 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching for Atmospheric Retrieval of Exoplanets: Where Reliability meets Adaptive Noise Levels
Oct 28, 2024



Inferring atmospheric properties of exoplanets from observed spectra is key to understanding their formation, evolution, and habitability. Since traditional Bayesian approaches to atmospheric retrieval (e.g., nested sampling) are computationally expensive, a growing number of machine learning (ML) methods such as neural posterior estimation (NPE) have been proposed. We seek to make ML-based atmospheric retrieval (1) more reliable and accurate with verified results, and (2) more flexible with respect to the underlying neural networks and the choice of the assumed noise models. First, we adopt flow matching posterior estimation (FMPE) as a new ML approach to atmospheric retrieval. FMPE maintains many advantages of NPE, but provides greater architectural flexibility and scalability. Second, we use importance sampling (IS) to verify and correct ML results, and to compute an estimate of the Bayesian evidence. Third, we condition our ML models on the assumed noise level of a spectrum (i.e., error bars), thus making them adaptable to different noise models. Both our noise level-conditional FMPE and NPE models perform on par with nested sampling across a range of noise levels when tested on simulated data. FMPE trains about 3 times faster than NPE and yields higher IS efficiencies. IS successfully corrects inaccurate ML results, identifies model failures via low efficiencies, and provides accurate estimates of the Bayesian evidence. FMPE is a powerful alternative to NPE for fast, amortized, and parallelizable atmospheric retrieval. IS can verify results, thus helping to build confidence in ML-based approaches, while also facilitating model comparison via the evidence ratio. Noise level conditioning allows design studies for future instruments to be scaled up, for example, in terms of the range of signal-to-noise ratios.
Inferring Atmospheric Properties of Exoplanets with Flow Matching and Neural Importance Sampling
Dec 13, 2023



Atmospheric retrievals (AR) characterize exoplanets by estimating atmospheric parameters from observed light spectra, typically by framing the task as a Bayesian inference problem. However, traditional approaches such as nested sampling are computationally expensive, thus sparking an interest in solutions based on machine learning (ML). In this ongoing work, we first explore flow matching posterior estimation (FMPE) as a new ML-based method for AR and find that, in our case, it is more accurate than neural posterior estimation (NPE), but less accurate than nested sampling. We then combine both FMPE and NPE with importance sampling, in which case both methods outperform nested sampling in terms of accuracy and simulation efficiency. Going forward, our analysis suggests that simulation-based inference with likelihood-based importance sampling provides a framework for accurate and efficient AR that may become a valuable tool not only for the analysis of observational data from existing telescopes, but also for the development of new missions and instruments.
Parameterizing pressure-temperature profiles of exoplanet atmospheres with neural networks
Sep 06, 2023Atmospheric retrievals (AR) of exoplanets typically rely on a combination of a Bayesian inference technique and a forward simulator to estimate atmospheric properties from an observed spectrum. A key component in simulating spectra is the pressure-temperature (PT) profile, which describes the thermal structure of the atmosphere. Current AR pipelines commonly use ad hoc fitting functions here that limit the retrieved PT profiles to simple approximations, but still use a relatively large number of parameters. In this work, we introduce a conceptually new, data-driven parameterization scheme for physically consistent PT profiles that does not require explicit assumptions about the functional form of the PT profiles and uses fewer parameters than existing methods. Our approach consists of a latent variable model (based on a neural network) that learns a distribution over functions (PT profiles). Each profile is represented by a low-dimensional vector that can be used to condition a decoder network that maps $P$ to $T$. When training and evaluating our method on two publicly available datasets of self-consistent PT profiles, we find that our method achieves, on average, better fit quality than existing baseline methods, despite using fewer parameters. In an AR based on existing literature, our model (using two parameters) produces a tighter, more accurate posterior for the PT profile than the five-parameter polynomial baseline, while also speeding up the retrieval by more than a factor of three. By providing parametric access to physically consistent PT profiles, and by reducing the number of parameters required to describe a PT profile (thereby reducing computational cost or freeing resources for additional parameters of interest), our method can help improve AR and thus our understanding of exoplanet atmospheres and their habitability.
Unsupervised Distribution Learning for Lunar Surface Anomaly Detection
Jan 14, 2020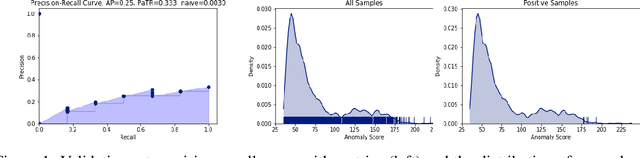
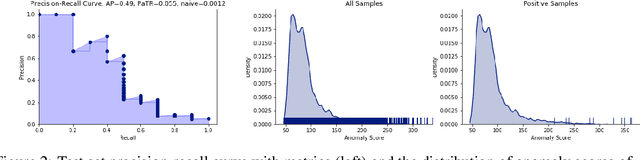

In this work we show that modern data-driven machine learning techniques can be successfully applied on lunar surface remote sensing data to learn, in an unsupervised way, sufficiently good representations of the data distribution to enable lunar technosignature and anomaly detection. In particular we train an unsupervised distribution learning neural network model to find the Apollo 15 landing module in a testing dataset, with no dataset specific model or hyperparameter tuning. Sufficiently good unsupervised data density estimation has the promise of enabling myriad useful downstream tasks, including locating lunar resources for future space flight and colonization, finding new impact craters or lunar surface reshaping, and algorithmically deciding the importance of unlabeled samples to send back from power- and bandwidth-constrained missions. We show in this work that such unsupervised learning can be successfully done in the lunar remote sensing and space science contexts.
An Ensemble of Bayesian Neural Networks for Exoplanetary Atmospheric Retrieval
May 25, 2019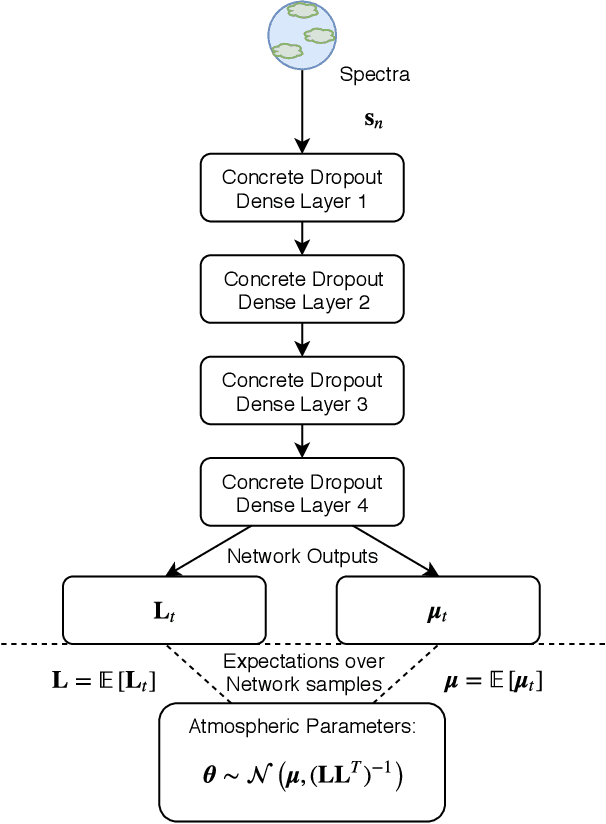
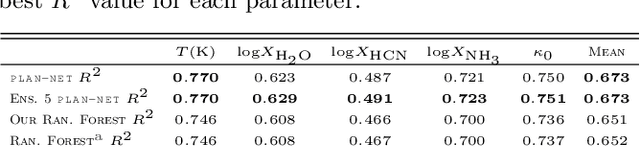
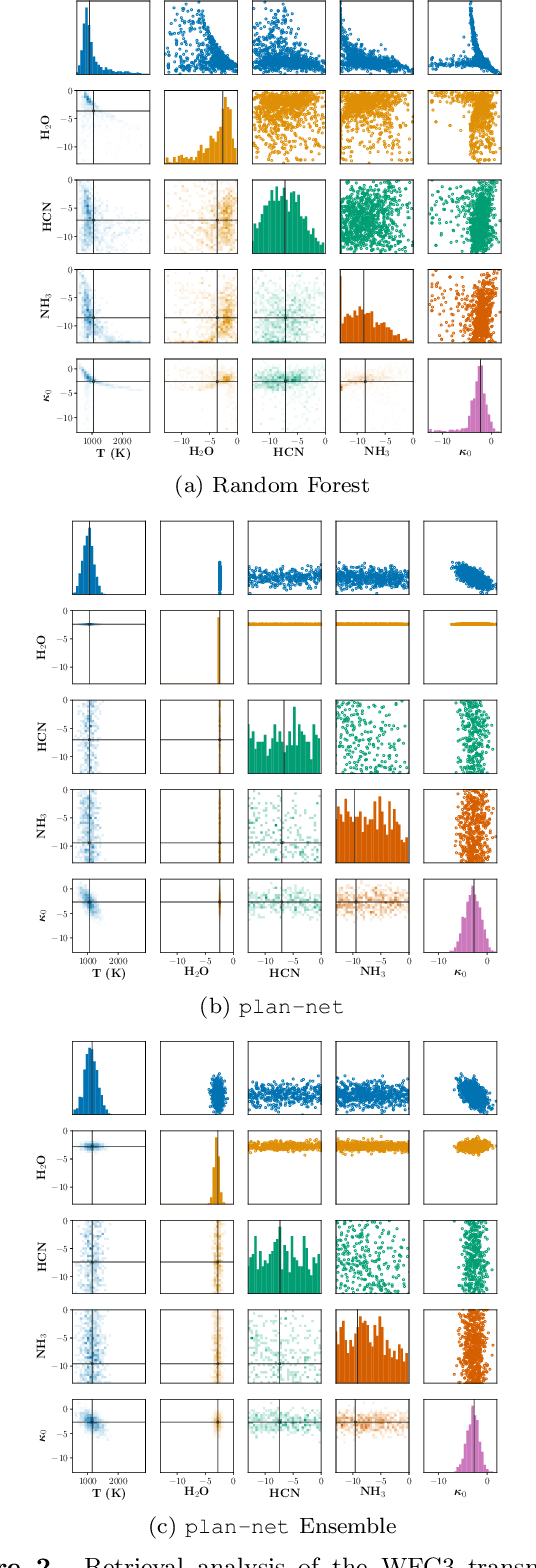

Machine learning is now used in many areas of astrophysics, from detecting exoplanets in Kepler transit signals to removing telescope systematics. Recent work demonstrated the potential of using machine learning algorithms for atmospheric retrieval by implementing a random forest to perform retrievals in seconds that are consistent with the traditional, computationally-expensive nested-sampling retrieval method. We expand upon their approach by presenting a new machine learning model, \texttt{plan-net}, based on an ensemble of Bayesian neural networks that yields more accurate inferences than the random forest for the same data set of synthetic transmission spectra. We demonstrate that an ensemble provides greater accuracy and more robust uncertainties than a single model. In addition to being the first to use Bayesian neural networks for atmospheric retrieval, we also introduce a new loss function for Bayesian neural networks that learns correlations between the model outputs. Importantly, we show that designing machine learning models to explicitly incorporate domain-specific knowledge both improves performance and provides additional insight by inferring the covariance of the retrieved atmospheric parameters. We apply \texttt{plan-net} to the Hubble Space Telescope Wide Field Camera 3 transmission spectrum for WASP-12b and retrieve an isothermal temperature and water abundance consistent with the literature. We highlight that our method is flexible and can be expanded to higher-resolution spectra and a larger number of atmospheric parameters.
Bayesian Deep Learning for Exoplanet Atmospheric Retrieval
Dec 02, 2018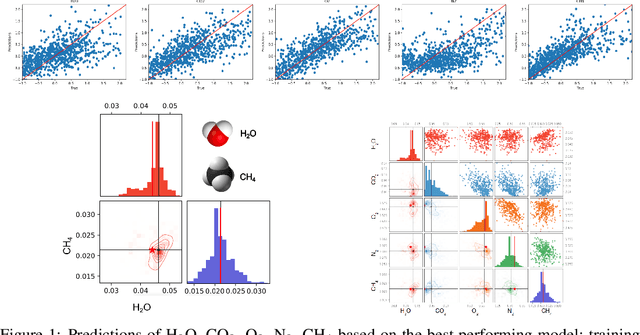

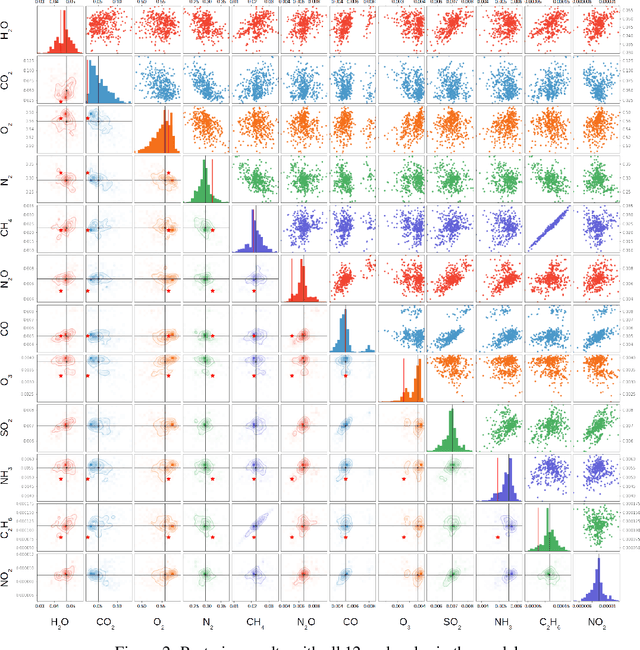
Over the past decade, the study of extrasolar planets has evolved rapidly from plain detection and identification to comprehensive categorization and characterization of exoplanet systems and their atmospheres. Atmospheric retrieval, the inverse modeling technique used to determine an exoplanetary atmosphere's temperature structure and composition from an observed spectrum, is both time-consuming and compute-intensive, requiring complex algorithms that compare thousands to millions of atmospheric models to the observational data to find the most probable values and associated uncertainties for each model parameter. For rocky, terrestrial planets, the retrieved atmospheric composition can give insight into the surface fluxes of gaseous species necessary to maintain the stability of that atmosphere, which may in turn provide insight into the geological and/or biological processes active on the planet. These atmospheres contain many molecules, some of them biosignatures, spectral fingerprints indicative of biological activity, which will become observable with the next generation of telescopes. Runtimes of traditional retrieval models scale with the number of model parameters, so as more molecular species are considered, runtimes can become prohibitively long. Recent advances in machine learning (ML) and computer vision offer new ways to reduce the time to perform a retrieval by orders of magnitude, given a sufficient data set to train with. Here we present an ML-based retrieval framework called Intelligent exoplaNet Atmospheric RetrievAl (INARA) that consists of a Bayesian deep learning model for retrieval and a data set of 3,000,000 synthetic rocky exoplanetary spectra generated using the NASA Planetary Spectrum Generator. Our work represents the first ML retrieval model for rocky, terrestrial exoplanets and the first synthetic data set of terrestrial spectra generated at this scale.