 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Parallel Sequence Models to Foundation-Scale Vision Encoders
May 30, 2026Vision foundation models are bottlenecked by the quadratic cost of self-attention, which limits usable resolution and increases the cost of large-scale pretraining. Subquadratic alternatives such as linear attention and state-space models reduce this cost, but often serialize images into 1D token streams and weaken the 2D spatial structure important for vision. Generalized Spatial Propagation Networks (GSPN) instead propagate context directly on the 2D grid through line-scan recurrences, achieving near-linear complexity without positional embeddings, but have seen little use as foundation-scale encoders. We present C-GSPN, a foundation-scale vision encoder based on 2D spatial propagation. C-GSPN makes the operator practical through three improvements: (1) a fast GSPN CUDA kernel that fuses per-step launches into a single warp-specialized implementation with shared-memory tiling, coalesced access, and a compact multi-channel propagation, reaching over 90% of peak memory bandwidth and running up to 40--52x faster than the original GSPN implementation; (2) a compressed latent-space propagation block with fused normalization, which turns kernel-level speed into block- and model-level efficiency; and (3) a two-stage cross-operator distillation recipe that trains the new architecture from an attention teacher without the cost of from-scratch foundation-scale training. Distilled with 600M image-text pairs, C-GSPN matches an isomorphic ViT baseline with 15% fewer parameters, improves ADE20K segmentation by +2.1%, transfers to high resolution with a fraction of the data needed from scratch, and delivers a 4x end-to-end block speedup at 2K with single-pass, tiling-free inference.
Stateful Token Reduction for Long-Video Hybrid VLMs
Feb 27, 2026Token reduction is an effective way to accelerate long-video vision-language models (VLMs), but most existing methods are designed for dense Transformers and do not directly account for hybrid architectures that interleave attention with linear-time state-space blocks (e.g., Mamba). We study query-conditioned token reduction for hybrid video VLMs and analyze reduction behavior through two properties: layerwise sparsity (how many tokens capture query-relevant information) and importance stability (whether token-importance rankings persist across depth). Although token importance is sparse within each layer, the set of important tokens changes across layers, so aggressive early pruning is unreliable. Motivated by this, we propose a low-to-high progressive reduction schedule and a unified language-aware scoring mechanism for both attention and Mamba blocks (using an implicit-attention proxy for Mamba), enabling all-layer token reduction in hybrids. Under an aggressive compression setting (retaining 25% of visual tokens), our approach delivers substantial prefilling speedups (3.8--4.2x) with near-baseline accuracy at test time, and light finetuning under reduction further improves performance on long-context video benchmarks.
Demystifying Data-Driven Probabilistic Medium-Range Weather Forecasting
Jan 26, 2026The recent revolution in data-driven methods for weather forecasting has lead to a fragmented landscape of complex, bespoke architectures and training strategies, obscuring the fundamental drivers of forecast accuracy. Here, we demonstrate that state-of-the-art probabilistic skill requires neither intricate architectural constraints nor specialized training heuristics. We introduce a scalable framework for learning multi-scale atmospheric dynamics by combining a directly downsampled latent space with a history-conditioned local projector that resolves high-resolution physics. We find that our framework design is robust to the choice of probabilistic estimator, seamlessly supporting stochastic interpolants, diffusion models, and CRPS-based ensemble training. Validated against the Integrated Forecasting System and the deep learning probabilistic model GenCast, our framework achieves statistically significant improvements on most of the variables. These results suggest scaling a general-purpose model is sufficient for state-of-the-art medium-range prediction, eliminating the need for tailored training recipes and proving effective across the full spectrum of probabilistic frameworks.
M$^3$KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation
Dec 24, 2025Retrieval-Augmented Generation (RAG) has recently been extended to multimodal settings, connecting multimodal large language models (MLLMs) with vast corpora of external knowledge such as multimodal knowledge graphs (MMKGs). Despite their recent success, multimodal RAG in the audio-visual domain remains challenging due to 1) limited modality coverage and multi-hop connectivity of existing MMKGs, and 2) retrieval based solely on similarity in a shared multimodal embedding space, which fails to filter out off-topic or redundant knowledge. To address these limitations, we propose M$^3$KG-RAG, a Multi-hop Multimodal Knowledge Graph-enhanced RAG that retrieves query-aligned audio-visual knowledge from MMKGs, improving reasoning depth and answer faithfulness in MLLMs. Specifically, we devise a lightweight multi-agent pipeline to construct multi-hop MMKG (M$^3$KG), which contains context-enriched triplets of multimodal entities, enabling modality-wise retrieval based on input queries. Furthermore, we introduce GRASP (Grounded Retrieval And Selective Pruning), which ensures precise entity grounding to the query, evaluates answer-supporting relevance, and prunes redundant context to retain only knowledge essential for response generation. Extensive experiments across diverse multimodal benchmarks demonstrate that M$^3$KG-RAG significantly enhances MLLMs' multimodal reasoning and grounding over existing approaches.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Apr 21, 2025We introduce Eagle 2.5, a family of frontier vision-language models (VLMs) for long-context multimodal learning. Our work addresses the challenges in long video comprehension and high-resolution image understanding, introducing a generalist framework for both tasks. The proposed training framework incorporates Automatic Degrade Sampling and Image Area Preservation, two techniques that preserve contextual integrity and visual details. The framework also includes numerous efficiency optimizations in the pipeline for long-context data training. Finally, we propose Eagle-Video-110K, a novel dataset that integrates both story-level and clip-level annotations, facilitating long-video understanding. Eagle 2.5 demonstrates substantial improvements on long-context multimodal benchmarks, providing a robust solution to the limitations of existing VLMs. Notably, our best model Eagle 2.5-8B achieves 72.4% on Video-MME with 512 input frames, matching the results of top-tier commercial model such as GPT-4o and large-scale open-source models like Qwen2.5-VL-72B and InternVL2.5-78B.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025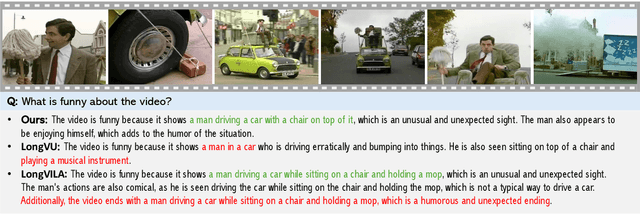
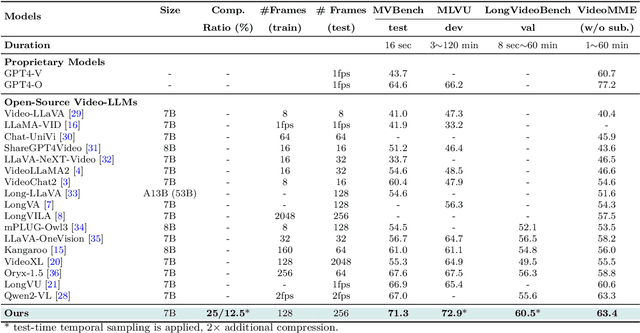
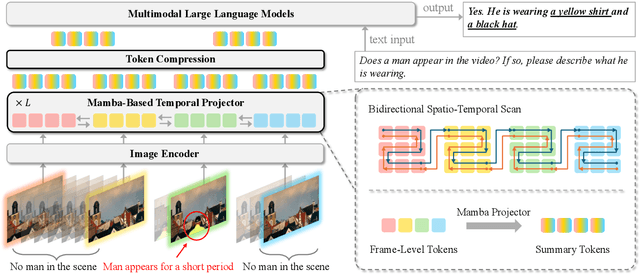
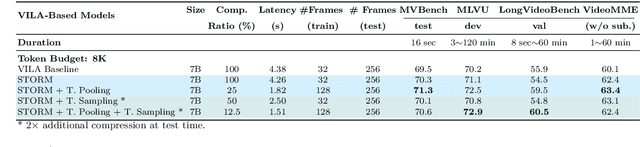
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
Feature-based Graph Attention Networks Improve Online Continual Learning
Feb 13, 2025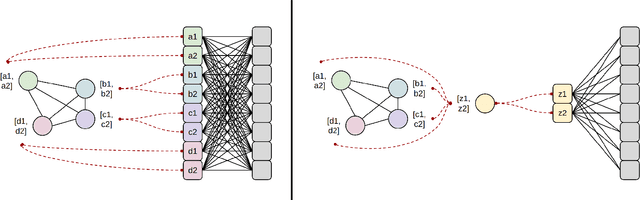
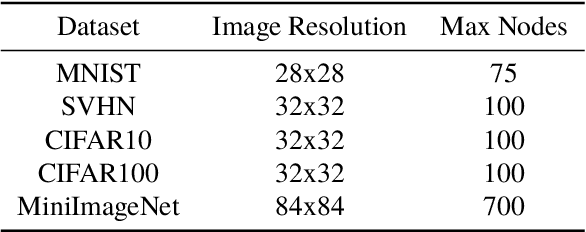
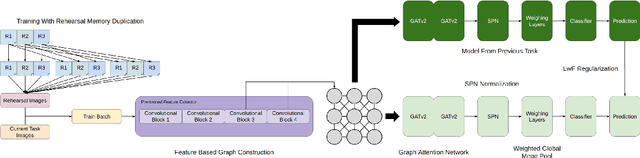

Online continual learning for image classification is crucial for models to adapt to new data while retaining knowledge of previously learned tasks. This capability is essential to address real-world challenges involving dynamic environments and evolving data distributions. Traditional approaches predominantly employ Convolutional Neural Networks, which are limited to processing images as grids and primarily capture local patterns rather than relational information. Although the emergence of transformer architectures has improved the ability to capture relationships, these models often require significantly larger resources. In this paper, we present a novel online continual learning framework based on Graph Attention Networks (GATs), which effectively capture contextual relationships and dynamically update the task-specific representation via learned attention weights. Our approach utilizes a pre-trained feature extractor to convert images into graphs using hierarchical feature maps, representing information at varying levels of granularity. These graphs are then processed by a GAT and incorporate an enhanced global pooling strategy to improve classification performance for continual learning. In addition, we propose the rehearsal memory duplication technique that improves the representation of the previous tasks while maintaining the memory budget. Comprehensive evaluations on benchmark datasets, including SVHN, CIFAR10, CIFAR100, and MiniImageNet, demonstrate the superiority of our method compared to the state-of-the-art methods.
Parallel Sequence Modeling via Generalized Spatial Propagation Network
Jan 21, 2025



We present the Generalized Spatial Propagation Network (GSPN), a new attention mechanism optimized for vision tasks that inherently captures 2D spatial structures. Existing attention models, including transformers, linear attention, and state-space models like Mamba, process multi-dimensional data as 1D sequences, compromising spatial coherence and efficiency. GSPN overcomes these limitations by directly operating on spatially coherent image data and forming dense pairwise connections through a line-scan approach. Central to GSPN is the Stability-Context Condition, which ensures stable, context-aware propagation across 2D sequences and reduces the effective sequence length to $\sqrt{N}$ for a square map with N elements, significantly enhancing computational efficiency. With learnable, input-dependent weights and no reliance on positional embeddings, GSPN achieves superior spatial fidelity and state-of-the-art performance in vision tasks, including ImageNet classification, class-guided image generation, and text-to-image generation. Notably, GSPN accelerates SD-XL with softmax-attention by over $84\times$ when generating 16K images.