates in both expectation and probability. To achieve these results, the structure of reproducing kernel Hilbert spaces is leveraged to establish minimax rates in the statistical learning setting. We detail the assumptions underpinning these key elements of our proofs. Finally, we demonstrate the application of these concepts to nonlinear inverse problems in pharmacokinetic/pharmacodynamic (PK/PD) models, where the task is to predict changes in drug concentrations in patients.
How many Neurons do we need? A refined Analysis for Shallow Networks trained with Gradient Descent
Sep 14, 2023We analyze the generalization properties of two-layer neural networks in the neural tangent kernel (NTK) regime, trained with gradient descent (GD). For early stopped GD we derive fast rates of convergence that are known to be minimax optimal in the framework of non-parametric regression in reproducing kernel Hilbert spaces. On our way, we precisely keep track of the number of hidden neurons required for generalization and improve over existing results. We further show that the weights during training remain in a vicinity around initialization, the radius being dependent on structural assumptions such as degree of smoothness of the regression function and eigenvalue decay of the integral operator associated to the NTK.
Random feature approximation for general spectral methods
Aug 29, 2023Random feature approximation is arguably one of the most popular techniques to speed up kernel methods in large scale algorithms and provides a theoretical approach to the analysis of deep neural networks. We analyze generalization properties for a large class of spectral regularization methods combined with random features, containing kernel methods with implicit regularization such as gradient descent or explicit methods like Tikhonov regularization. For our estimators we obtain optimal learning rates over regularity classes (even for classes that are not included in the reproducing kernel Hilbert space), which are defined through appropriate source conditions. This improves or completes previous results obtained in related settings for specific kernel algorithms.
Learning linear operators: Infinite-dimensional regression as a well-behaved non-compact inverse problem
Nov 16, 2022We consider the problem of learning a linear operator $\theta$ between two Hilbert spaces from empirical observations, which we interpret as least squares regression in infinite dimensions. We show that this goal can be reformulated as an inverse problem for $\theta$ with the undesirable feature that its forward operator is generally non-compact (even if $\theta$ is assumed to be compact or of $p$-Schatten class). However, we prove that, in terms of spectral properties and regularisation theory, this inverse problem is equivalent to the known compact inverse problem associated with scalar response regression. Our framework allows for the elegant derivation of dimension-free rates for generic learning algorithms under H\"older-type source conditions. The proofs rely on the combination of techniques from kernel regression with recent results on concentration of measure for sub-exponential Hilbertian random variables. The obtained rates hold for a variety of practically-relevant scenarios in functional regression as well as nonlinear regression with operator-valued kernels and match those of classical kernel regression with scalar response.
Data splitting improves statistical performance in overparametrized regimes
Oct 21, 2021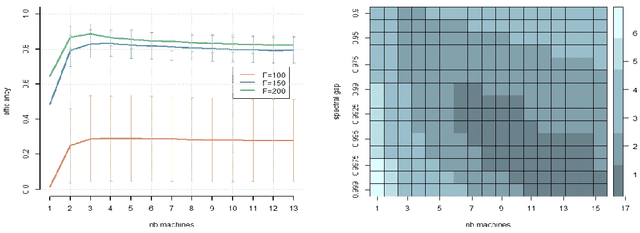
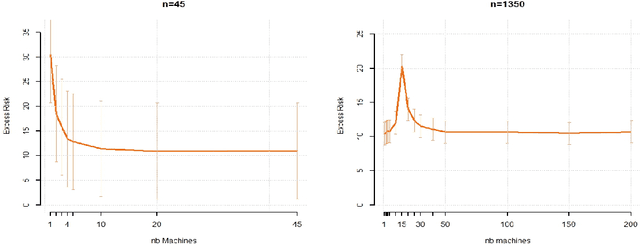
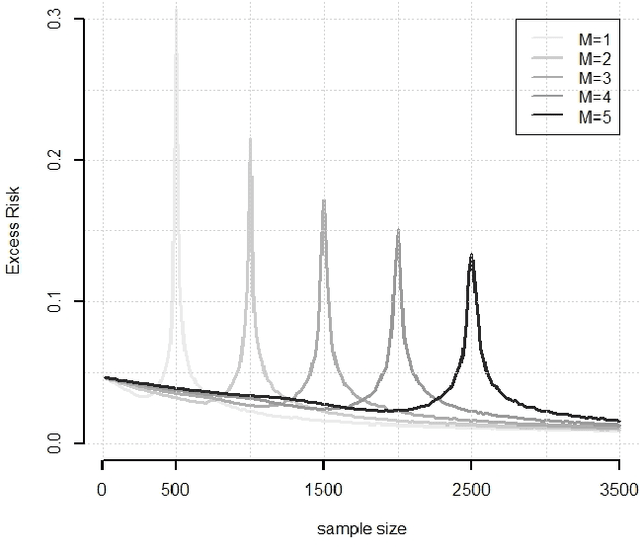
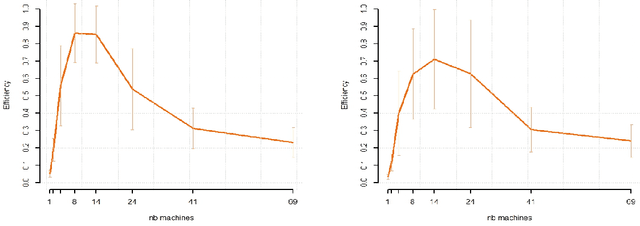
While large training datasets generally offer improvement in model performance, the training process becomes computationally expensive and time consuming. Distributed learning is a common strategy to reduce the overall training time by exploiting multiple computing devices. Recently, it has been observed in the single machine setting that overparametrization is essential for benign overfitting in ridgeless regression in Hilbert spaces. We show that in this regime, data splitting has a regularizing effect, hence improving statistical performance and computational complexity at the same time. We further provide a unified framework that allows to analyze both the finite and infinite dimensional setting. We numerically demonstrate the effect of different model parameters.
From inexact optimization to learning via gradient concentration
Jun 24, 2021
Optimization was recently shown to control the inductive bias in a learning process, a property referred to as implicit, or iterative regularization. The estimator obtained iteratively minimizing the training error can generalise well with no need of further penalties or constraints. In this paper, we investigate this phenomenon in the context of linear models with smooth loss functions. In particular, we investigate and propose a proof technique combining ideas from inexact optimization and probability theory, specifically gradient concentration. The proof is easy to follow and allows to obtain sharp learning bounds. More generally, it highlights a way to develop optimization results into learning guarantees.