 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Formally Verified Neural Network for Autonomous Navigation: An Experience Report
Nov 21, 2024



The increased reliance of self-driving vehicles on neural networks opens up the challenge of their verification. In this paper we present an experience report, describing a case study which we undertook to explore the design and training of a neural network on a custom dataset for vision-based autonomous navigation. We are particularly interested in the use of machine learning with differentiable logics to obtain networks satisfying basic safety properties by design, guaranteeing the behaviour of the neural network after training. We motivate the choice of a suitable neural network verifier for our purposes and report our observations on the use of neural network verifiers for self-driving systems.
* In Proceedings FMAS2024, arXiv:2411.13215
Recent Trends in Modelling the Continuous Time Series using Deep Learning: A Survey
Sep 13, 2024



Continuous-time series is essential for different modern application areas, e.g. healthcare, automobile, energy, finance, Internet of things (IoT) and other related areas. Different application needs to process as well as analyse a massive amount of data in time series structure in order to determine the data-driven result, for example, financial trend prediction, potential probability of the occurrence of a particular event occurrence identification, patient health record processing and so many more. However, modeling real-time data using a continuous-time series is challenging since the dynamical systems behind the data could be a differential equation. Several research works have tried to solve the challenges of modelling the continuous-time series using different neural network models and approaches for data processing and learning. The existing deep learning models are not free from challenges and limitations due to diversity among different attributes, behaviour, duration of steps, energy, and data sampling rate. This paper has described the general problem domain of time series and reviewed the challenges of modelling the continuous time series. We have presented a comparative analysis of recent developments in deep learning models and their contribution to solving different difficulties of modelling the continuous time series. We have also identified the limitations of the existing neural network model and open issues. The main goal of this review is to understand the recent trend of neural network models used in a different real-world application with continuous-time data.
Second-Order Forward-Mode Automatic Differentiation for Optimization
Aug 19, 2024



This paper introduces a second-order hyperplane search, a novel optimization step that generalizes a second-order line search from a line to a $k$-dimensional hyperplane. This, combined with the forward-mode stochastic gradient method, yields a second-order optimization algorithm that consists of forward passes only, completely avoiding the storage overhead of backpropagation. Unlike recent work that relies on directional derivatives (or Jacobian--Vector Products, JVPs), we use hyper-dual numbers to jointly evaluate both directional derivatives and their second-order quadratic terms. As a result, we introduce forward-mode weight perturbation with Hessian information (FoMoH). We then use FoMoH to develop a novel generalization of line search by extending it to a hyperplane search. We illustrate the utility of this extension and how it might be used to overcome some of the recent challenges of optimizing machine learning models without backpropagation. Our code is open-sourced at https://github.com/SRI-CSL/fomoh.
Low-Rank Learning by Design: the Role of Network Architecture and Activation Linearity in Gradient Rank Collapse
Feb 09, 2024
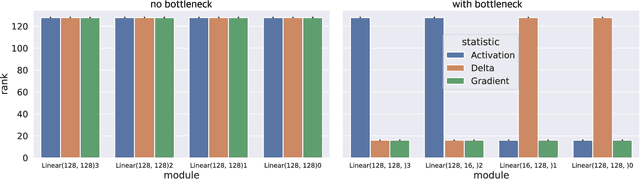

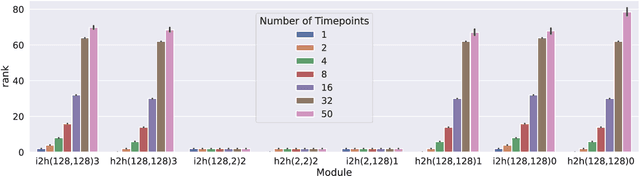
Our understanding of learning dynamics of deep neural networks (DNNs) remains incomplete. Recent research has begun to uncover the mathematical principles underlying these networks, including the phenomenon of "Neural Collapse", where linear classifiers within DNNs converge to specific geometrical structures during late-stage training. However, the role of geometric constraints in learning extends beyond this terminal phase. For instance, gradients in fully-connected layers naturally develop a low-rank structure due to the accumulation of rank-one outer products over a training batch. Despite the attention given to methods that exploit this structure for memory saving or regularization, the emergence of low-rank learning as an inherent aspect of certain DNN architectures has been under-explored. In this paper, we conduct a comprehensive study of gradient rank in DNNs, examining how architectural choices and structure of the data effect gradient rank bounds. Our theoretical analysis provides these bounds for training fully-connected, recurrent, and convolutional neural networks. We also demonstrate, both theoretically and empirically, how design choices like activation function linearity, bottleneck layer introduction, convolutional stride, and sequence truncation influence these bounds. Our findings not only contribute to the understanding of learning dynamics in DNNs, but also provide practical guidance for deep learning engineers to make informed design decisions.
Comparing Differentiable Logics for Learning Systems: A Research Preview
Nov 16, 2023Extensive research on formal verification of machine learning (ML) systems indicates that learning from data alone often fails to capture underlying background knowledge. A variety of verifiers have been developed to ensure that a machine-learnt model satisfies correctness and safety properties, however, these verifiers typically assume a trained network with fixed weights. ML-enabled autonomous systems are required to not only detect incorrect predictions, but should also possess the ability to self-correct, continuously improving and adapting. A promising approach for creating ML models that inherently satisfy constraints is to encode background knowledge as logical constraints that guide the learning process via so-called differentiable logics. In this research preview, we compare and evaluate various logics from the literature in weakly-supervised contexts, presenting our findings and highlighting open problems for future work. Our experimental results are broadly consistent with results reported previously in literature; however, learning with differentiable logics introduces a new hyperparameter that is difficult to tune and has significant influence on the effectiveness of the logics.
* In Proceedings FMAS 2023, arXiv:2311.08987
Gradients without Backpropagation
Feb 17, 2022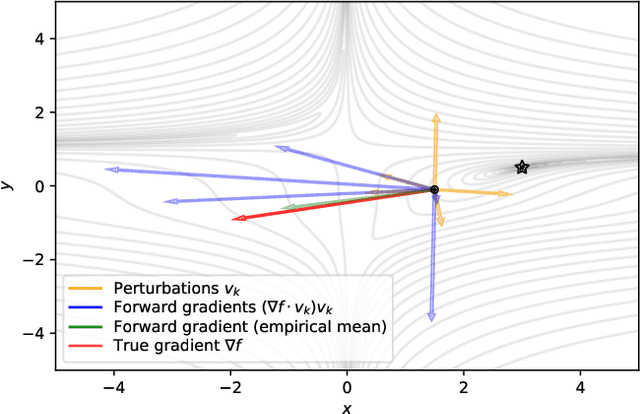
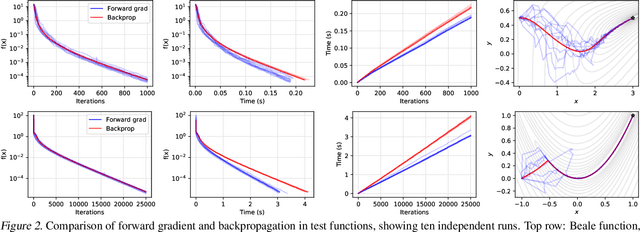

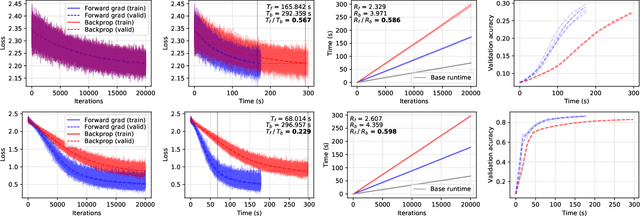
Using backpropagation to compute gradients of objective functions for optimization has remained a mainstay of machine learning. Backpropagation, or reverse-mode differentiation, is a special case within the general family of automatic differentiation algorithms that also includes the forward mode. We present a method to compute gradients based solely on the directional derivative that one can compute exactly and efficiently via the forward mode. We call this formulation the forward gradient, an unbiased estimate of the gradient that can be evaluated in a single forward run of the function, entirely eliminating the need for backpropagation in gradient descent. We demonstrate forward gradient descent in a range of problems, showing substantial savings in computation and enabling training up to twice as fast in some cases.
Continuous Convolutional Neural Networks: Coupled Neural PDE and ODE
Oct 30, 2021
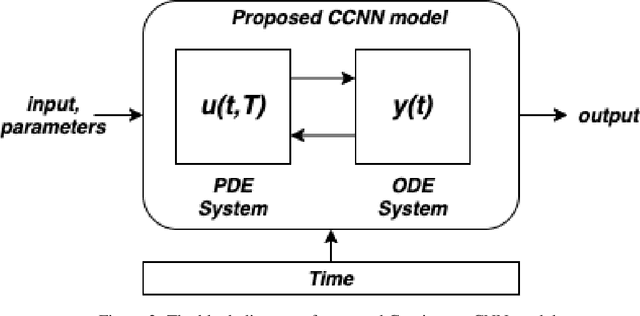
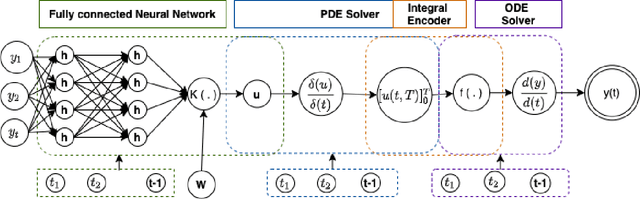
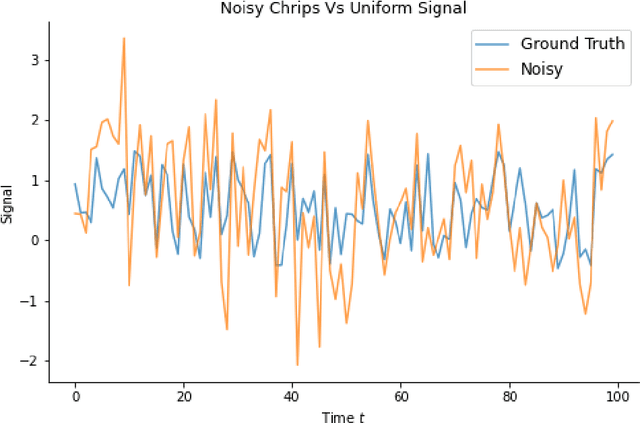
Recent work in deep learning focuses on solving physical systems in the Ordinary Differential Equation or Partial Differential Equation. This current work proposed a variant of Convolutional Neural Networks (CNNs) that can learn the hidden dynamics of a physical system using ordinary differential equation (ODEs) systems (ODEs) and Partial Differential Equation systems (PDEs). Instead of considering the physical system such as image, time -series as a system of multiple layers, this new technique can model a system in the form of Differential Equation (DEs). The proposed method has been assessed by solving several steady-state PDEs on irregular domains, including heat equations, Navier-Stokes equations.
Neural Network based on Automatic Differentiation Transformation of Numeric Iterate-to-Fixedpoint
Oct 30, 2021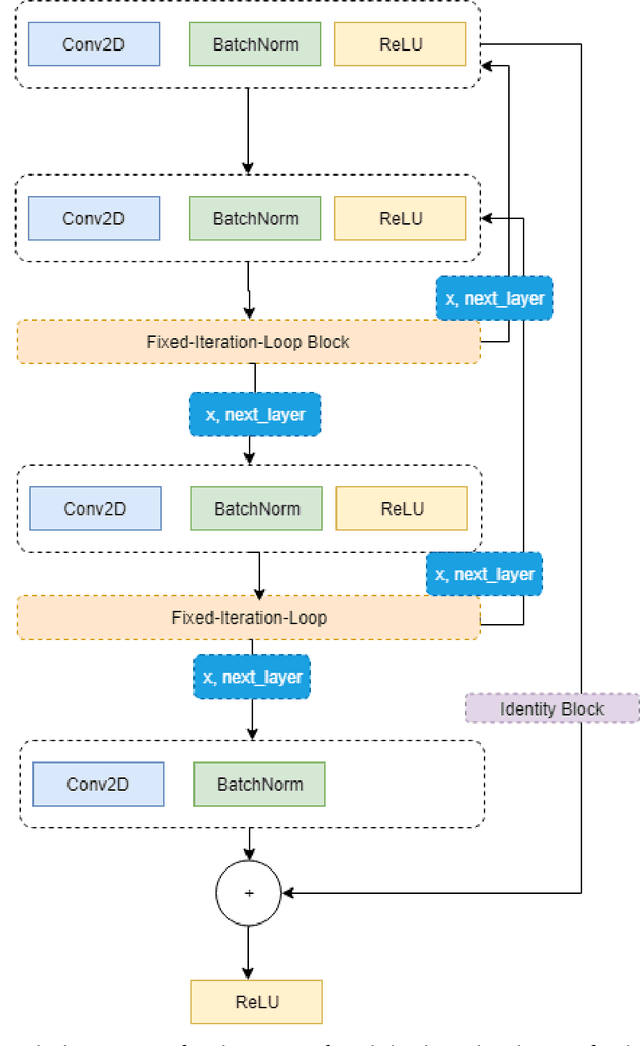

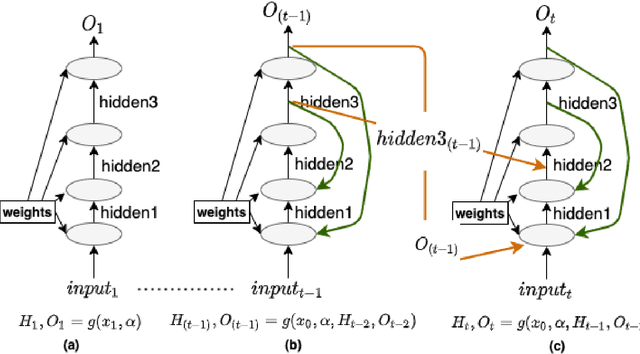

This work proposes a Neural Network model that can control its depth using an iterate-to-fixed-point operator. The architecture starts with a standard layered Network but with added connections from current later to earlier layers, along with a gate to make them inactive under most circumstances. These ``temporal wormhole'' connections create a shortcut that allows the Neural Network to use the information available at deeper layers and re-do earlier computations with modulated inputs. End-to-end training is accomplished by using appropriate calculations for a numeric iterate-to-fixed-point operator. In a typical case, where the ``wormhole'' connections are inactive, this is inexpensive; but when they are active, the network takes a longer time to settle down, and the gradient calculation is also more laborious, with an effect similar to making the network deeper. In contrast to the existing skip-connection concept, this proposed technique enables information to flow up and down in the network. Furthermore, the flow of information follows a fashion that seems analogous to the afferent and efferent flow of information through layers of processing in the brain. We evaluate models that use this novel mechanism on different long-term dependency tasks. The results are competitive with other studies, showing that the proposed model contributes significantly to overcoming traditional deep learning models' vanishing gradient descent problem. At the same time, the training time is significantly reduced, as the ``easy'' input cases are processed more quickly than ``difficult'' ones.
ECG synthesis with Neural ODE and GAN models
Oct 30, 2021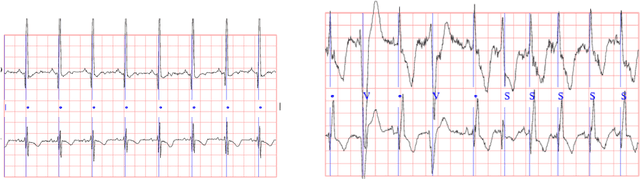

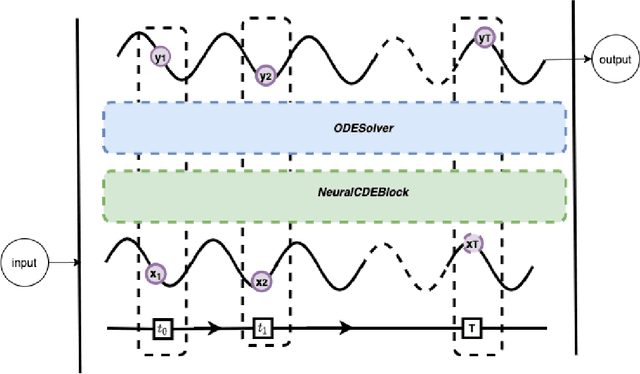
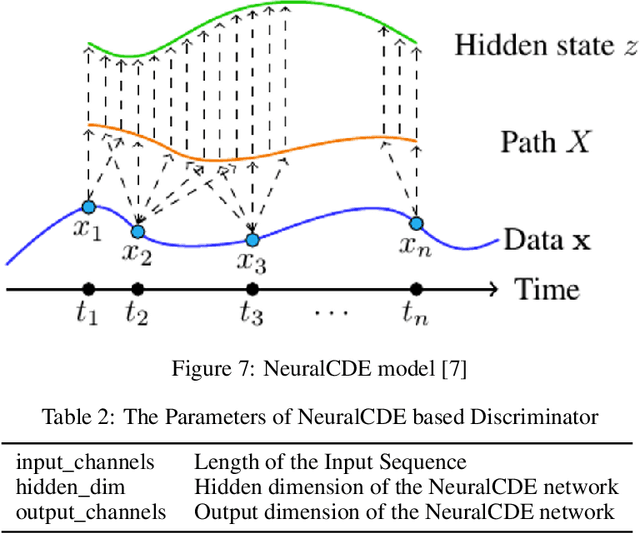
Continuous medical time series data such as ECG is one of the most complex time series due to its dynamic and high dimensional characteristics. In addition, due to its sensitive nature, privacy concerns and legal restrictions, it is often even complex to use actual data for different medical research. As a result, generating continuous medical time series is a very critical research area. Several research works already showed that the ability of generative adversarial networks (GANs) in the case of continuous medical time series generation is promising. Most medical data generation works, such as ECG synthesis, are mainly driven by the GAN model and its variation. On the other hand, Some recent work on Neural Ordinary Differential Equation (Neural ODE) demonstrates its strength against informative missingness, high dimension as well as dynamic nature of continuous time series. Instead of considering continuous-time series as a discrete-time sequence, Neural ODE can train continuous time series in real-time continuously. In this work, we used Neural ODE based model to generate synthetic sine waves and synthetic ECG. We introduced a new technique to design the generative adversarial network with Neural ODE based Generator and Discriminator. We developed three new models to synthesise continuous medical data. Different evaluation metrics are then used to quantitatively assess the quality of generated synthetic data for real-world applications and data analysis. Another goal of this work is to combine the strength of GAN and Neural ODE to generate synthetic continuous medical time series data such as ECG. We also evaluated both the GAN model and the Neural ODE model to understand the comparative efficiency of models from the GAN and Neural ODE family in medical data synthesis.
HeunNet: Extending ResNet using Heun's Methods
May 14, 2021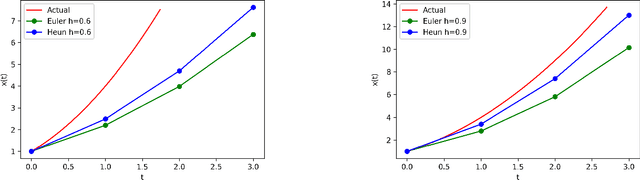
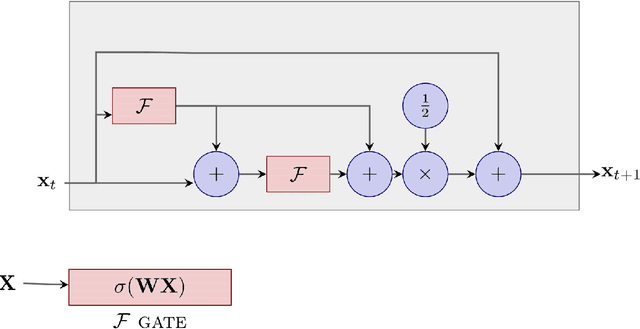
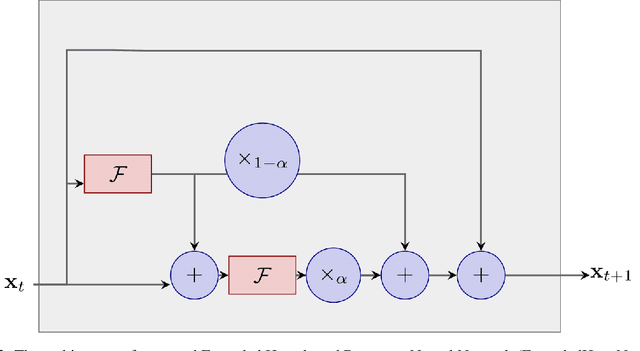
There is an analogy between the ResNet (Residual Network) architecture for deep neural networks and an Euler solver for an ODE. The transformation performed by each layer resembles an Euler step in solving an ODE. We consider the Heun Method, which involves a single predictor-corrector cycle, and complete the analogy, building a predictor-corrector variant of ResNet, which we call a HeunNet. Just as Heun's method is more accurate than Euler's, experiments show that HeunNet achieves high accuracy with low computational (both training and test) time compared to both vanilla recurrent neural networks and other ResNet variants.