 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Jun 26, 2025Despite their widespread use, large language models (LLMs) are known to hallucinate incorrect information and be poorly calibrated. This makes the uncertainty quantification of these models of critical importance, especially in high-stakes domains, such as autonomy and healthcare. Prior work has made Bayesian deep learning-based approaches to this problem more tractable by performing inference over the low-rank adaptation (LoRA) parameters of a fine-tuned model. While effective, these approaches struggle to scale to larger LLMs due to requiring further additional parameters compared to LoRA. In this work we present $\textbf{Scala}$ble $\textbf{B}$ayesian $\textbf{L}$ow-Rank Adaptation via Stochastic Variational Subspace Inference (ScalaBL). We perform Bayesian inference in an $r$-dimensional subspace, for LoRA rank $r$. By repurposing the LoRA parameters as projection matrices, we are able to map samples from this subspace into the full weight space of the LLM. This allows us to learn all the parameters of our approach using stochastic variational inference. Despite the low dimensionality of our subspace, we are able to achieve competitive performance with state-of-the-art approaches while only requiring ${\sim}1000$ additional parameters. Furthermore, it allows us to scale up to the largest Bayesian LLM to date, with four times as a many base parameters as prior work.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Apr 30, 2025We introduce a novel approach for calibrating uncertainty quantification (UQ) tailored for multi-modal large language models (LLMs). Existing state-of-the-art UQ methods rely on consistency among multiple responses generated by the LLM on an input query under diverse settings. However, these approaches often report higher confidence in scenarios where the LLM is consistently incorrect. This leads to a poorly calibrated confidence with respect to accuracy. To address this, we leverage cross-modal consistency in addition to self-consistency to improve the calibration of the multi-modal models. Specifically, we ground the textual responses to the visual inputs. The confidence from the grounding model is used to calibrate the overall confidence. Given that using a grounding model adds its own uncertainty in the pipeline, we apply temperature scaling - a widely accepted parametric calibration technique - to calibrate the grounding model's confidence in the accuracy of generated responses. We evaluate the proposed approach across multiple multi-modal tasks, such as medical question answering (Slake) and visual question answering (VQAv2), considering multi-modal models such as LLaVA-Med and LLaVA. The experiments demonstrate that the proposed framework achieves significantly improved calibration on both tasks.
TeleLoRA: Teleporting Model-Specific Alignment Across LLMs
Mar 26, 2025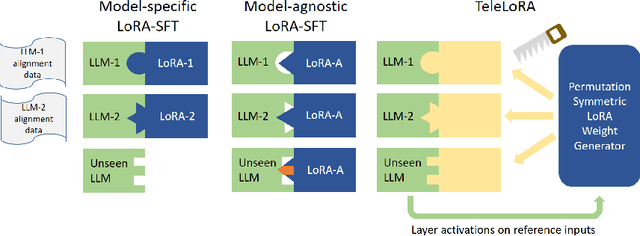

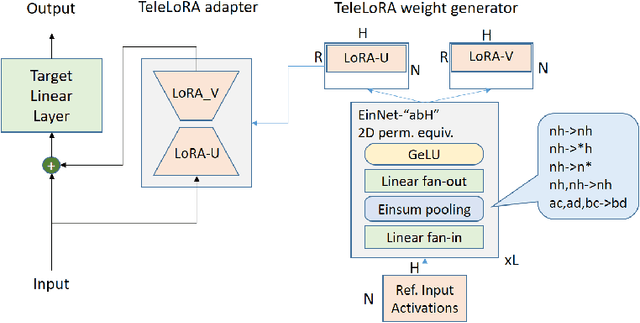

Mitigating Trojans in Large Language Models (LLMs) is one of many tasks where alignment data is LLM specific, as different LLMs have different Trojan triggers and trigger behaviors to be removed. In this paper, we introduce TeleLoRA (Teleporting Low-Rank Adaptation), a novel framework that synergizes model-specific alignment data across multiple LLMs to enable zero-shot Trojan mitigation on unseen LLMs without alignment data. TeleLoRA learns a unified generator of LoRA adapter weights by leveraging local activation information across multiple LLMs. This generator is designed to be permutation symmetric to generalize across models with different architectures and sizes. We optimize the model design for memory efficiency, making it feasible to learn with large-scale LLMs with minimal computational resources. Experiments on LLM Trojan mitigation benchmarks demonstrate that TeleLoRA effectively reduces attack success rates while preserving the benign performance of the models.
Addressing Uncertainty in LLMs to Enhance Reliability in Generative AI
Nov 04, 2024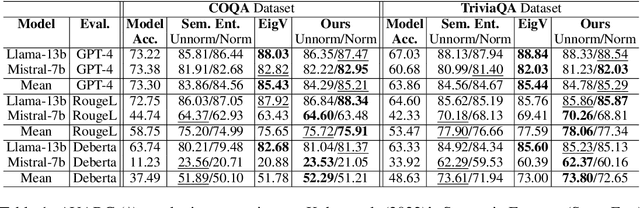
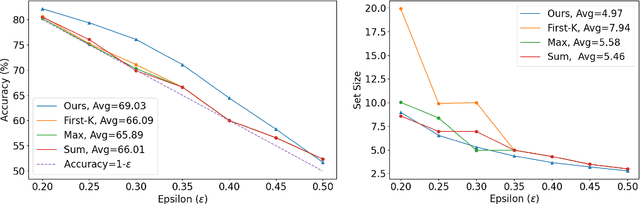
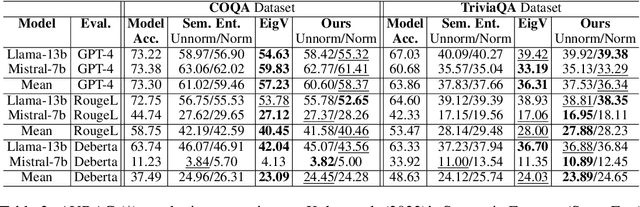
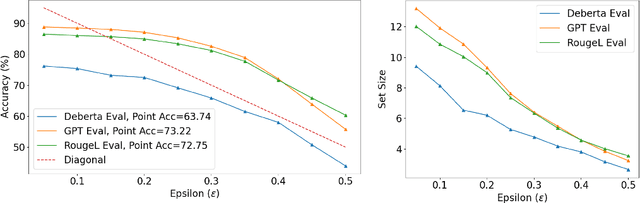
In this paper, we present a dynamic semantic clustering approach inspired by the Chinese Restaurant Process, aimed at addressing uncertainty in the inference of Large Language Models (LLMs). We quantify uncertainty of an LLM on a given query by calculating entropy of the generated semantic clusters. Further, we propose leveraging the (negative) likelihood of these clusters as the (non)conformity score within Conformal Prediction framework, allowing the model to predict a set of responses instead of a single output, thereby accounting for uncertainty in its predictions. We demonstrate the effectiveness of our uncertainty quantification (UQ) technique on two well known question answering benchmarks, COQA and TriviaQA, utilizing two LLMs, Llama2 and Mistral. Our approach achieves SOTA performance in UQ, as assessed by metrics such as AUROC, AUARC, and AURAC. The proposed conformal predictor is also shown to produce smaller prediction sets while maintaining the same probabilistic guarantee of including the correct response, in comparison to existing SOTA conformal prediction baseline.
Revisiting Multi-Modal LLM Evaluation
Aug 09, 2024
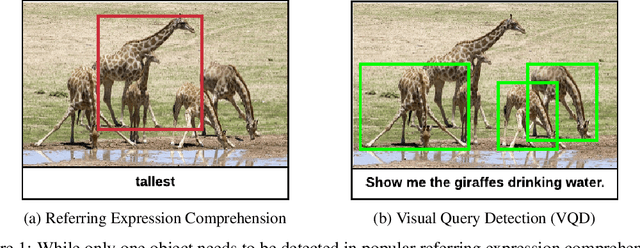

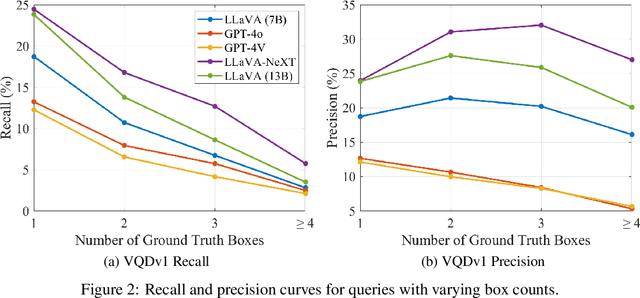
With the advent of multi-modal large language models (MLLMs), datasets used for visual question answering (VQA) and referring expression comprehension have seen a resurgence. However, the most popular datasets used to evaluate MLLMs are some of the earliest ones created, and they have many known problems, including extreme bias, spurious correlations, and an inability to permit fine-grained analysis. In this paper, we pioneer evaluating recent MLLMs (LLaVA 1.5, LLaVA-NeXT, BLIP2, InstructBLIP, GPT-4V, and GPT-4o) on datasets designed to address weaknesses in earlier ones. We assess three VQA datasets: 1) TDIUC, which permits fine-grained analysis on 12 question types; 2) TallyQA, which has simple and complex counting questions; and 3) DVQA, which requires optical character recognition for chart understanding. We also study VQDv1, a dataset that requires identifying all image regions that satisfy a given query. Our experiments reveal the weaknesses of many MLLMs that have not previously been reported. Our code is integrated into the widely used LAVIS framework for MLLM evaluation, enabling the rapid assessment of future MLLMs. Project webpage: https://kevinlujian.github.io/MLLM_Evaluations/
Detecting out-of-context objects using contextual cues
Feb 11, 2022

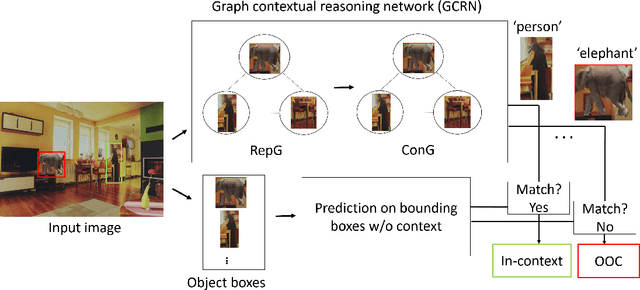

This paper presents an approach to detect out-of-context (OOC) objects in an image. Given an image with a set of objects, our goal is to determine if an object is inconsistent with the scene context and detect the OOC object with a bounding box. In this work, we consider commonly explored contextual relations such as co-occurrence relations, the relative size of an object with respect to other objects, and the position of the object in the scene. We posit that contextual cues are useful to determine object labels for in-context objects and inconsistent context cues are detrimental to determining object labels for out-of-context objects. To realize this hypothesis, we propose a graph contextual reasoning network (GCRN) to detect OOC objects. GCRN consists of two separate graphs to predict object labels based on the contextual cues in the image: 1) a representation graph to learn object features based on the neighboring objects and 2) a context graph to explicitly capture contextual cues from the neighboring objects. GCRN explicitly captures the contextual cues to improve the detection of in-context objects and identify objects that violate contextual relations. In order to evaluate our approach, we create a large-scale dataset by adding OOC object instances to the COCO images. We also evaluate on recent OCD benchmark. Our results show that GCRN outperforms competitive baselines in detecting OOC objects and correctly detecting in-context objects.
2nd Place Solution for SODA10M Challenge 2021 -- Continual Detection Track
Oct 25, 2021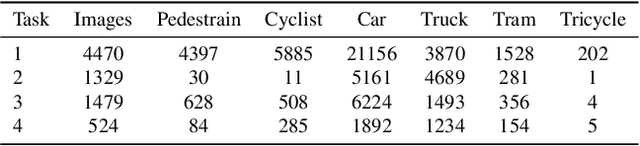
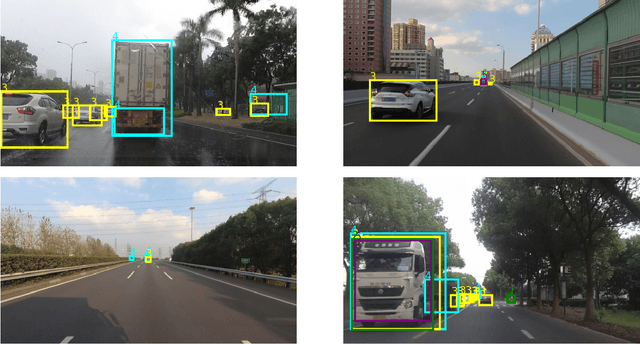
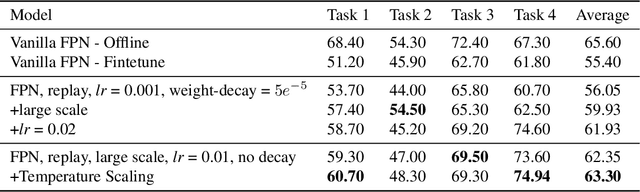

In this technical report, we present our approaches for the continual object detection track of the SODA10M challenge. We adapt ResNet50-FPN as the baseline and try several improvements for the final submission model. We find that task-specific replay scheme, learning rate scheduling, model calibration, and using original image scale helps to improve performance for both large and small objects in images. Our team `hypertune28' secured the second position among 52 participants in the challenge. This work will be presented at the ICCV 2021 Workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving (SSLAD).
RODEO: Replay for Online Object Detection
Aug 14, 2020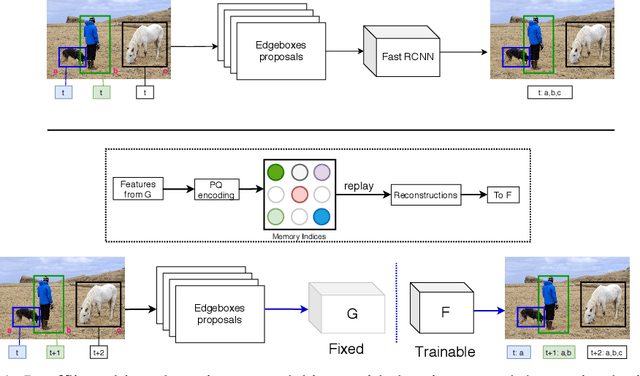
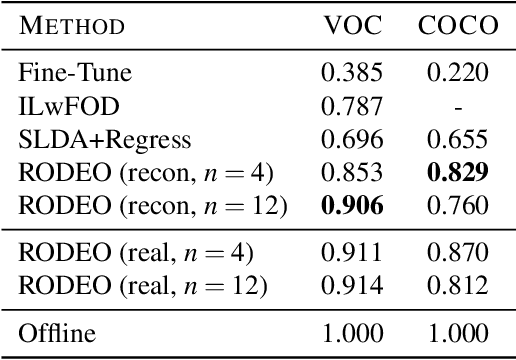
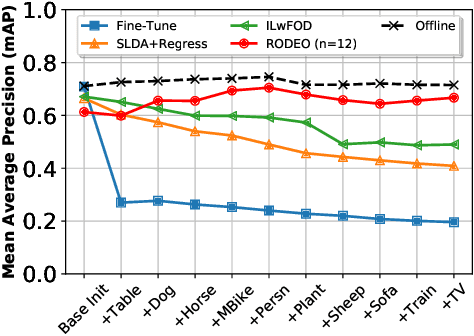
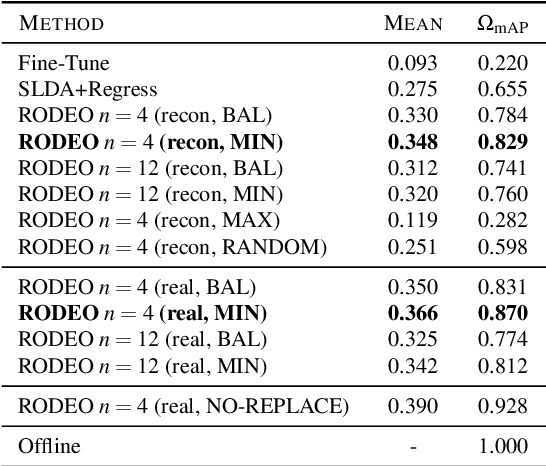
Humans can incrementally learn to do new visual detection tasks, which is a huge challenge for today's computer vision systems. Incrementally trained deep learning models lack backwards transfer to previously seen classes and suffer from a phenomenon known as $"catastrophic forgetting."$ In this paper, we pioneer online streaming learning for object detection, where an agent must learn examples one at a time with severe memory and computational constraints. In object detection, a system must output all bounding boxes for an image with the correct label. Unlike earlier work, the system described in this paper can learn this task in an online manner with new classes being introduced over time. We achieve this capability by using a novel memory replay mechanism that efficiently replays entire scenes. We achieve state-of-the-art results on both the PASCAL VOC 2007 and MS COCO datasets.
REMIND Your Neural Network to Prevent Catastrophic Forgetting
Oct 06, 2019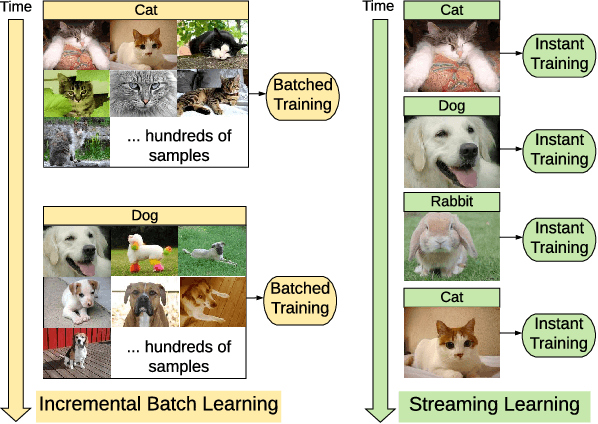
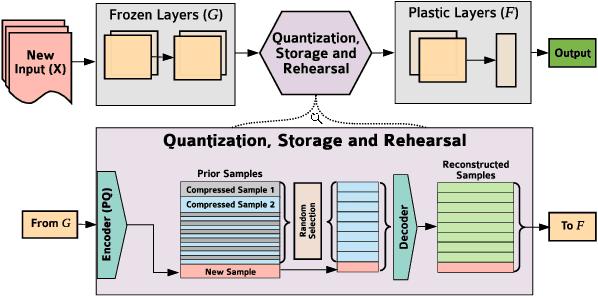
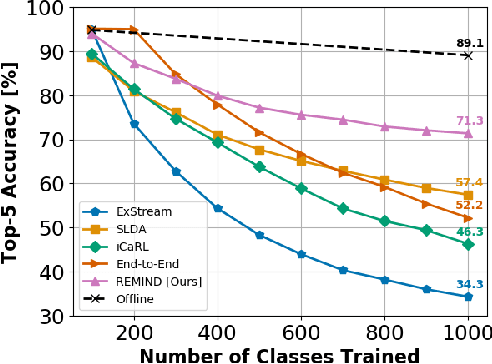
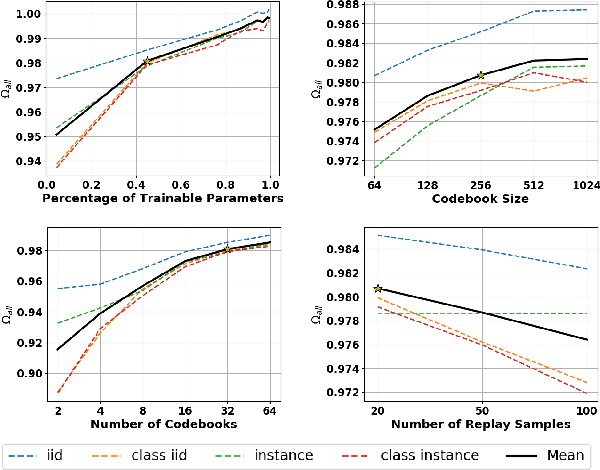
In lifelong machine learning, a robotic agent must be incrementally updated with new knowledge, instead of having distinct train and deployment phases. Conventional neural networks are often used for interpreting sensor data, however, if they are updated on non-stationary data streams, they suffer from catastrophic forgetting, with new learning overwriting past knowledge. A common remedy is replay, which involves mixing old examples with new ones. For incrementally training convolutional neural network models, prior work has enabled replay by storing raw images, but this is memory intensive and not ideal for embedded agents. Here, we propose REMIND, a tensor quantization approach that enables efficient replay with tensors. Unlike other methods, REMIND is trained in a streaming manner, meaning it learns one example at a time rather than in large batches containing multiple classes. Our approach achieves state-of-the-art results for incremental class learning on the ImageNet-1K dataset. We also probe REMIND's robustness to different data ordering schemes using the CORe50 streaming dataset. We demonstrate REMIND's generality by pioneering multi-modal incremental learning for visual question answering (VQA), which cannot be readily done with comparison models. We establish strong baselines on the CLEVR and TDIUC datasets for VQA. The generality of REMIND for multi-modal tasks can enable robotic agents to learn about their visual environment using natural language understanding in an interactive way.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019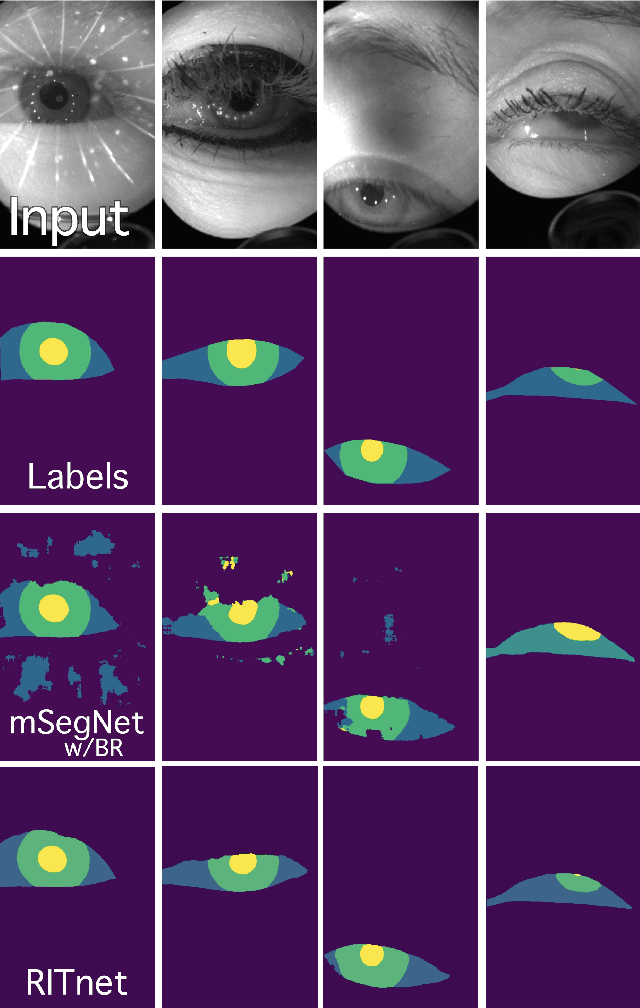
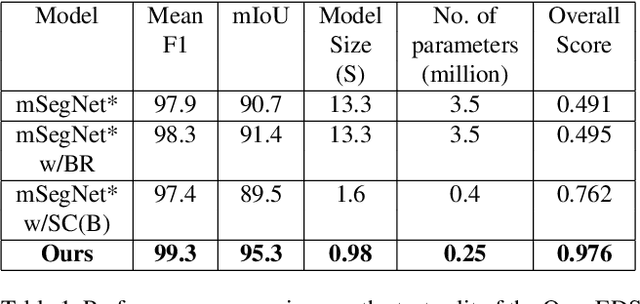
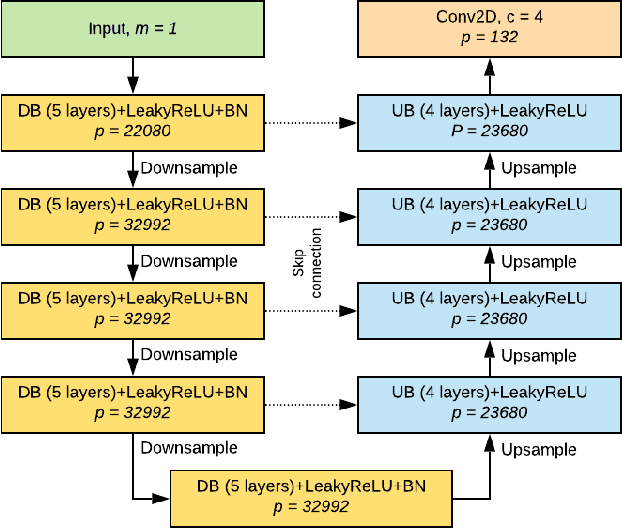
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.