 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLADE: Single-view Body Mesh Learning through Accurate Depth Estimation
Dec 11, 2024



Single-image human mesh recovery is a challenging task due to the ill-posed nature of simultaneous body shape, pose, and camera estimation. Existing estimators work well on images taken from afar, but they break down as the person moves close to the camera. Moreover, current methods fail to achieve both accurate 3D pose and 2D alignment at the same time. Error is mainly introduced by inaccurate perspective projection heuristically derived from orthographic parameters. To resolve this long-standing challenge, we present our method BLADE which accurately recovers perspective parameters from a single image without heuristic assumptions. We start from the inverse relationship between perspective distortion and the person's Z-translation Tz, and we show that Tz can be reliably estimated from the image. We then discuss the important role of Tz for accurate human mesh recovery estimated from close-range images. Finally, we show that, once Tz and the 3D human mesh are estimated, one can accurately recover the focal length and full 3D translation. Extensive experiments on standard benchmarks and real-world close-range images show that our method is the first to accurately recover projection parameters from a single image, and consequently attain state-of-the-art accuracy on 3D pose estimation and 2D alignment for a wide range of images. https://research.nvidia.com/labs/amri/projects/blade/
Coherent3D: Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Dec 11, 2024


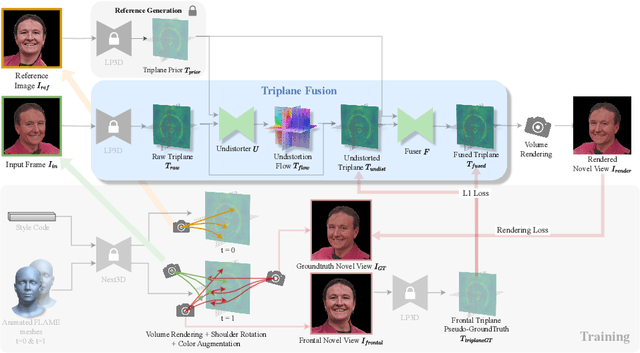
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a 3D avatar built from a single reference image, but fail to faithfully preserve the user's per-frame appearance (e.g., instantaneous facial expression and lighting). As a result, none of these two frameworks is an ideal solution for democratized 3D telepresence. In this work, we address this dilemma and propose a novel solution that maintains both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that takes the best of both worlds by fusing a canonical 3D prior from a reference view with dynamic appearance from per-frame input views, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearance. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction and temporal consistency on in-studio and in-the-wild datasets. https://research.nvidia.com/labs/amri/projects/coherent3d
Coherent 3D Portrait Video Reconstruction via Triplane Fusion
May 01, 2024Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
DELIFFAS: Deformable Light Fields for Fast Avatar Synthesis
Oct 17, 2023



Generating controllable and photorealistic digital human avatars is a long-standing and important problem in Vision and Graphics. Recent methods have shown great progress in terms of either photorealism or inference speed while the combination of the two desired properties still remains unsolved. To this end, we propose a novel method, called DELIFFAS, which parameterizes the appearance of the human as a surface light field that is attached to a controllable and deforming human mesh model. At the core, we represent the light field around the human with a deformable two-surface parameterization, which enables fast and accurate inference of the human appearance. This allows perceptual supervision on the full image compared to previous approaches that could only supervise individual pixels or small patches due to their slow runtime. Our carefully designed human representation and supervision strategy leads to state-of-the-art synthesis results and inference time. The video results and code are available at https://vcai.mpi-inf.mpg.de/projects/DELIFFAS.
Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling
Apr 10, 2023



We present a method that enables synthesizing novel views and novel poses of arbitrary human performers from sparse multi-view images. A key ingredient of our method is a hybrid appearance blending module that combines the advantages of the implicit body NeRF representation and image-based rendering. Existing generalizable human NeRF methods that are conditioned on the body model have shown robustness against the geometric variation of arbitrary human performers. Yet they often exhibit blurry results when generalized onto unseen identities. Meanwhile, image-based rendering shows high-quality results when sufficient observations are available, whereas it suffers artifacts in sparse-view settings. We propose Neural Image-based Avatars (NIA) that exploits the best of those two methods: to maintain robustness under new articulations and self-occlusions while directly leveraging the available (sparse) source view colors to preserve appearance details of new subject identities. Our hybrid design outperforms recent methods on both in-domain identity generalization as well as challenging cross-dataset generalization settings. Also, in terms of the pose generalization, our method outperforms even the per-subject optimized animatable NeRF methods. The video results are available at https://youngjoongunc.github.io/nia
Bringing Telepresence to Every Desk
Apr 03, 2023



In this paper, we work to bring telepresence to every desktop. Unlike commercial systems, personal 3D video conferencing systems must render high-quality videos while remaining financially and computationally viable for the average consumer. To this end, we introduce a capturing and rendering system that only requires 4 consumer-grade RGBD cameras and synthesizes high-quality free-viewpoint videos of users as well as their environments. Experimental results show that our system renders high-quality free-viewpoint videos without using object templates or heavy pre-processing. While not real-time, our system is fast and does not require per-video optimizations. Moreover, our system is robust to complex hand gestures and clothing, and it can generalize to new users. This work provides a strong basis for further optimization, and it will help bring telepresence to every desk in the near future. The code and dataset will be made available on our website https://mcmvmc.github.io/PersonalTelepresence/.
INV: Towards Streaming Incremental Neural Videos
Feb 03, 2023Recent works in spatiotemporal radiance fields can produce photorealistic free-viewpoint videos. However, they are inherently unsuitable for interactive streaming scenarios (e.g. video conferencing, telepresence) because have an inevitable lag even if the training is instantaneous. This is because these approaches consume videos and thus have to buffer chunks of frames (often seconds) before processing. In this work, we take a step towards interactive streaming via a frame-by-frame approach naturally free of lag. Conventional wisdom believes that per-frame NeRFs are impractical due to prohibitive training costs and storage. We break this belief by introducing Incremental Neural Videos (INV), a per-frame NeRF that is efficiently trained and streamable. We designed INV based on two insights: (1) Our main finding is that MLPs naturally partition themselves into Structure and Color Layers, which store structural and color/texture information respectively. (2) We leverage this property to retain and improve upon knowledge from previous frames, thus amortizing training across frames and reducing redundant learning. As a result, with negligible changes to NeRF, INV can achieve good qualities (>28.6db) in 8min/frame. It can also outperform prior SOTA in 19% less training time. Additionally, our Temporal Weight Compression reduces the per-frame size to 0.3MB/frame (6.6% of NeRF). More importantly, INV is free from buffer lag and is naturally fit for streaming. While this work does not achieve real-time training, it shows that incremental approaches like INV present new possibilities in interactive 3D streaming. Moreover, our discovery of natural information partition leads to a better understanding and manipulation of MLPs. Code and dataset will be released soon.
Learning Dynamic View Synthesis With Few RGBD Cameras
Apr 22, 2022
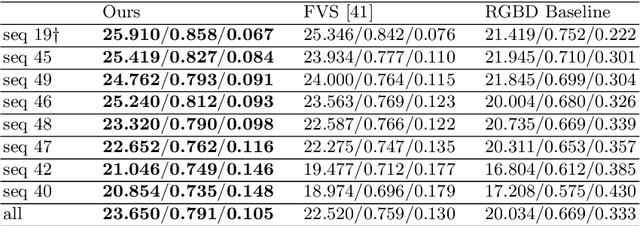
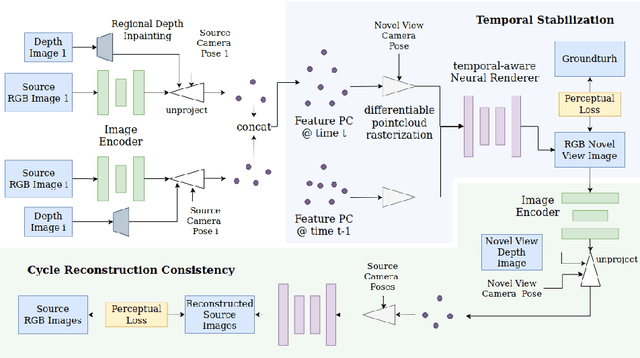

There have been significant advancements in dynamic novel view synthesis in recent years. However, current deep learning models often require (1) prior models (e.g., SMPL human models), (2) heavy pre-processing, or (3) per-scene optimization. We propose to utilize RGBD cameras to remove these limitations and synthesize free-viewpoint videos of dynamic indoor scenes. We generate feature point clouds from RGBD frames and then render them into free-viewpoint videos via a neural renderer. However, the inaccurate, unstable, and incomplete depth measurements induce severe distortions, flickering, and ghosting artifacts. We enforce spatial-temporal consistency via the proposed Cycle Reconstruction Consistency and Temporal Stabilization module to reduce these artifacts. We introduce a simple Regional Depth-Inpainting module that adaptively inpaints missing depth values to render complete novel views. Additionally, we present a Human-Things Interactions dataset to validate our approach and facilitate future research. The dataset consists of 43 multi-view RGBD video sequences of everyday activities, capturing complex interactions between human subjects and their surroundings. Experiments on the HTI dataset show that our method outperforms the baseline per-frame image fidelity and spatial-temporal consistency. We will release our code, and the dataset on the website soon.
Echo-Reconstruction: Audio-Augmented 3D Scene Reconstruction
Oct 05, 2021


Reflective and textureless surfaces such as windows, mirrors, and walls can be a challenge for object and scene reconstruction. These surfaces are often poorly reconstructed and filled with depth discontinuities and holes, making it difficult to cohesively reconstruct scenes that contain these planar discontinuities. We propose Echoreconstruction, an audio-visual method that uses the reflections of sound to aid in geometry and audio reconstruction for virtual conferencing, teleimmersion, and other AR/VR experience. The mobile phone prototype emits pulsed audio, while recording video for RGB-based 3D reconstruction and audio-visual classification. Reflected sound and images from the video are input into our audio (EchoCNN-A) and audio-visual (EchoCNN-AV) convolutional neural networks for surface and sound source detection, depth estimation, and material classification. The inferences from these classifications enhance scene 3D reconstructions containing open spaces and reflective surfaces by depth filtering, inpainting, and placement of unmixed sound sources in the scene. Our prototype, VR demo, and experimental results from real-world and virtual scenes with challenging surfaces and sound indicate high success rates on classification of material, depth estimation, and closed/open surfaces, leading to considerable visual and audio improvement in 3D scenes (see Figure 1).
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021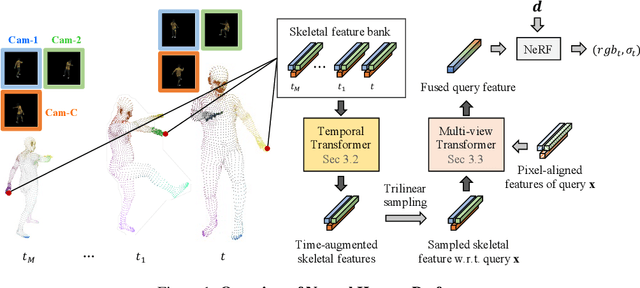
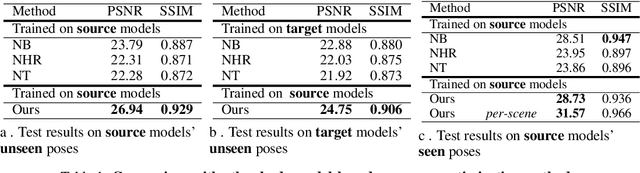


In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.