 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limits of Synthetic Creation of Solar EUV Images via Image-to-Image Translation
Aug 19, 2022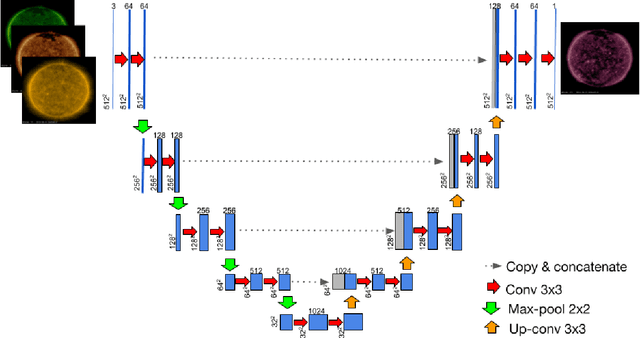
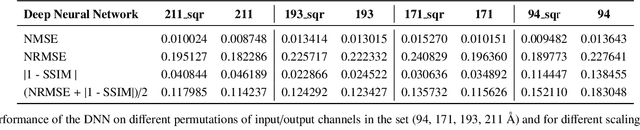

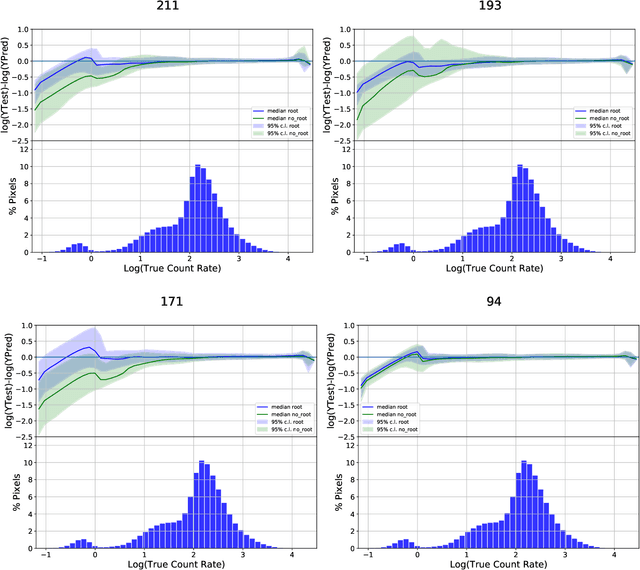
The Solar Dynamics Observatory (SDO), a NASA multi-spectral decade-long mission that has been daily producing terabytes of observational data from the Sun, has been recently used as a use-case to demonstrate the potential of machine learning methodologies and to pave the way for future deep-space mission planning. In particular, the idea of using image-to-image translation to virtually produce extreme ultra-violet channels has been proposed in several recent studies, as a way to both enhance missions with less available channels and to alleviate the challenges due to the low downlink rate in deep space. This paper investigates the potential and the limitations of such a deep learning approach by focusing on the permutation of four channels and an encoder--decoder based architecture, with particular attention to how morphological traits and brightness of the solar surface affect the neural network predictions. In this work we want to answer the question: can synthetic images of the solar corona produced via image-to-image translation be used for scientific studies of the Sun? The analysis highlights that the neural network produces high-quality images over three orders of magnitude in count rate (pixel intensity) and can generally reproduce the covariance across channels within a 1% error. However the model performance drastically diminishes in correspondence of extremely high energetic events like flares, and we argue that the reason is related to the rareness of such events posing a challenge to model training.
Auto-Calibration of Remote Sensing Solar Telescopes with Deep Learning
Nov 10, 2019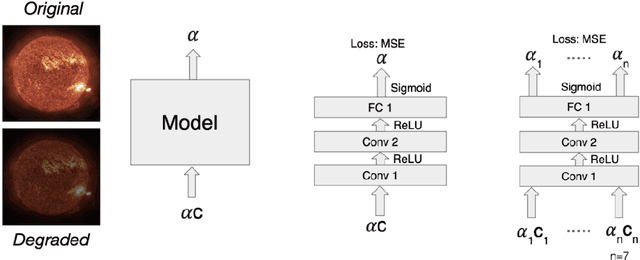
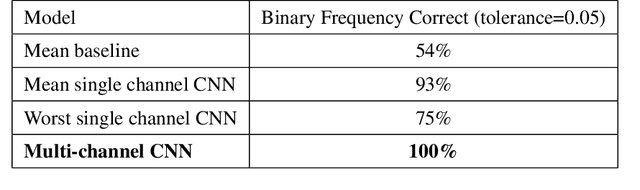

As a part of NASA's Heliophysics System Observatory (HSO) fleet of satellites,the Solar Dynamics Observatory (SDO) has continuously monitored the Sun since2010. Ultraviolet (UV) and Extreme UV (EUV) instruments in orbit, such asSDO's Atmospheric Imaging Assembly (AIA) instrument, suffer time-dependent degradation which reduces instrument sensitivity. Accurate calibration for (E)UV instruments currently depends on periodic sounding rockets, which are infrequent and not practical for heliophysics missions in deep space. In the present work, we develop a Convolutional Neural Network (CNN) that auto-calibrates SDO/AIA channels and corrects sensitivity degradation by exploiting spatial patterns in multi-wavelength observations to arrive at a self-calibration of (E)UV imaging instruments. Our results remove a major impediment to developing future HSOmissions of the same scientific caliber as SDO but in deep space, able to observe the Sun from more vantage points than just SDO's current geosynchronous orbit.This approach can be adopted to perform autocalibration of other imaging systems exhibiting similar forms of degradation
Using U-Nets to Create High-Fidelity Virtual Observations of the Solar Corona
Nov 10, 2019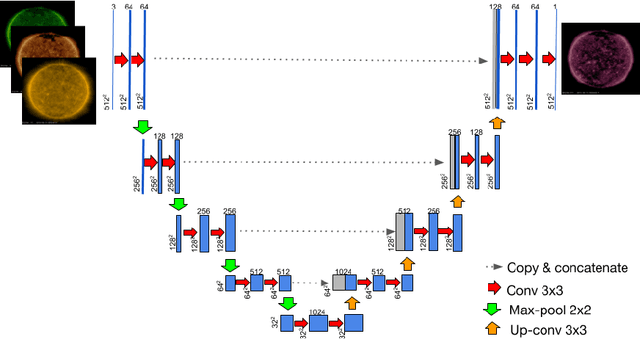

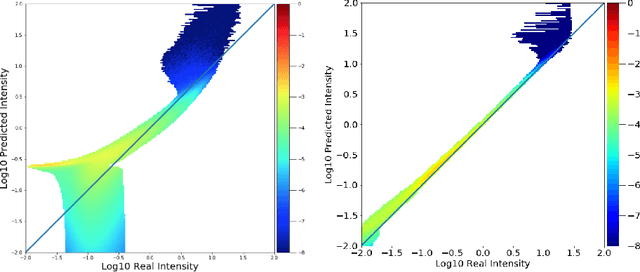
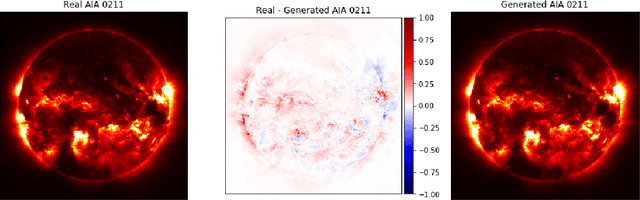
Understanding and monitoring the complex and dynamic processes of the Sun is important for a number of human activities on Earth and in space. For this reason, NASA's Solar Dynamics Observatory (SDO) has been continuously monitoring the multi-layered Sun's atmosphere in high-resolution since its launch in 2010, generating terabytes of observational data every day. The synergy between machine learning and this enormous amount of data has the potential, still largely unexploited, to advance our understanding of the Sun and extend the capabilities of heliophysics missions. In the present work, we show that deep learning applied to SDO data can be successfully used to create a high-fidelity virtual telescope that generates synthetic observations of the solar corona by image translation. Towards this end we developed a deep neural network, structured as an encoder-decoder with skip connections (U-Net), that reconstructs the Sun's image of one instrument channel given temporally aligned images in three other channels. The approach we present has the potential to reduce the telemetry needs of SDO, enhance the capabilities of missions that have less observing channels, and transform the concept development of future missions.
Bayesian Deep Learning for Exoplanet Atmospheric Retrieval
Dec 02, 2018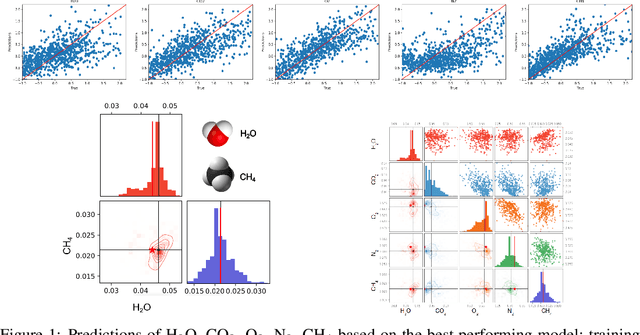

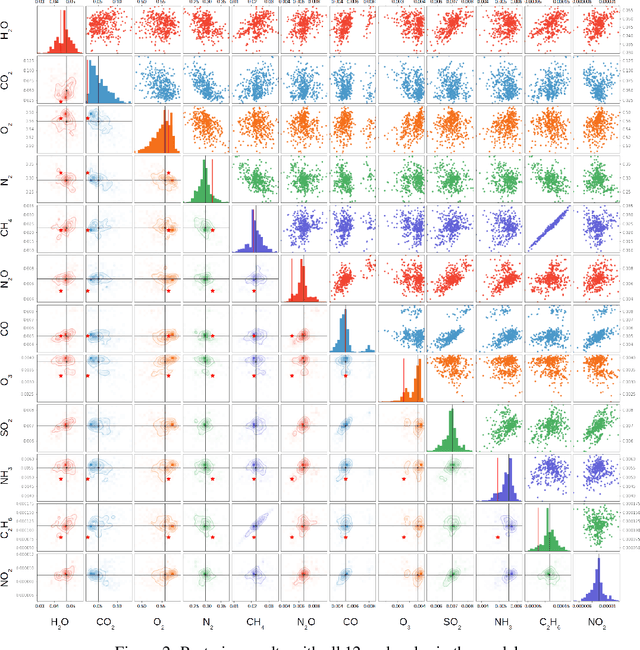
Over the past decade, the study of extrasolar planets has evolved rapidly from plain detection and identification to comprehensive categorization and characterization of exoplanet systems and their atmospheres. Atmospheric retrieval, the inverse modeling technique used to determine an exoplanetary atmosphere's temperature structure and composition from an observed spectrum, is both time-consuming and compute-intensive, requiring complex algorithms that compare thousands to millions of atmospheric models to the observational data to find the most probable values and associated uncertainties for each model parameter. For rocky, terrestrial planets, the retrieved atmospheric composition can give insight into the surface fluxes of gaseous species necessary to maintain the stability of that atmosphere, which may in turn provide insight into the geological and/or biological processes active on the planet. These atmospheres contain many molecules, some of them biosignatures, spectral fingerprints indicative of biological activity, which will become observable with the next generation of telescopes. Runtimes of traditional retrieval models scale with the number of model parameters, so as more molecular species are considered, runtimes can become prohibitively long. Recent advances in machine learning (ML) and computer vision offer new ways to reduce the time to perform a retrieval by orders of magnitude, given a sufficient data set to train with. Here we present an ML-based retrieval framework called Intelligent exoplaNet Atmospheric RetrievAl (INARA) that consists of a Bayesian deep learning model for retrieval and a data set of 3,000,000 synthetic rocky exoplanetary spectra generated using the NASA Planetary Spectrum Generator. Our work represents the first ML retrieval model for rocky, terrestrial exoplanets and the first synthetic data set of terrestrial spectra generated at this scale.
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
Sep 01, 2018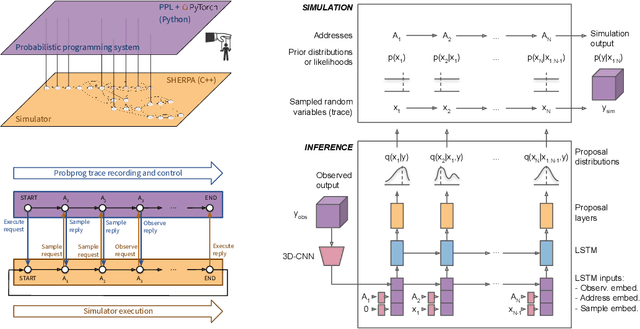
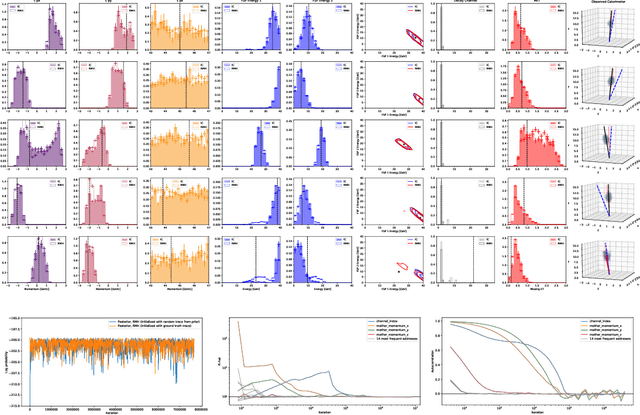


We present a novel framework that enables efficient probabilistic inference in large-scale scientific models by allowing the execution of existing domain-specific simulators as probabilistic programs, resulting in highly interpretable posterior inference. Our framework is general purpose and scalable, and is based on a cross-platform probabilistic execution protocol through which an inference engine can control simulators in a language-agnostic way. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. High-energy physics has a rich set of simulators based on quantum field theory and the interaction of particles in matter. We show how to use probabilistic programming to perform Bayesian inference in these existing simulator codebases directly, in particular conditioning on observable outputs from a simulated particle detector to directly produce an interpretable posterior distribution over decay pathways. Inference efficiency is achieved via inference compilation where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of Markov chain Monte Carlo sampling.
Online Learning Rate Adaptation with Hypergradient Descent
Feb 26, 2018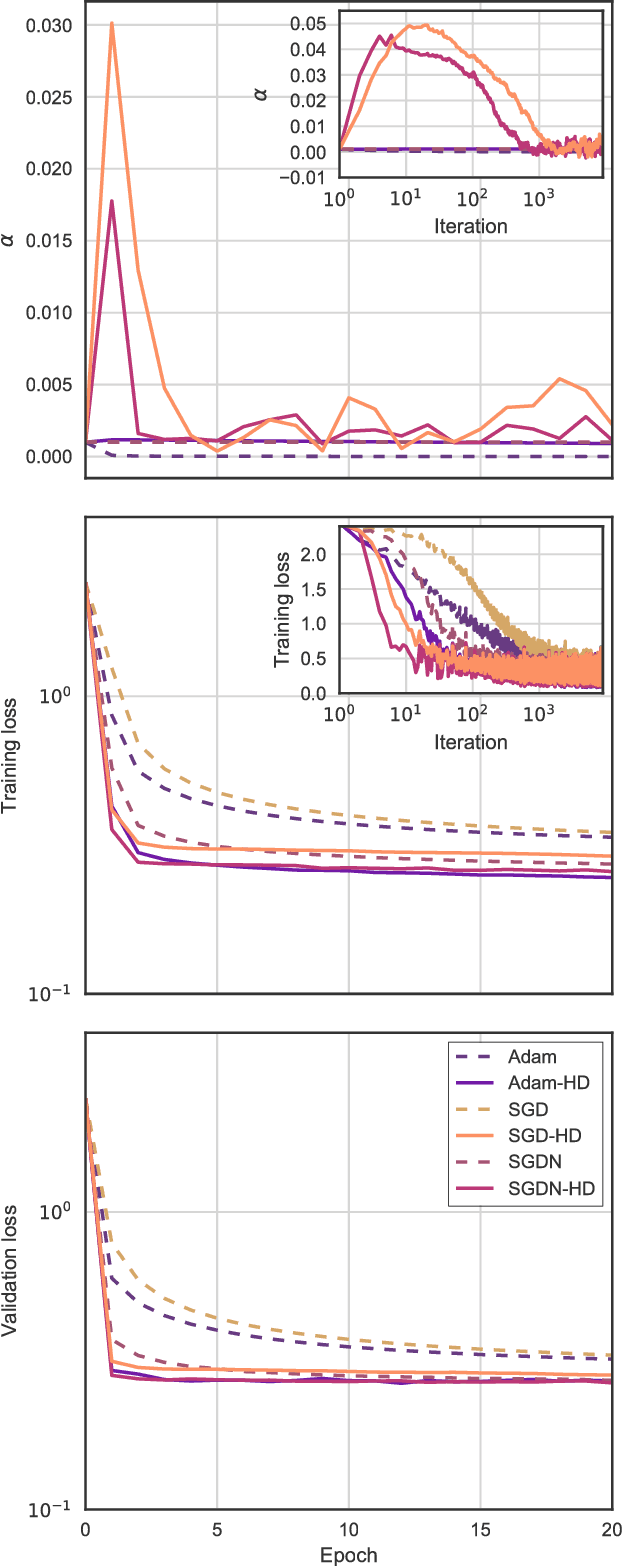
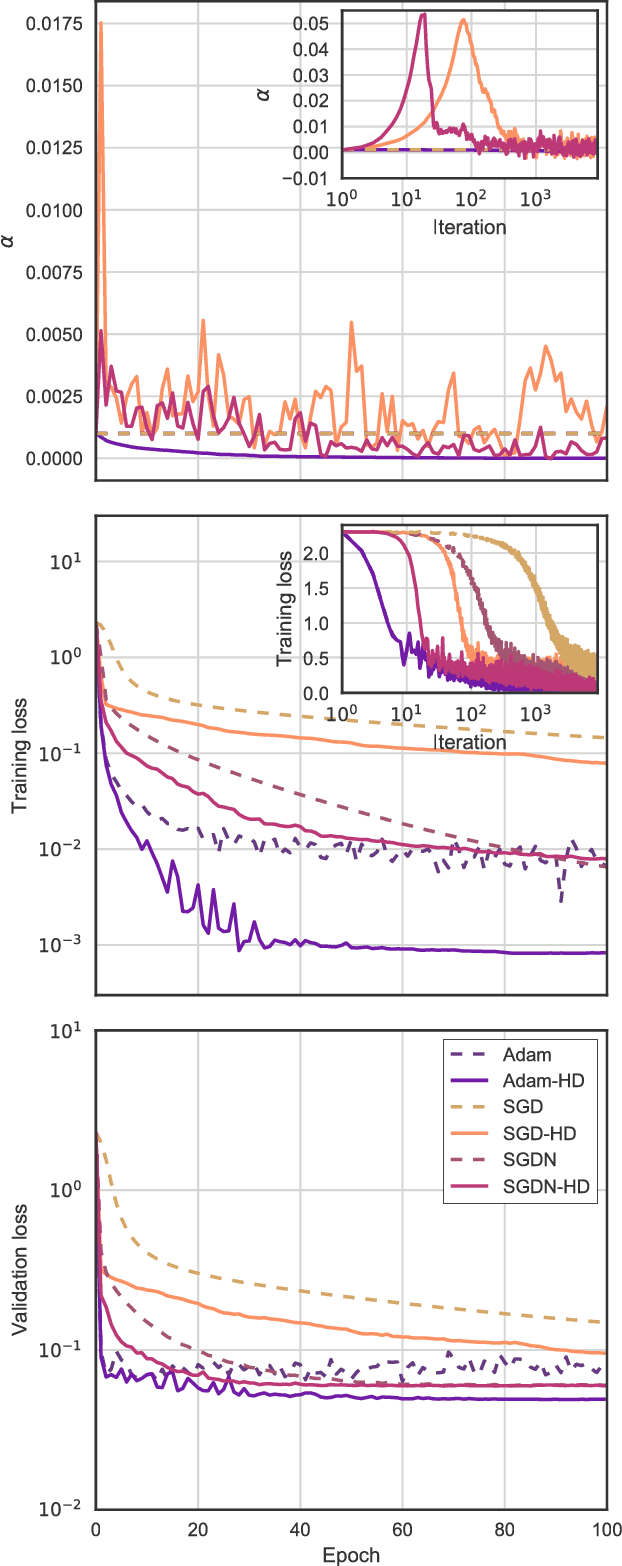
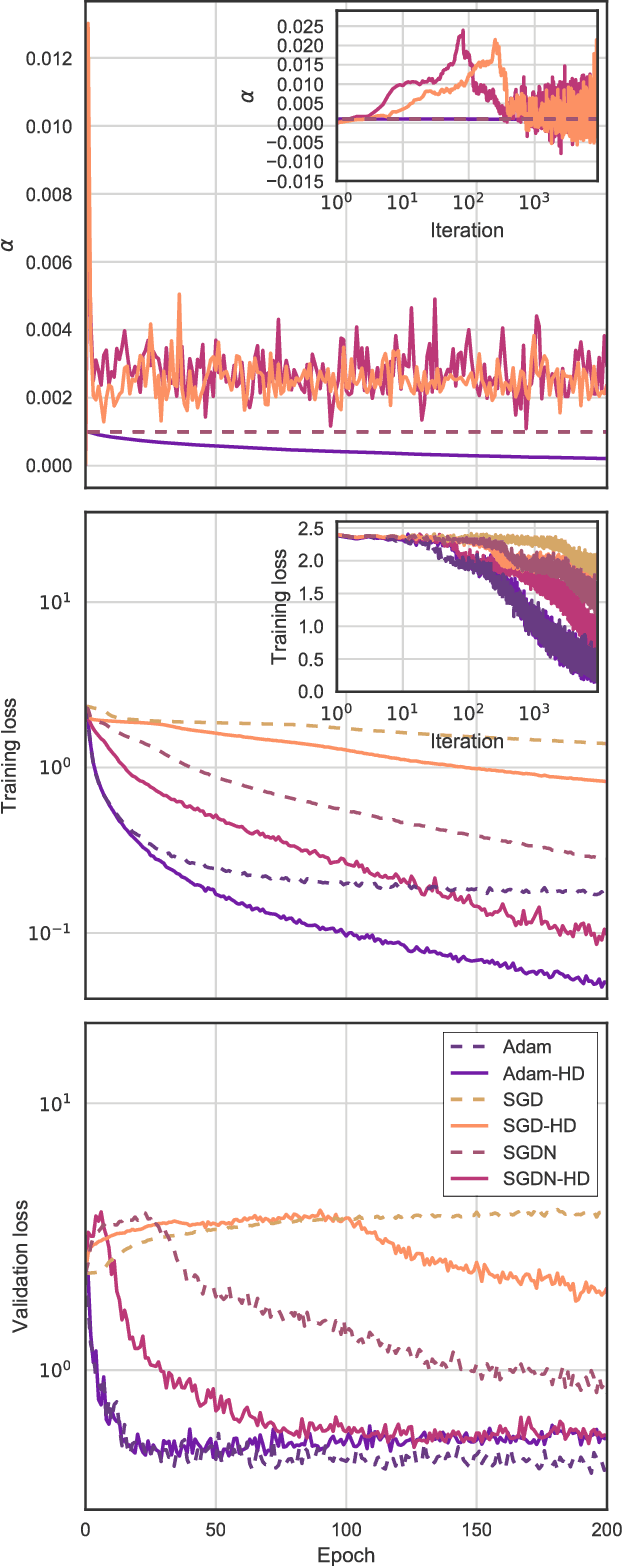
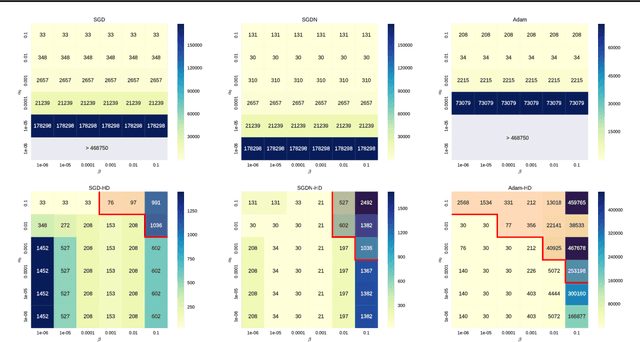
We introduce a general method for improving the convergence rate of gradient-based optimizers that is easy to implement and works well in practice. We demonstrate the effectiveness of the method in a range of optimization problems by applying it to stochastic gradient descent, stochastic gradient descent with Nesterov momentum, and Adam, showing that it significantly reduces the need for the manual tuning of the initial learning rate for these commonly used algorithms. Our method works by dynamically updating the learning rate during optimization using the gradient with respect to the learning rate of the update rule itself. Computing this "hypergradient" needs little additional computation, requires only one extra copy of the original gradient to be stored in memory, and relies upon nothing more than what is provided by reverse-mode automatic differentiation.
* 11 pages, 4 figures
Automatic differentiation in machine learning: a survey
Feb 05, 2018

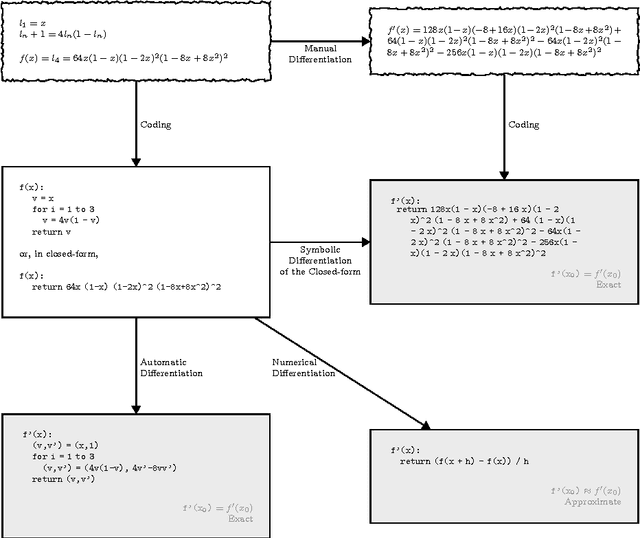

Derivatives, mostly in the form of gradients and Hessians, are ubiquitous in machine learning. Automatic differentiation (AD), also called algorithmic differentiation or simply "autodiff", is a family of techniques similar to but more general than backpropagation for efficiently and accurately evaluating derivatives of numeric functions expressed as computer programs. AD is a small but established field with applications in areas including computational fluid dynamics, atmospheric sciences, and engineering design optimization. Until very recently, the fields of machine learning and AD have largely been unaware of each other and, in some cases, have independently discovered each other's results. Despite its relevance, general-purpose AD has been missing from the machine learning toolbox, a situation slowly changing with its ongoing adoption under the names "dynamic computational graphs" and "differentiable programming". We survey the intersection of AD and machine learning, cover applications where AD has direct relevance, and address the main implementation techniques. By precisely defining the main differentiation techniques and their interrelationships, we aim to bring clarity to the usage of the terms "autodiff", "automatic differentiation", and "symbolic differentiation" as these are encountered more and more in machine learning settings.
* 43 pages, 5 figures
Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators
Dec 21, 2017

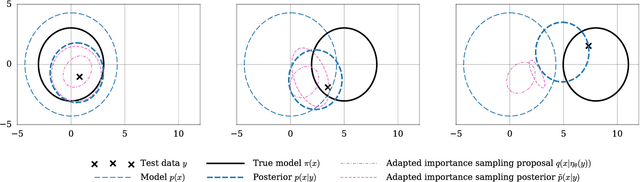
We consider the problem of Bayesian inference in the family of probabilistic models implicitly defined by stochastic generative models of data. In scientific fields ranging from population biology to cosmology, low-level mechanistic components are composed to create complex generative models. These models lead to intractable likelihoods and are typically non-differentiable, which poses challenges for traditional approaches to inference. We extend previous work in "inference compilation", which combines universal probabilistic programming and deep learning methods, to large-scale scientific simulators, and introduce a C++ based probabilistic programming library called CPProb. We successfully use CPProb to interface with SHERPA, a large code-base used in particle physics. Here we describe the technical innovations realized and planned for this library.
Using Synthetic Data to Train Neural Networks is Model-Based Reasoning
Mar 02, 2017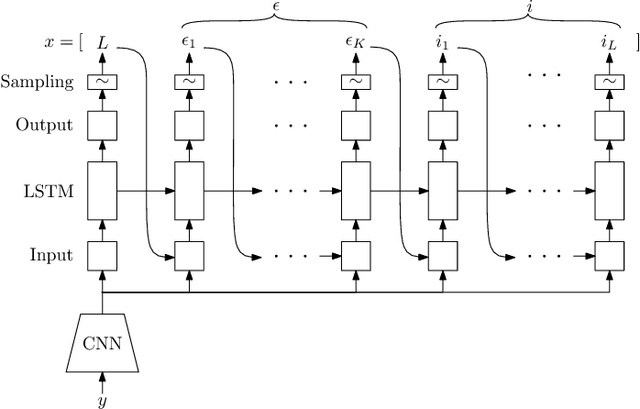

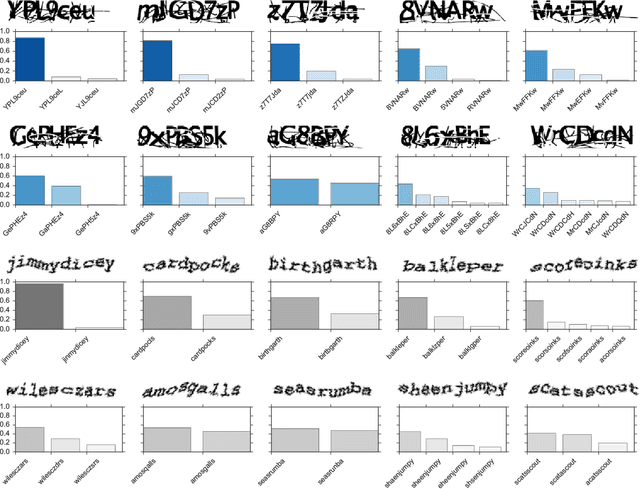
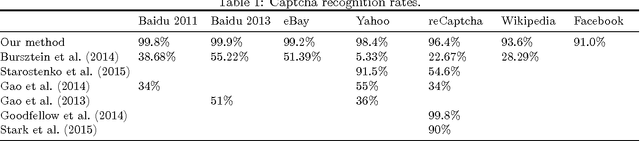
We draw a formal connection between using synthetic training data to optimize neural network parameters and approximate, Bayesian, model-based reasoning. In particular, training a neural network using synthetic data can be viewed as learning a proposal distribution generator for approximate inference in the synthetic-data generative model. We demonstrate this connection in a recognition task where we develop a novel Captcha-breaking architecture and train it using synthetic data, demonstrating both state-of-the-art performance and a way of computing task-specific posterior uncertainty. Using a neural network trained this way, we also demonstrate successful breaking of real-world Captchas currently used by Facebook and Wikipedia. Reasoning from these empirical results and drawing connections with Bayesian modeling, we discuss the robustness of synthetic data results and suggest important considerations for ensuring good neural network generalization when training with synthetic data.
Inference Compilation and Universal Probabilistic Programming
Mar 02, 2017


We introduce a method for using deep neural networks to amortize the cost of inference in models from the family induced by universal probabilistic programming languages, establishing a framework that combines the strengths of probabilistic programming and deep learning methods. We call what we do "compilation of inference" because our method transforms a denotational specification of an inference problem in the form of a probabilistic program written in a universal programming language into a trained neural network denoted in a neural network specification language. When at test time this neural network is fed observational data and executed, it performs approximate inference in the original model specified by the probabilistic program. Our training objective and learning procedure are designed to allow the trained neural network to be used as a proposal distribution in a sequential importance sampling inference engine. We illustrate our method on mixture models and Captcha solving and show significant speedups in the efficiency of inference.
* 11 pages, 6 figures