 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Bad: Interpretability-Based Safety Audits of State-of-the-Art LLMs
Apr 22, 2026Effective safety auditing of large language models (LLMs) demands tools that go beyond black-box probing and systematically uncover vulnerabilities rooted in model internals. We present a comprehensive, interpretability-driven jailbreaking audit of eight SOTA open-source LLMs: Llama-3.1-8B, Llama-3.3-70B-4bt, GPT-oss- 20B, GPT-oss-120B, Qwen3-0.6B, Qwen3-32B, Phi4-3.8B, and Phi4-14B. Leveraging interpretability-based approaches -- Universal Steering (US) and Representation Engineering (RepE) -- we introduce an adaptive two-stage grid search algorithm to identify optimal activation-steering coefficients for unsafe behavioral concepts. Our evaluation, conducted on a curated set of harmful queries and a standardized LLM-based judging protocol, reveals stark contrasts in model robustness. The Llama-3 models are highly vulnerable, with up to 91\% (US) and 83\% (RepE) jailbroken responses on Llama-3.3-70B-4bt, while GPT-oss-120B remains robust to attacks via both interpretability approaches. Qwen and Phi models show mixed results, with the smaller Qwen3-0.6B and Phi4-3.8B mostly exhibiting lower jailbreaking rates, while their larger counterparts are more susceptible. Our results establish interpretability-based steering as a powerful tool for systematic safety audits, but also highlight its dual-use risks and the need for better internal defenses in LLM deployment.
Jailbreaking the Matrix: Nullspace Steering for Controlled Model Subversion
Apr 11, 2026Large language models remain vulnerable to jailbreak attacks -- inputs designed to bypass safety mechanisms and elicit harmful responses -- despite advances in alignment and instruction tuning. We propose Head-Masked Nullspace Steering (HMNS), a circuit-level intervention that (i) identifies attention heads most causally responsible for a model's default behavior, (ii) suppresses their write paths via targeted column masking, and (iii) injects a perturbation constrained to the orthogonal complement of the muted subspace. HMNS operates in a closed-loop detection-intervention cycle, re-identifying causal heads and reapplying interventions across multiple decoding attempts. Across multiple jailbreak benchmarks, strong safety defenses, and widely used language models, HMNS attains state-of-the-art attack success rates with fewer queries than prior methods. Ablations confirm that nullspace-constrained injection, residual norm scaling, and iterative re-identification are key to its effectiveness. To our knowledge, this is the first jailbreak method to leverage geometry-aware, interpretability-informed interventions, highlighting a new paradigm for controlled model steering and adversarial safety circumvention.
Optimal Abstractions for Verifying Properties of Kolmogorov-Arnold Networks (KANs)
Feb 06, 2026We present a novel approach for verifying properties of Kolmogorov-Arnold Networks (KANs), a class of neural networks characterized by nonlinear, univariate activation functions typically implemented as piecewise polynomial splines or Gaussian processes. Our method creates mathematical ``abstractions'' by replacing each KAN unit with a piecewise affine (PWA) function, providing both local and global error estimates between the original network and its approximation. These abstractions enable property verification by encoding the problem as a Mixed Integer Linear Program (MILP), determining whether outputs satisfy specified properties when inputs belong to a given set. A critical challenge lies in balancing the number of pieces in the PWA approximation: too many pieces add binary variables that make verification computationally intractable, while too few pieces create excessive error margins that yield uninformative bounds. Our key contribution is a systematic framework that exploits KAN structure to find optimal abstractions. By combining dynamic programming at the unit level with a knapsack optimization across the network, we minimize the total number of pieces while guaranteeing specified error bounds. This approach determines the optimal approximation strategy for each unit while maintaining overall accuracy requirements. Empirical evaluation across multiple KAN benchmarks demonstrates that the upfront analysis costs of our method are justified by superior verification results.
On the Dataless Training of Neural Networks
Oct 29, 2025This paper surveys studies on the use of neural networks for optimization in the training-data-free setting. Specifically, we examine the dataless application of neural network architectures in optimization by re-parameterizing problems using fully connected (or MLP), convolutional, graph, and quadratic neural networks. Although MLPs have been used to solve linear programs a few decades ago, this approach has recently gained increasing attention due to its promising results across diverse applications, including those based on combinatorial optimization, inverse problems, and partial differential equations. The motivation for this setting stems from two key (possibly over-lapping) factors: (i) data-driven learning approaches are still underdeveloped and have yet to demonstrate strong results, as seen in combinatorial optimization, and (ii) the availability of training data is inherently limited, such as in medical image reconstruction and other scientific applications. In this paper, we define the dataless setting and categorize it into two variants based on how a problem instance -- defined by a single datum -- is encoded onto the neural network: (i) architecture-agnostic methods and (ii) architecture-specific methods. Additionally, we discuss similarities and clarify distinctions between the dataless neural network (dNN) settings and related concepts such as zero-shot learning, one-shot learning, lifting in optimization, and over-parameterization.
Polysemantic Dropout: Conformal OOD Detection for Specialized LLMs
Sep 04, 2025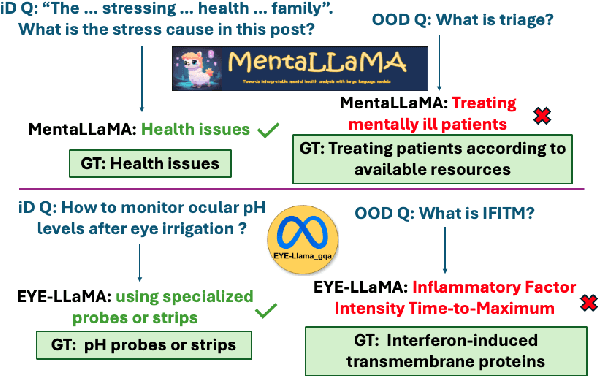

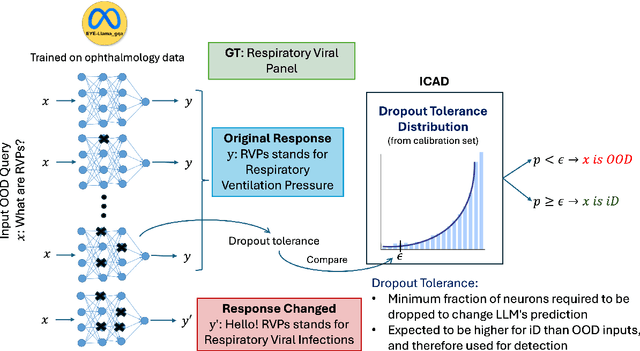

We propose a novel inference-time out-of-domain (OOD) detection algorithm for specialized large language models (LLMs). Despite achieving state-of-the-art performance on in-domain tasks through fine-tuning, specialized LLMs remain vulnerable to incorrect or unreliable outputs when presented with OOD inputs, posing risks in critical applications. Our method leverages the Inductive Conformal Anomaly Detection (ICAD) framework, using a new non-conformity measure based on the model's dropout tolerance. Motivated by recent findings on polysemanticity and redundancy in LLMs, we hypothesize that in-domain inputs exhibit higher dropout tolerance than OOD inputs. We aggregate dropout tolerance across multiple layers via a valid ensemble approach, improving detection while maintaining theoretical false alarm bounds from ICAD. Experiments with medical-specialized LLMs show that our approach detects OOD inputs better than baseline methods, with AUROC improvements of $2\%$ to $37\%$ when treating OOD datapoints as positives and in-domain test datapoints as negatives.
Scalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Jun 26, 2025Despite their widespread use, large language models (LLMs) are known to hallucinate incorrect information and be poorly calibrated. This makes the uncertainty quantification of these models of critical importance, especially in high-stakes domains, such as autonomy and healthcare. Prior work has made Bayesian deep learning-based approaches to this problem more tractable by performing inference over the low-rank adaptation (LoRA) parameters of a fine-tuned model. While effective, these approaches struggle to scale to larger LLMs due to requiring further additional parameters compared to LoRA. In this work we present $\textbf{Scala}$ble $\textbf{B}$ayesian $\textbf{L}$ow-Rank Adaptation via Stochastic Variational Subspace Inference (ScalaBL). We perform Bayesian inference in an $r$-dimensional subspace, for LoRA rank $r$. By repurposing the LoRA parameters as projection matrices, we are able to map samples from this subspace into the full weight space of the LLM. This allows us to learn all the parameters of our approach using stochastic variational inference. Despite the low dimensionality of our subspace, we are able to achieve competitive performance with state-of-the-art approaches while only requiring ${\sim}1000$ additional parameters. Furthermore, it allows us to scale up to the largest Bayesian LLM to date, with four times as a many base parameters as prior work.
TOGA: Temporally Grounded Open-Ended Video QA with Weak Supervision
Jun 11, 2025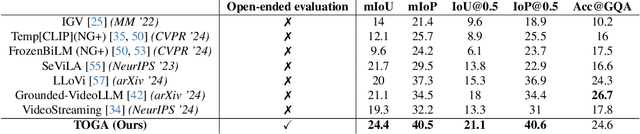

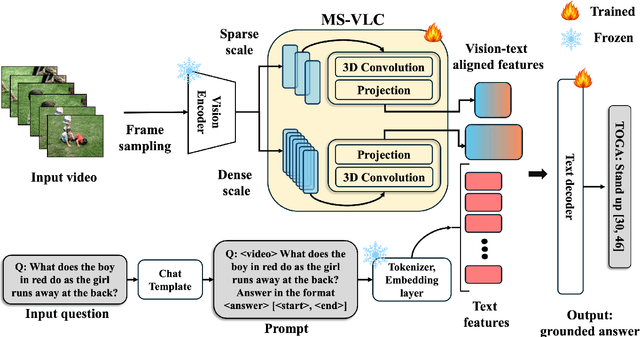
We address the problem of video question answering (video QA) with temporal grounding in a weakly supervised setup, without any temporal annotations. Given a video and a question, we generate an open-ended answer grounded with the start and end time. For this task, we propose TOGA: a vision-language model for Temporally Grounded Open-Ended Video QA with Weak Supervision. We instruct-tune TOGA to jointly generate the answer and the temporal grounding. We operate in a weakly supervised setup where the temporal grounding annotations are not available. We generate pseudo labels for temporal grounding and ensure the validity of these labels by imposing a consistency constraint between the question of a grounding response and the response generated by a question referring to the same temporal segment. We notice that jointly generating the answers with the grounding improves performance on question answering as well as grounding. We evaluate TOGA on grounded QA and open-ended QA tasks. For grounded QA, we consider the NExT-GQA benchmark which is designed to evaluate weakly supervised grounded question answering. For open-ended QA, we consider the MSVD-QA and ActivityNet-QA benchmarks. We achieve state-of-the-art performance for both tasks on these benchmarks.
Backpropagation-Free Metropolis-Adjusted Langevin Algorithm
May 23, 2025Recent work on backpropagation-free learning has shown that it is possible to use forward-mode automatic differentiation (AD) to perform optimization on differentiable models. Forward-mode AD requires sampling a tangent vector for each forward pass of a model. The result is the model evaluation with the directional derivative along the tangent. In this paper, we illustrate how the sampling of this tangent vector can be incorporated into the proposal mechanism for the Metropolis-Adjusted Langevin Algorithm (MALA). As such, we are the first to introduce a backpropagation-free gradient-based Markov chain Monte Carlo (MCMC) algorithm. We also extend to a novel backpropagation-free position-specific preconditioned forward-mode MALA that leverages Hessian information. Overall, we propose four new algorithms: Forward MALA; Line Forward MALA; Pre-conditioned Forward MALA, and Pre-conditioned Line Forward MALA. We highlight the reduced computational cost of the forward-mode samplers and show that forward-mode is competitive with the original MALA, while even outperforming it depending on the probabilistic model. We include Bayesian inference results on a range of probabilistic models, including hierarchical distributions and Bayesian neural networks.
On the Evaluation of Engineering Artificial General Intelligence
May 15, 2025
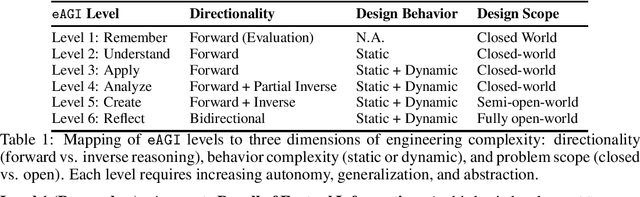

We discuss the challenges and propose a framework for evaluating engineering artificial general intelligence (eAGI) agents. We consider eAGI as a specialization of artificial general intelligence (AGI), deemed capable of addressing a broad range of problems in the engineering of physical systems and associated controllers. We exclude software engineering for a tractable scoping of eAGI and expect dedicated software engineering AI agents to address the software implementation challenges. Similar to human engineers, eAGI agents should possess a unique blend of background knowledge (recall and retrieve) of facts and methods, demonstrate familiarity with tools and processes, exhibit deep understanding of industrial components and well-known design families, and be able to engage in creative problem solving (analyze and synthesize), transferring ideas acquired in one context to another. Given this broad mandate, evaluating and qualifying the performance of eAGI agents is a challenge in itself and, arguably, a critical enabler to developing eAGI agents. In this paper, we address this challenge by proposing an extensible evaluation framework that specializes and grounds Bloom's taxonomy - a framework for evaluating human learning that has also been recently used for evaluating LLMs - in an engineering design context. Our proposed framework advances the state of the art in benchmarking and evaluation of AI agents in terms of the following: (a) developing a rich taxonomy of evaluation questions spanning from methodological knowledge to real-world design problems; (b) motivating a pluggable evaluation framework that can evaluate not only textual responses but also evaluate structured design artifacts such as CAD models and SysML models; and (c) outlining an automatable procedure to customize the evaluation benchmark to different engineering contexts.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Apr 30, 2025We introduce a novel approach for calibrating uncertainty quantification (UQ) tailored for multi-modal large language models (LLMs). Existing state-of-the-art UQ methods rely on consistency among multiple responses generated by the LLM on an input query under diverse settings. However, these approaches often report higher confidence in scenarios where the LLM is consistently incorrect. This leads to a poorly calibrated confidence with respect to accuracy. To address this, we leverage cross-modal consistency in addition to self-consistency to improve the calibration of the multi-modal models. Specifically, we ground the textual responses to the visual inputs. The confidence from the grounding model is used to calibrate the overall confidence. Given that using a grounding model adds its own uncertainty in the pipeline, we apply temperature scaling - a widely accepted parametric calibration technique - to calibrate the grounding model's confidence in the accuracy of generated responses. We evaluate the proposed approach across multiple multi-modal tasks, such as medical question answering (Slake) and visual question answering (VQAv2), considering multi-modal models such as LLaVA-Med and LLaVA. The experiments demonstrate that the proposed framework achieves significantly improved calibration on both tasks.