 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Physically Unconstrained Gaze Estimation
May 20, 2021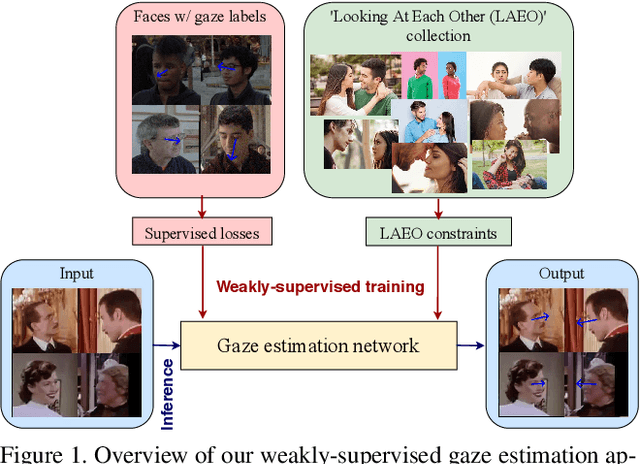
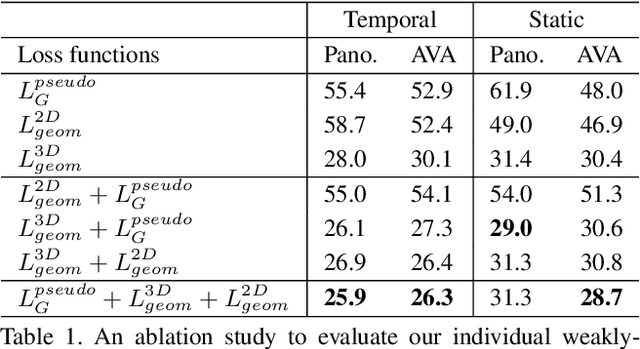
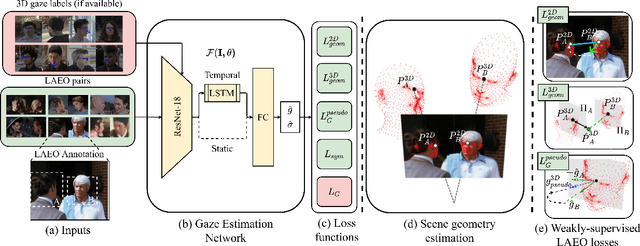
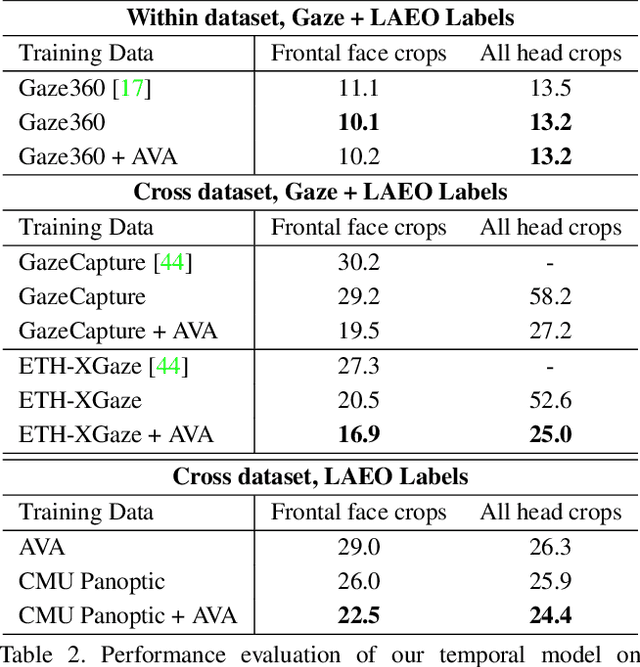
A major challenge for physically unconstrained gaze estimation is acquiring training data with 3D gaze annotations for in-the-wild and outdoor scenarios. In contrast, videos of human interactions in unconstrained environments are abundantly available and can be much more easily annotated with frame-level activity labels. In this work, we tackle the previously unexplored problem of weakly-supervised gaze estimation from videos of human interactions. We leverage the insight that strong gaze-related geometric constraints exist when people perform the activity of "looking at each other" (LAEO). To acquire viable 3D gaze supervision from LAEO labels, we propose a training algorithm along with several novel loss functions especially designed for the task. With weak supervision from two large scale CMU-Panoptic and AVA-LAEO activity datasets, we show significant improvements in (a) the accuracy of semi-supervised gaze estimation and (b) cross-domain generalization on the state-of-the-art physically unconstrained in-the-wild Gaze360 gaze estimation benchmark. We open source our code at https://github.com/NVlabs/weakly-supervised-gaze.
RIT-Eyes: Rendering of near-eye images for eye-tracking applications
Jun 05, 2020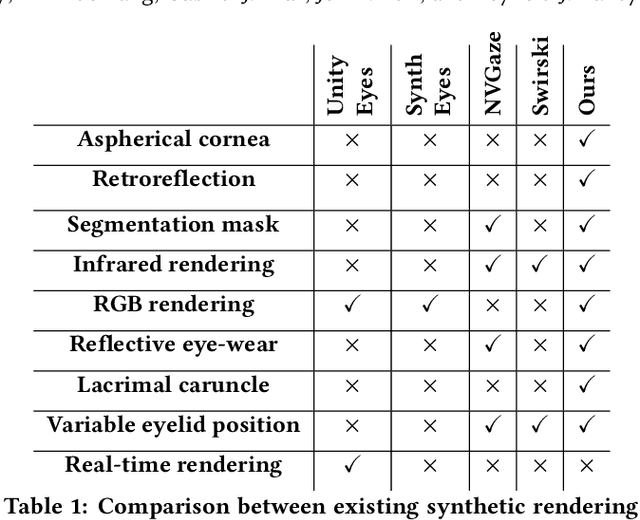
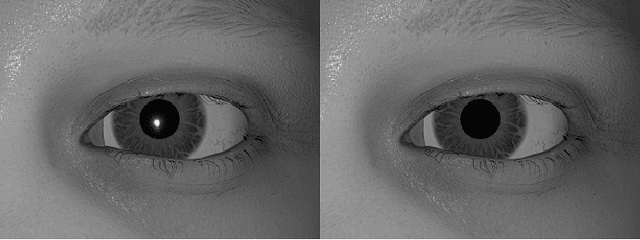
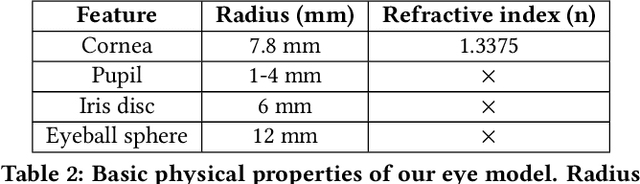
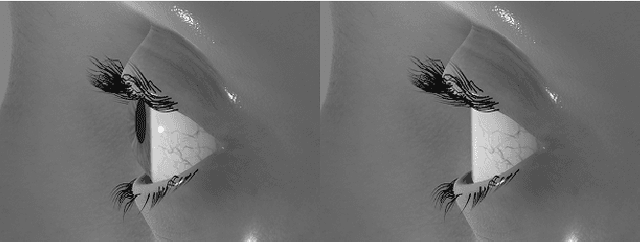
Deep neural networks for video-based eye tracking have demonstrated resilience to noisy environments, stray reflections, and low resolution. However, to train these networks, a large number of manually annotated images are required. To alleviate the cumbersome process of manual labeling, computer graphics rendering is employed to automatically generate a large corpus of annotated eye images under various conditions. In this work, we introduce a synthetic eye image generation platform that improves upon previous work by adding features such as an active deformable iris, an aspherical cornea, retinal retro-reflection, gaze-coordinated eye-lid deformations, and blinks. To demonstrate the utility of our platform, we render images reflecting the represented gaze distributions inherent in two publicly available datasets, NVGaze and OpenEDS. We also report on the performance of two semantic segmentation architectures (SegNet and RITnet) trained on rendered images and tested on the original datasets.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019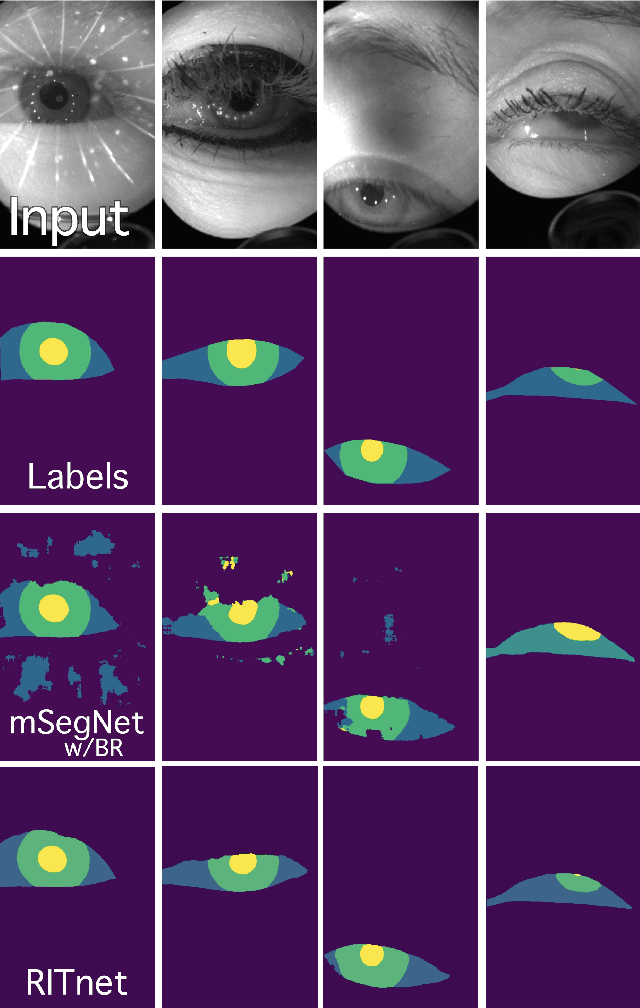
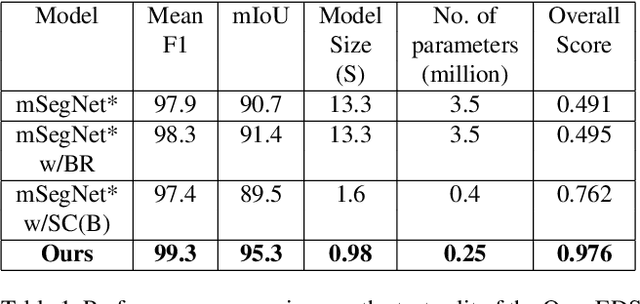
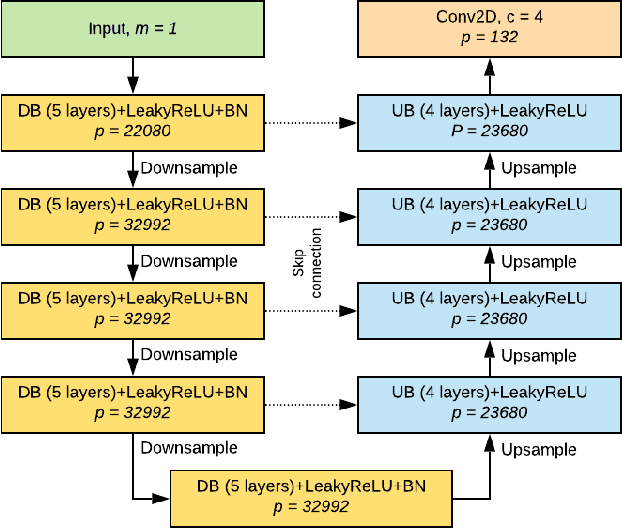
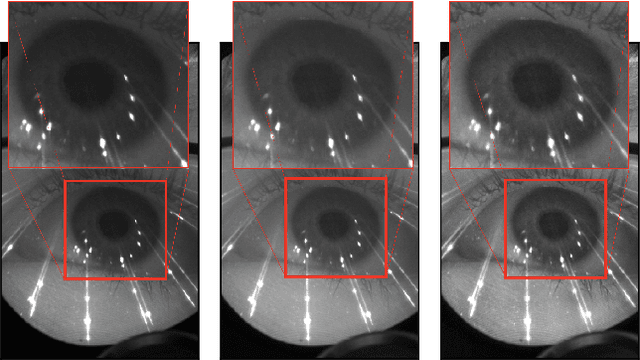
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
Gaze-in-wild: A dataset for studying eye and head coordination in everyday activities
May 09, 2019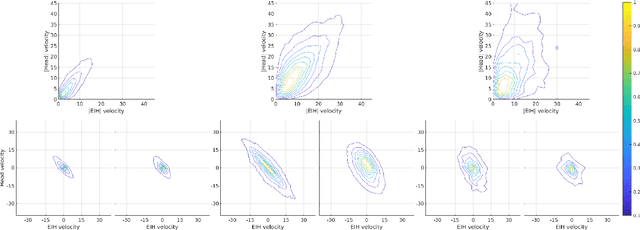
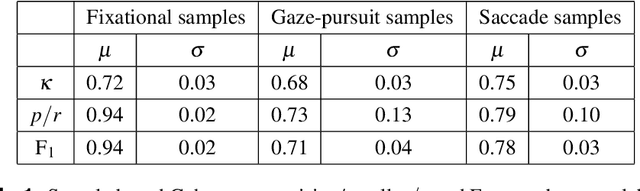

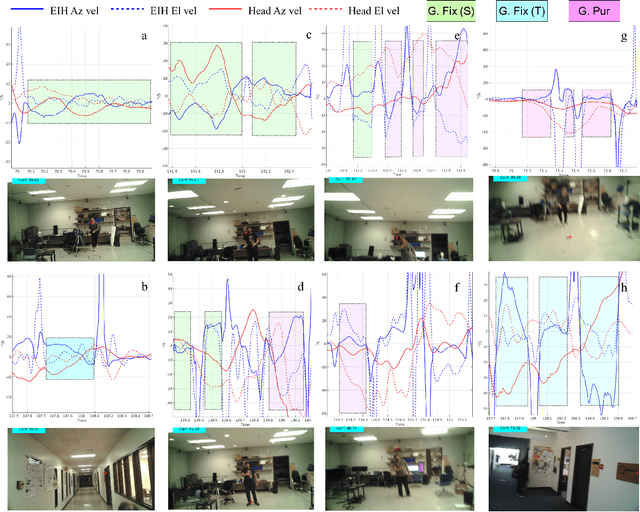
The interaction between the vestibular and ocular system has primarily been studied in controlled environments. Consequently, off-the shelf tools for categorization of gaze events (e.g. fixations, pursuits, saccade) fail when head movements are allowed. Our approach was to collect a novel, naturalistic, and multimodal dataset of eye+head movements when subjects performed everyday tasks while wearing a mobile eye tracker equipped with an inertial measurement unit and a 3D stereo camera. This Gaze-in-the-Wild dataset (GW) includes eye+head rotational velocities (deg/s), infrared eye images and scene imagery (RGB+D). A portion was labelled by coders into gaze motion events with a mutual agreement of 0.72 sample based Cohen's $\kappa$. This labelled data was used to train and evaluate two machine learning algorithms, Random Forest and a Recurrent Neural Network model, for gaze event classification. Assessment involved the application of established and novel event based performance metrics. Classifiers achieve $\sim$90$\%$ human performance in detecting fixations and saccades but fall short (60$\%$) on detecting pursuit movements. Moreover, pursuit classification is far worse in the absence of head movement information. A subsequent analysis of feature significance in our best-performing model revealed a reliance upon absolute eye and head velocity, indicating that classification does not require spatial alignment of the head and eye tracking coordinate systems. The GW dataset, trained classifiers and evaluation metrics will be made publicly available with the intention of facilitating growth in the emerging area of head-free gaze event classification.