 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Expressive Gaussian Head Avatar via 3D-Aware Expression Distillation
Dec 18, 2025Portrait animation has witnessed tremendous quality improvements thanks to recent advances in video diffusion models. However, these 2D methods often compromise 3D consistency and speed, limiting their applicability in real-world scenarios, such as digital twins or telepresence. In contrast, 3D-aware facial animation feedforward methods -- built upon explicit 3D representations, such as neural radiance fields or Gaussian splatting -- ensure 3D consistency and achieve faster inference speed, but come with inferior expression details. In this paper, we aim to combine their strengths by distilling knowledge from a 2D diffusion-based method into a feed-forward encoder, which instantly converts an in-the-wild single image into a 3D-consistent, fast yet expressive animatable representation. Our animation representation is decoupled from the face's 3D representation and learns motion implicitly from data, eliminating the dependency on pre-defined parametric models that often constrain animation capabilities. Unlike previous computationally intensive global fusion mechanisms (e.g., multiple attention layers) for fusing 3D structural and animation information, our design employs an efficient lightweight local fusion strategy to achieve high animation expressivity. As a result, our method runs at 107.31 FPS for animation and pose control while achieving comparable animation quality to the state-of-the-art, surpassing alternative designs that trade speed for quality or vice versa. Project website is https://research.nvidia.com/labs/amri/projects/instant4d
Feature-based Graph Attention Networks Improve Online Continual Learning
Feb 13, 2025
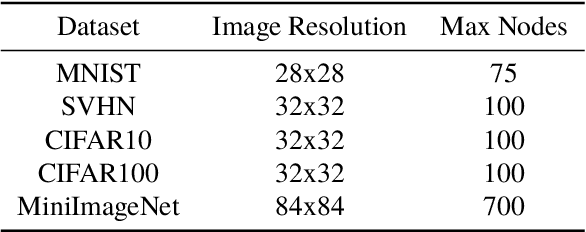
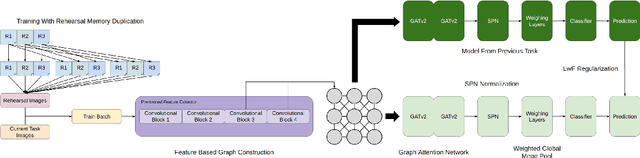

Online continual learning for image classification is crucial for models to adapt to new data while retaining knowledge of previously learned tasks. This capability is essential to address real-world challenges involving dynamic environments and evolving data distributions. Traditional approaches predominantly employ Convolutional Neural Networks, which are limited to processing images as grids and primarily capture local patterns rather than relational information. Although the emergence of transformer architectures has improved the ability to capture relationships, these models often require significantly larger resources. In this paper, we present a novel online continual learning framework based on Graph Attention Networks (GATs), which effectively capture contextual relationships and dynamically update the task-specific representation via learned attention weights. Our approach utilizes a pre-trained feature extractor to convert images into graphs using hierarchical feature maps, representing information at varying levels of granularity. These graphs are then processed by a GAT and incorporate an enhanced global pooling strategy to improve classification performance for continual learning. In addition, we propose the rehearsal memory duplication technique that improves the representation of the previous tasks while maintaining the memory budget. Comprehensive evaluations on benchmark datasets, including SVHN, CIFAR10, CIFAR100, and MiniImageNet, demonstrate the superiority of our method compared to the state-of-the-art methods.
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Dec 12, 2024We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
Coherent3D: Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Dec 11, 2024


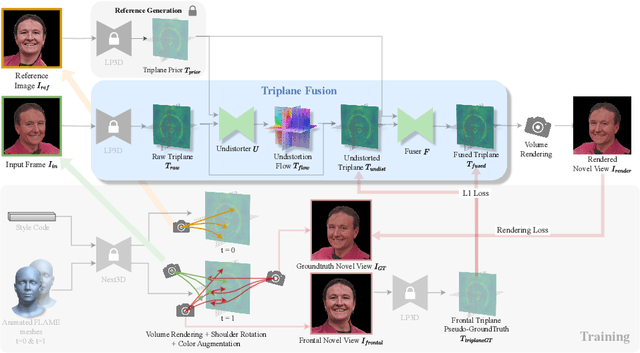
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a 3D avatar built from a single reference image, but fail to faithfully preserve the user's per-frame appearance (e.g., instantaneous facial expression and lighting). As a result, none of these two frameworks is an ideal solution for democratized 3D telepresence. In this work, we address this dilemma and propose a novel solution that maintains both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that takes the best of both worlds by fusing a canonical 3D prior from a reference view with dynamic appearance from per-frame input views, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearance. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction and temporal consistency on in-studio and in-the-wild datasets. https://research.nvidia.com/labs/amri/projects/coherent3d
BLADE: Single-view Body Mesh Learning through Accurate Depth Estimation
Dec 11, 2024



Single-image human mesh recovery is a challenging task due to the ill-posed nature of simultaneous body shape, pose, and camera estimation. Existing estimators work well on images taken from afar, but they break down as the person moves close to the camera. Moreover, current methods fail to achieve both accurate 3D pose and 2D alignment at the same time. Error is mainly introduced by inaccurate perspective projection heuristically derived from orthographic parameters. To resolve this long-standing challenge, we present our method BLADE which accurately recovers perspective parameters from a single image without heuristic assumptions. We start from the inverse relationship between perspective distortion and the person's Z-translation Tz, and we show that Tz can be reliably estimated from the image. We then discuss the important role of Tz for accurate human mesh recovery estimated from close-range images. Finally, we show that, once Tz and the 3D human mesh are estimated, one can accurately recover the focal length and full 3D translation. Extensive experiments on standard benchmarks and real-world close-range images show that our method is the first to accurately recover projection parameters from a single image, and consequently attain state-of-the-art accuracy on 3D pose estimation and 2D alignment for a wide range of images. https://research.nvidia.com/labs/amri/projects/blade/
QUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Dec 05, 2024
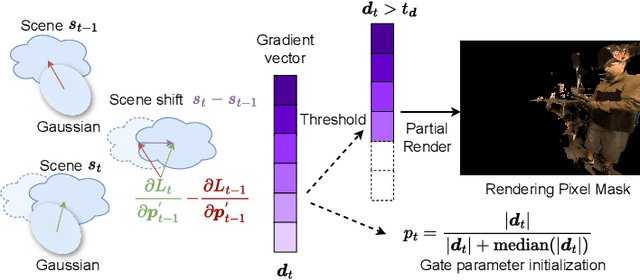


Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen
Coherent 3D Portrait Video Reconstruction via Triplane Fusion
May 01, 2024Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
RegionGPT: Towards Region Understanding Vision Language Model
Mar 04, 2024

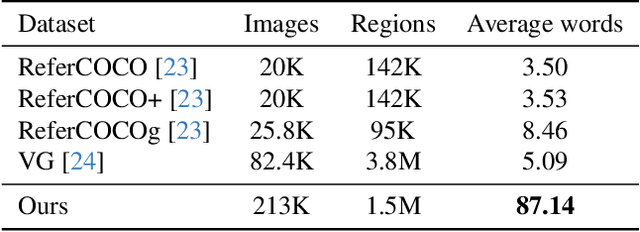

Vision language models (VLMs) have experienced rapid advancements through the integration of large language models (LLMs) with image-text pairs, yet they struggle with detailed regional visual understanding due to limited spatial awareness of the vision encoder, and the use of coarse-grained training data that lacks detailed, region-specific captions. To address this, we introduce RegionGPT (short as RGPT), a novel framework designed for complex region-level captioning and understanding. RGPT enhances the spatial awareness of regional representation with simple yet effective modifications to existing visual encoders in VLMs. We further improve performance on tasks requiring a specific output scope by integrating task-guided instruction prompts during both training and inference phases, while maintaining the model's versatility for general-purpose tasks. Additionally, we develop an automated region caption data generation pipeline, enriching the training set with detailed region-level captions. We demonstrate that a universal RGPT model can be effectively applied and significantly enhancing performance across a range of region-level tasks, including but not limited to complex region descriptions, reasoning, object classification, and referring expressions comprehension.
What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Jan 04, 2024



3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly "render every pixel" of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
Dec 18, 2023



Gaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., flexibility and efficiency) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animation. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use neural implicit fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at 1K resolution.