 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData splitting improves statistical performance in overparametrized regimes
Paper and Code
Oct 21, 2021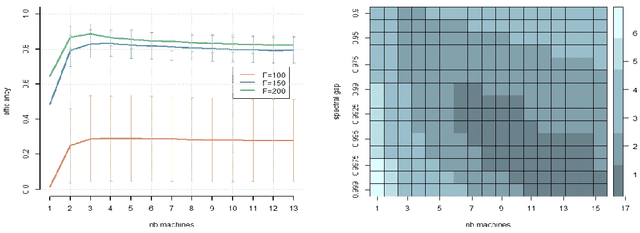
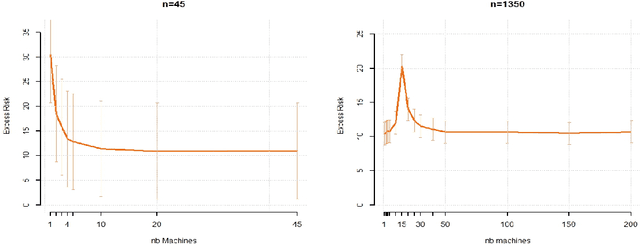
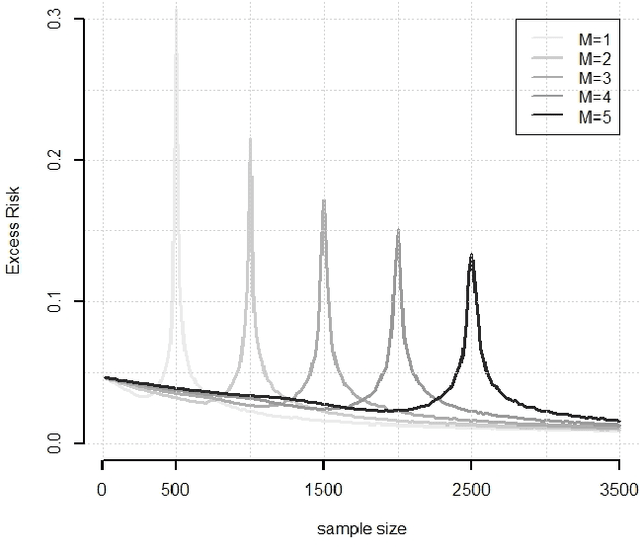
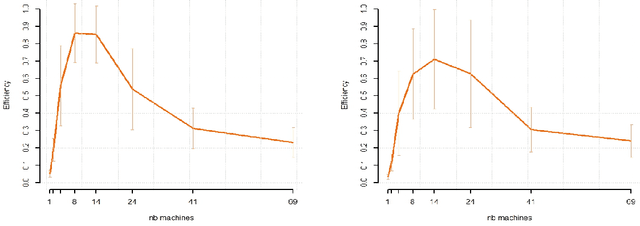
While large training datasets generally offer improvement in model performance, the training process becomes computationally expensive and time consuming. Distributed learning is a common strategy to reduce the overall training time by exploiting multiple computing devices. Recently, it has been observed in the single machine setting that overparametrization is essential for benign overfitting in ridgeless regression in Hilbert spaces. We show that in this regime, data splitting has a regularizing effect, hence improving statistical performance and computational complexity at the same time. We further provide a unified framework that allows to analyze both the finite and infinite dimensional setting. We numerically demonstrate the effect of different model parameters.