 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching for Atmospheric Retrieval of Exoplanets: Where Reliability meets Adaptive Noise Levels
Oct 28, 2024



Inferring atmospheric properties of exoplanets from observed spectra is key to understanding their formation, evolution, and habitability. Since traditional Bayesian approaches to atmospheric retrieval (e.g., nested sampling) are computationally expensive, a growing number of machine learning (ML) methods such as neural posterior estimation (NPE) have been proposed. We seek to make ML-based atmospheric retrieval (1) more reliable and accurate with verified results, and (2) more flexible with respect to the underlying neural networks and the choice of the assumed noise models. First, we adopt flow matching posterior estimation (FMPE) as a new ML approach to atmospheric retrieval. FMPE maintains many advantages of NPE, but provides greater architectural flexibility and scalability. Second, we use importance sampling (IS) to verify and correct ML results, and to compute an estimate of the Bayesian evidence. Third, we condition our ML models on the assumed noise level of a spectrum (i.e., error bars), thus making them adaptable to different noise models. Both our noise level-conditional FMPE and NPE models perform on par with nested sampling across a range of noise levels when tested on simulated data. FMPE trains about 3 times faster than NPE and yields higher IS efficiencies. IS successfully corrects inaccurate ML results, identifies model failures via low efficiencies, and provides accurate estimates of the Bayesian evidence. FMPE is a powerful alternative to NPE for fast, amortized, and parallelizable atmospheric retrieval. IS can verify results, thus helping to build confidence in ML-based approaches, while also facilitating model comparison via the evidence ratio. Noise level conditioning allows design studies for future instruments to be scaled up, for example, in terms of the range of signal-to-noise ratios.
Laboratory Experiments of Model-based Reinforcement Learning for Adaptive Optics Control
Dec 30, 2023Direct imaging of Earth-like exoplanets is one of the most prominent scientific drivers of the next generation of ground-based telescopes. Typically, Earth-like exoplanets are located at small angular separations from their host stars, making their detection difficult. Consequently, the adaptive optics (AO) system's control algorithm must be carefully designed to distinguish the exoplanet from the residual light produced by the host star. A new promising avenue of research to improve AO control builds on data-driven control methods such as Reinforcement Learning (RL). RL is an active branch of the machine learning research field, where control of a system is learned through interaction with the environment. Thus, RL can be seen as an automated approach to AO control, where its usage is entirely a turnkey operation. In particular, model-based reinforcement learning (MBRL) has been shown to cope with both temporal and misregistration errors. Similarly, it has been demonstrated to adapt to non-linear wavefront sensing while being efficient in training and execution. In this work, we implement and adapt an RL method called Policy Optimization for AO (PO4AO) to the GHOST test bench at ESO headquarters, where we demonstrate a strong performance of the method in a laboratory environment. Our implementation allows the training to be performed parallel to inference, which is crucial for on-sky operation. In particular, we study the predictive and self-calibrating aspects of the method. The new implementation on GHOST running PyTorch introduces only around 700 microseconds in addition to hardware, pipeline, and Python interface latency. We open-source well-documented code for the implementation and specify the requirements for the RTC pipeline. We also discuss the important hyperparameters of the method, the source of the latency, and the possible paths for a lower latency implementation.
Inferring Atmospheric Properties of Exoplanets with Flow Matching and Neural Importance Sampling
Dec 13, 2023



Atmospheric retrievals (AR) characterize exoplanets by estimating atmospheric parameters from observed light spectra, typically by framing the task as a Bayesian inference problem. However, traditional approaches such as nested sampling are computationally expensive, thus sparking an interest in solutions based on machine learning (ML). In this ongoing work, we first explore flow matching posterior estimation (FMPE) as a new ML-based method for AR and find that, in our case, it is more accurate than neural posterior estimation (NPE), but less accurate than nested sampling. We then combine both FMPE and NPE with importance sampling, in which case both methods outperform nested sampling in terms of accuracy and simulation efficiency. Going forward, our analysis suggests that simulation-based inference with likelihood-based importance sampling provides a framework for accurate and efficient AR that may become a valuable tool not only for the analysis of observational data from existing telescopes, but also for the development of new missions and instruments.
Parameterizing pressure-temperature profiles of exoplanet atmospheres with neural networks
Sep 06, 2023Atmospheric retrievals (AR) of exoplanets typically rely on a combination of a Bayesian inference technique and a forward simulator to estimate atmospheric properties from an observed spectrum. A key component in simulating spectra is the pressure-temperature (PT) profile, which describes the thermal structure of the atmosphere. Current AR pipelines commonly use ad hoc fitting functions here that limit the retrieved PT profiles to simple approximations, but still use a relatively large number of parameters. In this work, we introduce a conceptually new, data-driven parameterization scheme for physically consistent PT profiles that does not require explicit assumptions about the functional form of the PT profiles and uses fewer parameters than existing methods. Our approach consists of a latent variable model (based on a neural network) that learns a distribution over functions (PT profiles). Each profile is represented by a low-dimensional vector that can be used to condition a decoder network that maps $P$ to $T$. When training and evaluating our method on two publicly available datasets of self-consistent PT profiles, we find that our method achieves, on average, better fit quality than existing baseline methods, despite using fewer parameters. In an AR based on existing literature, our model (using two parameters) produces a tighter, more accurate posterior for the PT profile than the five-parameter polynomial baseline, while also speeding up the retrieval by more than a factor of three. By providing parametric access to physically consistent PT profiles, and by reducing the number of parameters required to describe a PT profile (thereby reducing computational cost or freeing resources for additional parameters of interest), our method can help improve AR and thus our understanding of exoplanet atmospheres and their habitability.
Half-sibling regression meets exoplanet imaging: PSF modeling and subtraction using a flexible, domain knowledge-driven, causal framework
Apr 07, 2022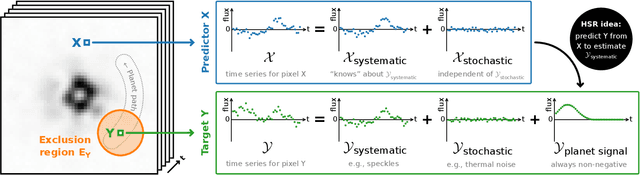
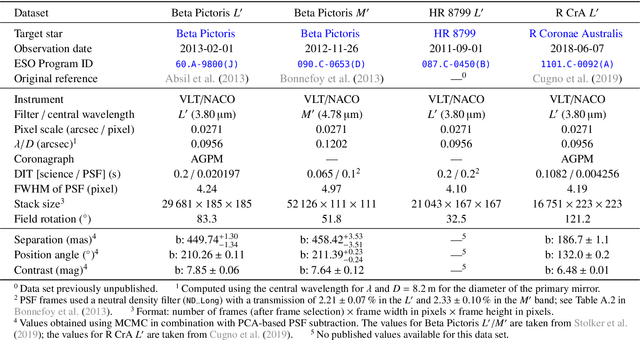
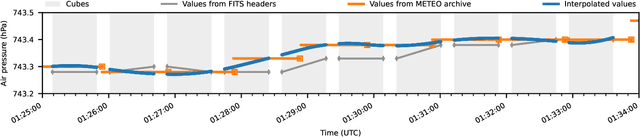
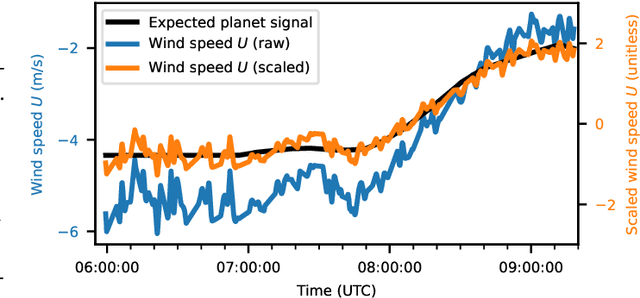
High-contrast imaging of exoplanets hinges on powerful post-processing methods to denoise the data and separate the signal of a companion from its host star, which is typically orders of magnitude brighter. Existing post-processing algorithms do not use all prior domain knowledge that is available about the problem. We propose a new method that builds on our understanding of the systematic noise and the causal structure of the data-generating process. Our algorithm is based on a modified version of half-sibling regression (HSR), a flexible denoising framework that combines ideas from the fields of machine learning and causality. We adapt the method to address the specific requirements of high-contrast exoplanet imaging data obtained in pupil tracking mode. The key idea is to estimate the systematic noise in a pixel by regressing the time series of this pixel onto a set of causally independent, signal-free predictor pixels. We use regularized linear models in this work; however, other (non-linear) models are also possible. In a second step, we demonstrate how the HSR framework allows us to incorporate observing conditions such as wind speed or air temperature as additional predictors. When we apply our method to four data sets from the VLT/NACO instrument, our algorithm provides a better false-positive fraction than PCA-based PSF subtraction, a popular baseline method in the field. Additionally, we find that the HSR-based method provides direct and accurate estimates for the contrast of the exoplanets without the need to insert artificial companions for calibration in the data sets. Finally, we present first evidence that using the observing conditions as additional predictors can improve the results. Our HSR-based method provides an alternative, flexible and promising approach to the challenge of modeling and subtracting the stellar PSF and systematic noise in exoplanet imaging data.
Physically constrained causal noise models for high-contrast imaging of exoplanets
Oct 12, 2020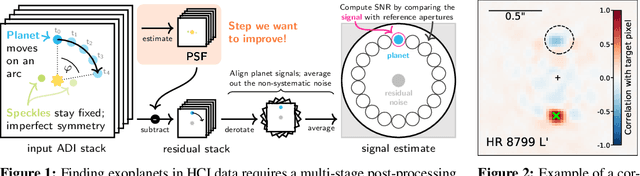


The detection of exoplanets in high-contrast imaging (HCI) data hinges on post-processing methods to remove spurious light from the host star. So far, existing methods for this task hardly utilize any of the available domain knowledge about the problem explicitly. We propose a new approach to HCI post-processing based on a modified half-sibling regression scheme, and show how we use this framework to combine machine learning with existing scientific domain knowledge. On three real data sets, we demonstrate that the resulting system performs up to a factor of 4 times better than one of the currently leading algorithms. This has the potential to allow significant discoveries of exoplanets both in new and archival data.