 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based diffusion models for diffuse optical tomography with uncertainty quantification
Feb 03, 2026Score-based diffusion models are a recently developed framework for posterior sampling in Bayesian inverse problems with a state-of-the-art performance for severely ill-posed problems by leveraging a powerful prior distribution learned from empirical data. Despite generating significant interest especially in the machine-learning community, a thorough study of realistic inverse problems in the presence of modelling error and utilization of physical measurement data is still outstanding. In this work, the framework of unconditional representation for the conditional score function (UCoS) is evaluated for linearized difference imaging in diffuse optical tomography (DOT). DOT uses boundary measurements of near-infrared light to estimate the spatial distribution of absorption and scattering parameters in biological tissues. The problem is highly ill-posed and thus sensitive to noise and modelling errors. We introduce a novel regularization approach that prevents overfitting of the score function by constructing a mixed score composed of a learned and a model-based component. Validation of this approach is done using both simulated and experimental measurement data. The experiments demonstrate that a data-driven prior distribution results in posterior samples with low variance, compared to classical model-based estimation, and centred around the ground truth, even in the context of a highly ill-posed problem and in the presence of modelling errors.
Approximation of differential entropy in Bayesian optimal experimental design
Oct 01, 2025Bayesian optimal experimental design provides a principled framework for selecting experimental settings that maximize obtained information. In this work, we focus on estimating the expected information gain in the setting where the differential entropy of the likelihood is either independent of the design or can be evaluated explicitly. This reduces the problem to maximum entropy estimation, alleviating several challenges inherent in expected information gain computation. Our study is motivated by large-scale inference problems, such as inverse problems, where the computational cost is dominated by expensive likelihood evaluations. We propose a computational approach in which the evidence density is approximated by a Monte Carlo or quasi-Monte Carlo surrogate, while the differential entropy is evaluated using standard methods without additional likelihood evaluations. We prove that this strategy achieves convergence rates that are comparable to, or better than, state-of-the-art methods for full expected information gain estimation, particularly when the cost of entropy evaluation is negligible. Moreover, our approach relies only on mild smoothness of the forward map and avoids stronger technical assumptions required in earlier work. We also present numerical experiments, which confirm our theoretical findings.
Gradient-Based Non-Linear Inverse Learning
Dec 21, 2024We study statistical inverse learning in the context of nonlinear inverse problems under random design. Specifically, we address a class of nonlinear problems by employing gradient descent (GD) and stochastic gradient descent (SGD) with mini-batching, both using constant step sizes. Our analysis derives convergence rates for both algorithms under classical a priori assumptions on the smoothness of the target function. These assumptions are expressed in terms of the integral operator associated with the tangent kernel, as well as through a bound on the effective dimension. Additionally, we establish stopping times that yield minimax-optimal convergence rates within the classical reproducing kernel Hilbert space (RKHS) framework. These results demonstrate the efficacy of GD and SGD in achieving optimal rates for nonlinear inverse problems in random design.
Learning sparsity-promoting regularizers for linear inverse problems
Dec 20, 2024This paper introduces a novel approach to learning sparsity-promoting regularizers for solving linear inverse problems. We develop a bilevel optimization framework to select an optimal synthesis operator, denoted as $B$, which regularizes the inverse problem while promoting sparsity in the solution. The method leverages statistical properties of the underlying data and incorporates prior knowledge through the choice of $B$. We establish the well-posedness of the optimization problem, provide theoretical guarantees for the learning process, and present sample complexity bounds. The approach is demonstrated through examples, including compact perturbations of a known operator and the problem of learning the mother wavelet, showcasing its flexibility in incorporating prior knowledge into the regularization framework. This work extends previous efforts in Tikhonov regularization by addressing non-differentiable norms and proposing a data-driven approach for sparse regularization in infinite dimensions.
Reducing the cost of posterior sampling in linear inverse problems via task-dependent score learning
May 24, 2024

Score-based diffusion models (SDMs) offer a flexible approach to sample from the posterior distribution in a variety of Bayesian inverse problems. In the literature, the prior score is utilized to sample from the posterior by different methods that require multiple evaluations of the forward mapping in order to generate a single posterior sample. These methods are often designed with the objective of enabling the direct use of the unconditional prior score and, therefore, task-independent training. In this paper, we focus on linear inverse problems, when evaluation of the forward mapping is computationally expensive and frequent posterior sampling is required for new measurement data, such as in medical imaging. We demonstrate that the evaluation of the forward mapping can be entirely bypassed during posterior sample generation. Instead, without introducing any error, the computational effort can be shifted to an offline task of training the score of a specific diffusion-like random process. In particular, the training is task-dependent requiring information about the forward mapping but not about the measurement data. It is shown that the conditional score corresponding to the posterior can be obtained from the auxiliary score by suitable affine transformations. We prove that this observation generalizes to the framework of infinite-dimensional diffusion models introduced recently and provide numerical analysis of the method. Moreover, we validate our findings with numerical experiments.
Laboratory Experiments of Model-based Reinforcement Learning for Adaptive Optics Control
Dec 30, 2023Direct imaging of Earth-like exoplanets is one of the most prominent scientific drivers of the next generation of ground-based telescopes. Typically, Earth-like exoplanets are located at small angular separations from their host stars, making their detection difficult. Consequently, the adaptive optics (AO) system's control algorithm must be carefully designed to distinguish the exoplanet from the residual light produced by the host star. A new promising avenue of research to improve AO control builds on data-driven control methods such as Reinforcement Learning (RL). RL is an active branch of the machine learning research field, where control of a system is learned through interaction with the environment. Thus, RL can be seen as an automated approach to AO control, where its usage is entirely a turnkey operation. In particular, model-based reinforcement learning (MBRL) has been shown to cope with both temporal and misregistration errors. Similarly, it has been demonstrated to adapt to non-linear wavefront sensing while being efficient in training and execution. In this work, we implement and adapt an RL method called Policy Optimization for AO (PO4AO) to the GHOST test bench at ESO headquarters, where we demonstrate a strong performance of the method in a laboratory environment. Our implementation allows the training to be performed parallel to inference, which is crucial for on-sky operation. In particular, we study the predictive and self-calibrating aspects of the method. The new implementation on GHOST running PyTorch introduces only around 700 microseconds in addition to hardware, pipeline, and Python interface latency. We open-source well-documented code for the implementation and specify the requirements for the RTC pipeline. We also discuss the important hyperparameters of the method, the source of the latency, and the possible paths for a lower latency implementation.
Statistical inverse learning problems with random observations
Dec 23, 2023We provide an overview of recent progress in statistical inverse problems with random experimental design, covering both linear and nonlinear inverse problems. Different regularization schemes have been studied to produce robust and stable solutions. We discuss recent results in spectral regularization methods and regularization by projection, exploring both approaches within the context of Hilbert scales and presenting new insights particularly in regularization by projection. Additionally, we overview recent advancements in regularization using convex penalties. Convergence rates are analyzed in terms of the sample size in a probabilistic sense, yielding minimax rates in both expectation and probability. To achieve these results, the structure of reproducing kernel Hilbert spaces is leveraged to establish minimax rates in the statistical learning setting. We detail the assumptions underpinning these key elements of our proofs. Finally, we demonstrate the application of these concepts to nonlinear inverse problems in pharmacokinetic/pharmacodynamic (PK/PD) models, where the task is to predict changes in drug concentrations in patients.
Bayesian Posterior Perturbation Analysis with Integral Probability Metrics
Mar 02, 2023In recent years, Bayesian inference in large-scale inverse problems found in science, engineering and machine learning has gained significant attention. This paper examines the robustness of the Bayesian approach by analyzing the stability of posterior measures in relation to perturbations in the likelihood potential and the prior measure. We present new stability results using a family of integral probability metrics (divergences) akin to dual problems that arise in optimal transport. Our results stand out from previous works in three directions: (1) We construct new families of integral probability metrics that are adapted to the problem at hand; (2) These new metrics allow us to study both likelihood and prior perturbations in a convenient way; and (3) our analysis accommodates likelihood potentials that are only locally Lipschitz, making them applicable to a wide range of nonlinear inverse problems. Our theoretical findings are further reinforced through specific and novel examples where the approximation rates of posterior measures are obtained for different types of perturbations and provide a path towards the convergence analysis of recently adapted machine learning techniques for Bayesian inverse problems such as data-driven priors and neural network surrogates.
Introduction To Gaussian Process Regression In Bayesian Inverse Problems, With New ResultsOn Experimental Design For Weighted Error Measures
Feb 09, 2023Bayesian posterior distributions arising in modern applications, including inverse problems in partial differential equation models in tomography and subsurface flow, are often computationally intractable due to the large computational cost of evaluating the data likelihood. To alleviate this problem, we consider using Gaussian process regression to build a surrogate model for the likelihood, resulting in an approximate posterior distribution that is amenable to computations in practice. This work serves as an introduction to Gaussian process regression, in particular in the context of building surrogate models for inverse problems, and presents new insights into a suitable choice of training points. We show that the error between the true and approximate posterior distribution can be bounded by the error between the true and approximate likelihood, measured in the $L^2$-norm weighted by the true posterior, and that efficiently bounding the error between the true and approximate likelihood in this norm suggests choosing the training points in the Gaussian process surrogate model based on the true posterior.
Convex regularization in statistical inverse learning problems
Feb 19, 2021
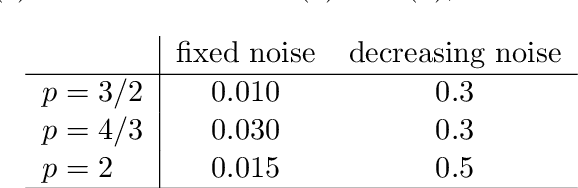

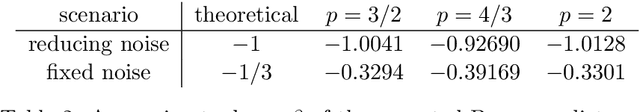
We consider a statistical inverse learning problem, where the task is to estimate a function $f$ based on noisy point evaluations of $Af$, where $A$ is a linear operator. The function $Af$ is evaluated at i.i.d. random design points $u_n$, $n=1,...,N$ generated by an unknown general probability distribution. We consider Tikhonov regularization with general convex and $p$-homogeneous penalty functionals and derive concentration rates of the regularized solution to the ground truth measured in the symmetric Bregman distance induced by the penalty functional. We derive concrete rates for Besov norm penalties and numerically demonstrate the correspondence with the observed rates in the context of X-ray tomography.