 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep unfolding of MCMC kernels: scalable, modular & explainable GANs for high-dimensional posterior sampling
Feb 24, 2026Markov chain Monte Carlo (MCMC) methods are fundamental to Bayesian computation, but can be computationally intensive, especially in high-dimensional settings. Push-forward generative models, such as generative adversarial networks (GANs), variational auto-encoders and normalising flows offer a computationally efficient alternative for posterior sampling. However, push-forward models are opaque as they lack the modularity of Bayes Theorem, leading to poor generalisation with respect to changes in the likelihood function. In this work, we introduce a novel approach to GAN architecture design by applying deep unfolding to Langevin MCMC algorithms. This paradigm maps fixed-step iterative algorithms onto modular neural networks, yielding architectures that are both flexible and amenable to interpretation. Crucially, our design allows key model parameters to be specified at inference time, offering robustness to changes in the likelihood parameters. We train these unfolded samplers end-to-end using a supervised regularized Wasserstein GAN framework for posterior sampling. Through extensive Bayesian imaging experiments, we demonstrate that our proposed approach achieves high sampling accuracy and excellent computational efficiency, while retaining the physics consistency, adaptability and interpretability of classical MCMC strategies.
Hypothesis Testing in Imaging Inverse Problems
May 28, 2025This paper proposes a framework for semantic hypothesis testing tailored to imaging inverse problems. Modern imaging methods struggle to support hypothesis testing, a core component of the scientific method that is essential for the rigorous interpretation of experiments and robust interfacing with decision-making processes. There are three main reasons why image-based hypothesis testing is challenging. First, the difficulty of using a single observation to simultaneously reconstruct an image, formulate hypotheses, and quantify their statistical significance. Second, the hypotheses encountered in imaging are mostly of semantic nature, rather than quantitative statements about pixel values. Third, it is challenging to control test error probabilities because the null and alternative distributions are often unknown. Our proposed approach addresses these difficulties by leveraging concepts from self-supervised computational imaging, vision-language models, and non-parametric hypothesis testing with e-values. We demonstrate our proposed framework through numerical experiments related to image-based phenotyping, where we achieve excellent power while robustly controlling Type I errors.
Backward error analysis and the qualitative behaviour of stochastic optimization algorithms: Application to stochastic coordinate descent
Sep 05, 2023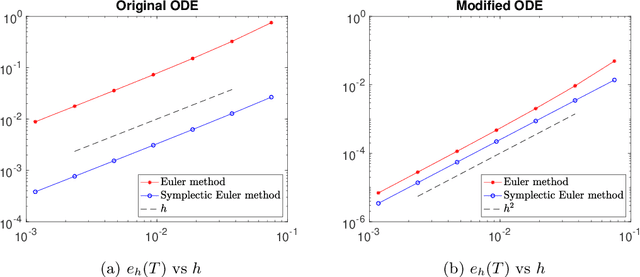
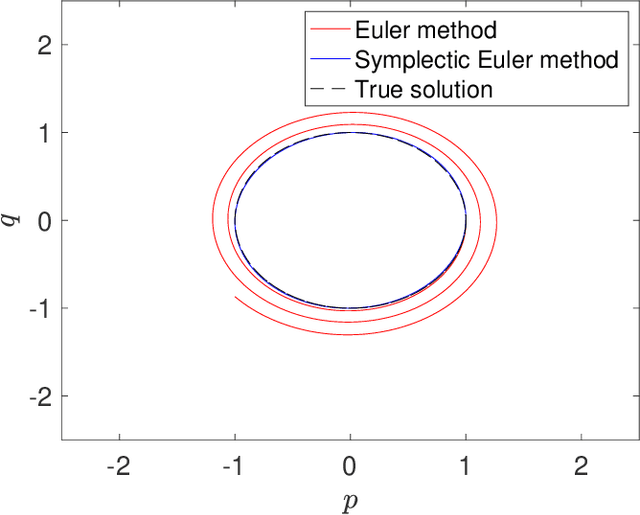
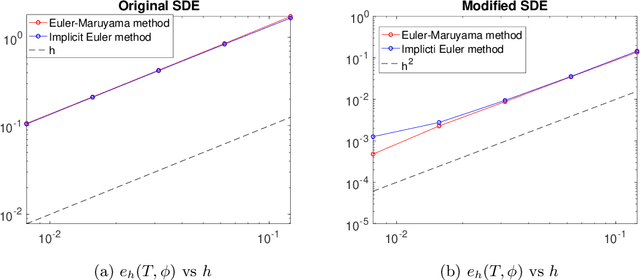
Stochastic optimization methods have been hugely successful in making large-scale optimization problems feasible when computing the full gradient is computationally prohibitive. Using the theory of modified equations for numerical integrators, we propose a class of stochastic differential equations that approximate the dynamics of general stochastic optimization methods more closely than the original gradient flow. Analyzing a modified stochastic differential equation can reveal qualitative insights about the associated optimization method. Here, we study mean-square stability of the modified equation in the case of stochastic coordinate descent.
On the connections between optimization algorithms, Lyapunov functions, and differential equations: theory and insights
May 15, 2023

We study connections between differential equations and optimization algorithms for $m$-strongly and $L$-smooth convex functions through the use of Lyapunov functions by generalizing the Linear Matrix Inequality framework developed by Fazylab et al. in 2018. Using the new framework we derive analytically a new (discrete) Lyapunov function for a two-parameter family of Nesterov optimization methods and characterize their convergence rate. This allows us to prove a convergence rate that improves substantially on the previously proven rate of Nesterov's method for the standard choice of coefficients, as well as to characterize the choice of coefficients that yields the optimal rate. We obtain a new Lyapunov function for the Polyak ODE and revisit the connection between this ODE and the Nesterov's algorithms. In addition discuss a new interpretation of Nesterov method as an additive Runge-Kutta discretization and explain the structural conditions that discretizations of the Polyak equation should satisfy in order to lead to accelerated optimization algorithms.
Introduction To Gaussian Process Regression In Bayesian Inverse Problems, With New ResultsOn Experimental Design For Weighted Error Measures
Feb 09, 2023Bayesian posterior distributions arising in modern applications, including inverse problems in partial differential equation models in tomography and subsurface flow, are often computationally intractable due to the large computational cost of evaluating the data likelihood. To alleviate this problem, we consider using Gaussian process regression to build a surrogate model for the likelihood, resulting in an approximate posterior distribution that is amenable to computations in practice. This work serves as an introduction to Gaussian process regression, in particular in the context of building surrogate models for inverse problems, and presents new insights into a suitable choice of training points. We show that the error between the true and approximate posterior distribution can be bounded by the error between the true and approximate likelihood, measured in the $L^2$-norm weighted by the true posterior, and that efficiently bounding the error between the true and approximate likelihood in this norm suggests choosing the training points in the Gaussian process surrogate model based on the true posterior.
Batch Bayesian Optimization via Particle Gradient Flows
Sep 10, 2022
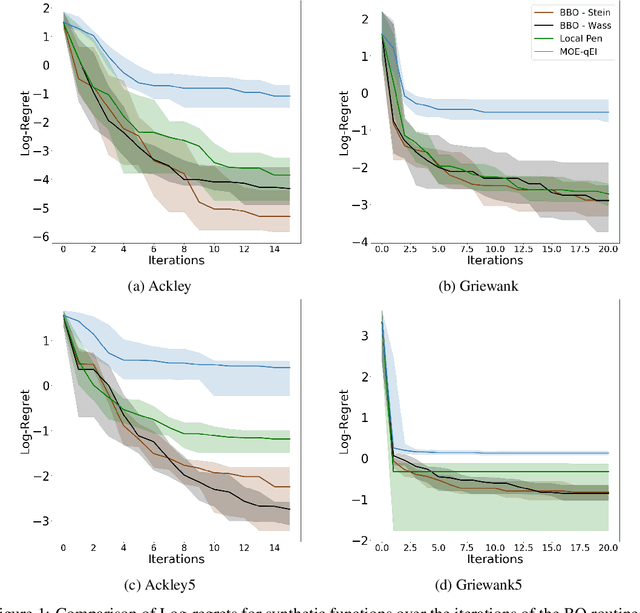
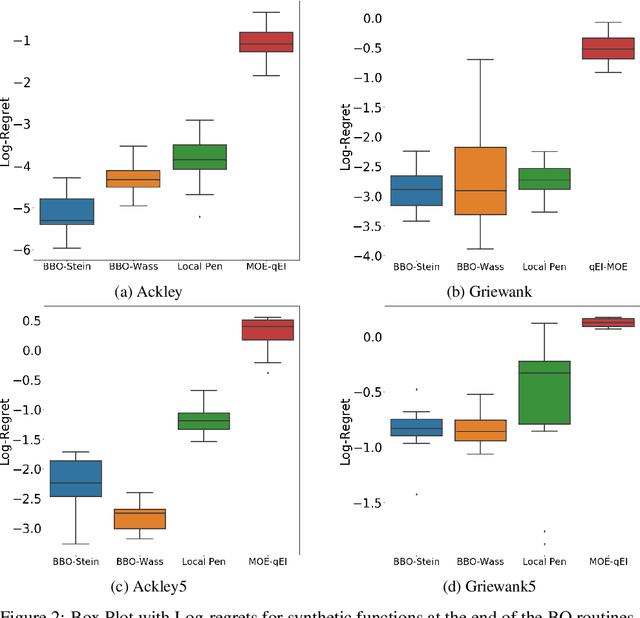
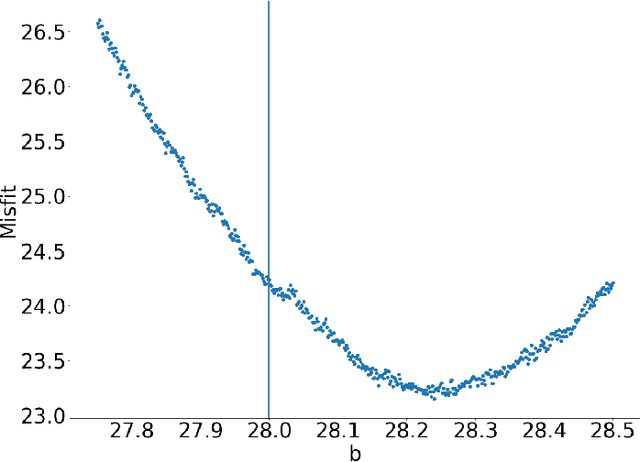
Bayesian Optimisation (BO) methods seek to find global optima of objective functions which are only available as a black-box or are expensive to evaluate. Such methods construct a surrogate model for the objective function, quantifying the uncertainty in that surrogate through Bayesian inference. Objective evaluations are sequentially determined by maximising an acquisition function at each step. However, this ancilliary optimisation problem can be highly non-trivial to solve, due to the non-convexity of the acquisition function, particularly in the case of batch Bayesian optimisation, where multiple points are selected in every step. In this work we reformulate batch BO as an optimisation problem over the space of probability measures. We construct a new acquisition function based on multipoint expected improvement which is convex over the space of probability measures. Practical schemes for solving this `inner' optimisation problem arise naturally as gradient flows of this objective function. We demonstrate the efficacy of this new method on different benchmark functions and compare with state-of-the-art batch BO methods.
Probabilistic Linear Multistep Methods
Oct 26, 2016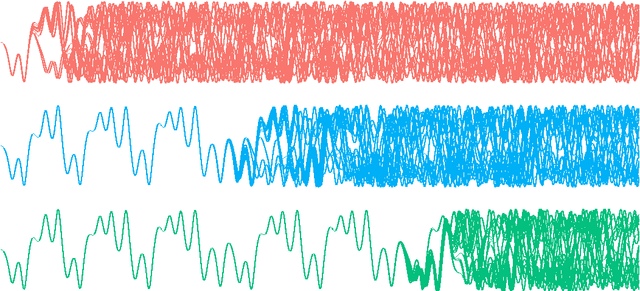
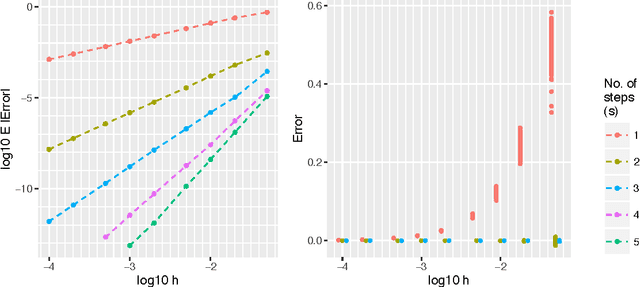
We present a derivation and theoretical investigation of the Adams-Bashforth and Adams-Moulton family of linear multistep methods for solving ordinary differential equations, starting from a Gaussian process (GP) framework. In the limit, this formulation coincides with the classical deterministic methods, which have been used as higher-order initial value problem solvers for over a century. Furthermore, the natural probabilistic framework provided by the GP formulation allows us to derive probabilistic versions of these methods, in the spirit of a number of other probabilistic ODE solvers presented in the recent literature. In contrast to higher-order Runge-Kutta methods, which require multiple intermediate function evaluations per step, Adams family methods make use of previous function evaluations, so that increased accuracy arising from a higher-order multistep approach comes at very little additional computational cost. We show that through a careful choice of covariance function for the GP, the posterior mean and standard deviation over the numerical solution can be made to exactly coincide with the value given by the deterministic method and its local truncation error respectively. We provide a rigorous proof of the convergence of these new methods, as well as an empirical investigation (up to fifth order) demonstrating their convergence rates in practice.
* 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain
Multilevel Monte Carlo for Scalable Bayesian Computations
Sep 15, 2016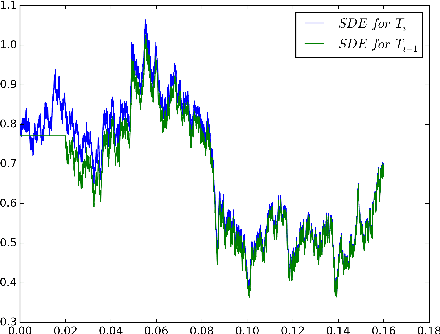
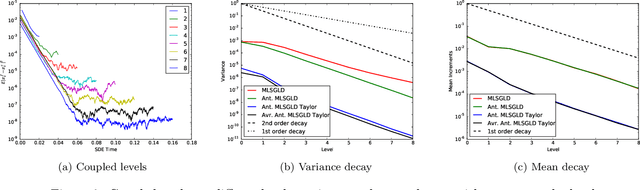
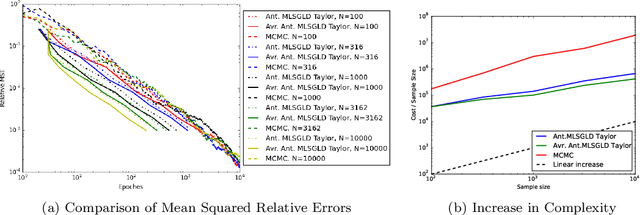
Markov chain Monte Carlo (MCMC) algorithms are ubiquitous in Bayesian computations. However, they need to access the full data set in order to evaluate the posterior density at every step of the algorithm. This results in a great computational burden in big data applications. In contrast to MCMC methods, Stochastic Gradient MCMC (SGMCMC) algorithms such as the Stochastic Gradient Langevin Dynamics (SGLD) only require access to a batch of the data set at every step. This drastically improves the computational performance and scales well to large data sets. However, the difficulty with SGMCMC algorithms comes from the sensitivity to its parameters which are notoriously difficult to tune. Moreover, the Root Mean Square Error (RMSE) scales as $\mathcal{O}(c^{-\frac{1}{3}})$ as opposed to standard MCMC $\mathcal{O}(c^{-\frac{1}{2}})$ where $c$ is the computational cost. We introduce a new class of Multilevel Stochastic Gradient Markov chain Monte Carlo algorithms that are able to mitigate the problem of tuning the step size and more importantly of recovering the $\mathcal{O}(c^{-\frac{1}{2}})$ convergence of standard Markov Chain Monte Carlo methods without the need to introduce Metropolis-Hasting steps. A further advantage of this new class of algorithms is that it can easily be parallelised over a heterogeneous computer architecture. We illustrate our methodology using Bayesian logistic regression and provide numerical evidence that for a prescribed relative RMSE the computational cost is sublinear in the number of data items.
Multi Level Monte Carlo methods for a class of ergodic stochastic differential equations
Jul 31, 2016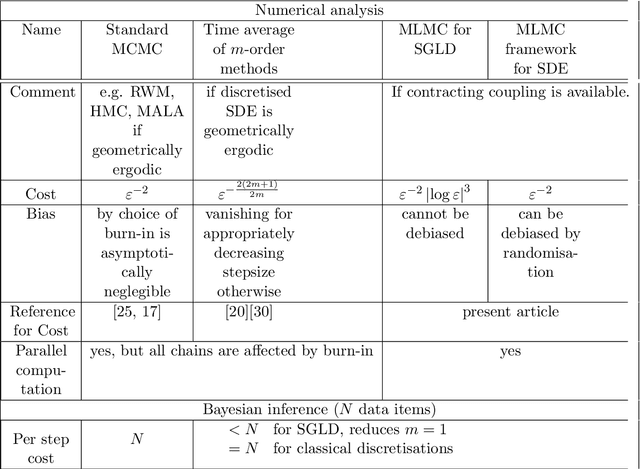

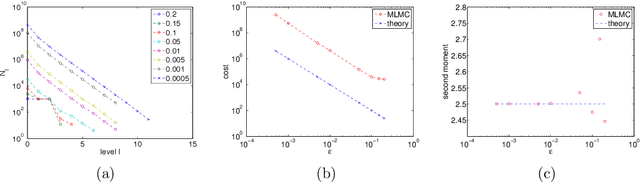
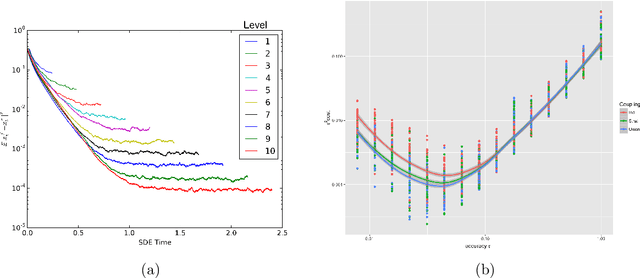
We develop a framework that allows the use of the multi-level Monte Carlo (MLMC) methodology (Giles 2015) to calculate expectations with respect to the invariant measures of ergodic SDEs. In that context, we study the (over-damped) Langevin equations with strongly convex potential. We show that, when appropriate contracting couplings for the numerical integrators are available, one can obtain a time-uniform estimates of the MLMC variance in stark contrast to the majority of the results in the MLMC literature. As a consequence, one can approximate expectations with respect to the invariant measure in an unbiased way without the need of a Metropolis- Hastings step. In addition, a root mean square error of $\mathcal{O}(\epsilon)$ is achieved with $\mathcal{O}(\epsilon^{-2})$ complexity on par with Markov Chain Monte Carlo (MCMC) methods, which however can be computationally intensive when applied to large data sets. Finally, we present a multilevel version of the recently introduced Stochastic Gradient Langevin (SGLD) method (Welling and Teh, 2011) built for large datasets applications. We show that this is the first stochastic gradient MCMC method with complexity $\mathcal{O}(\epsilon^{-2}|\log {\epsilon}|^{3})$, which is asymptotically an order $\epsilon$ lower than the $ \mathcal{O}(\epsilon^{-3})$ complexity of all stochastic gradient MCMC methods that are currently available. Numerical experiments confirm our theoretical findings.