 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Aging with Audio-Visual Style Transfer
Oct 05, 2021
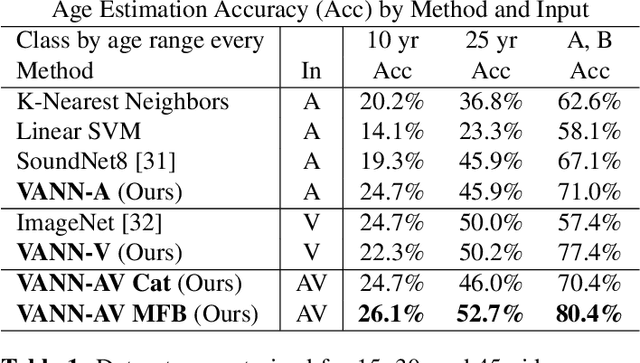
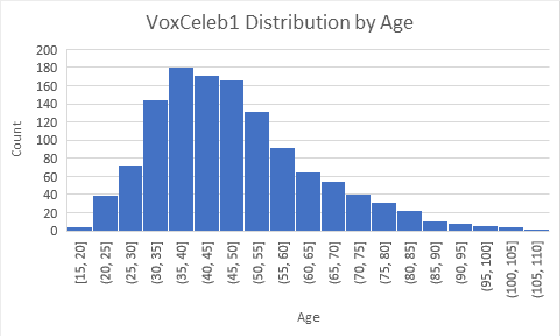
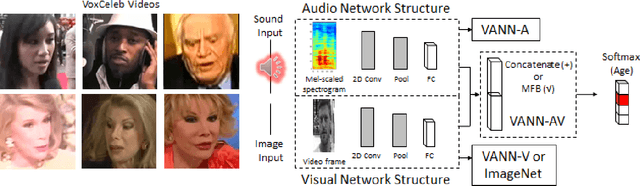
Face aging techniques have used generative adversarial networks (GANs) and style transfer learning to transform one's appearance to look younger/older. Identity is maintained by conditioning these generative networks on a learned vector representation of the source content. In this work, we apply a similar approach to age a speaker's voice, referred to as voice aging. We first analyze the classification of a speaker's age by training a convolutional neural network (CNN) on the speaker's voice and face data from Common Voice and VoxCeleb datasets. We generate aged voices from style transfer to transform an input spectrogram to various ages and demonstrate our method on a mobile app.
Echo-Reconstruction: Audio-Augmented 3D Scene Reconstruction
Oct 05, 2021


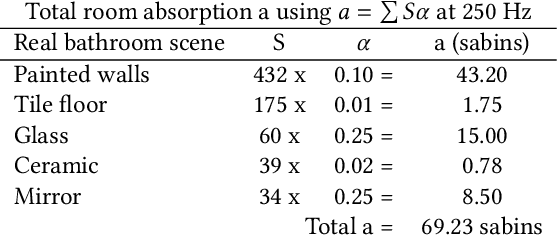
Reflective and textureless surfaces such as windows, mirrors, and walls can be a challenge for object and scene reconstruction. These surfaces are often poorly reconstructed and filled with depth discontinuities and holes, making it difficult to cohesively reconstruct scenes that contain these planar discontinuities. We propose Echoreconstruction, an audio-visual method that uses the reflections of sound to aid in geometry and audio reconstruction for virtual conferencing, teleimmersion, and other AR/VR experience. The mobile phone prototype emits pulsed audio, while recording video for RGB-based 3D reconstruction and audio-visual classification. Reflected sound and images from the video are input into our audio (EchoCNN-A) and audio-visual (EchoCNN-AV) convolutional neural networks for surface and sound source detection, depth estimation, and material classification. The inferences from these classifications enhance scene 3D reconstructions containing open spaces and reflective surfaces by depth filtering, inpainting, and placement of unmixed sound sources in the scene. Our prototype, VR demo, and experimental results from real-world and virtual scenes with challenging surfaces and sound indicate high success rates on classification of material, depth estimation, and closed/open surfaces, leading to considerable visual and audio improvement in 3D scenes (see Figure 1).
3D-MOV: Audio-Visual LSTM Autoencoder for 3D Reconstruction of Multiple Objects from Video
Oct 05, 2021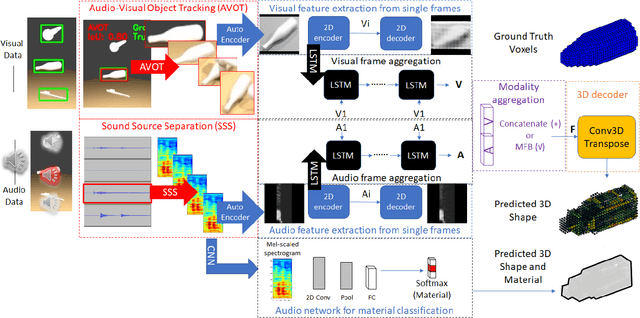
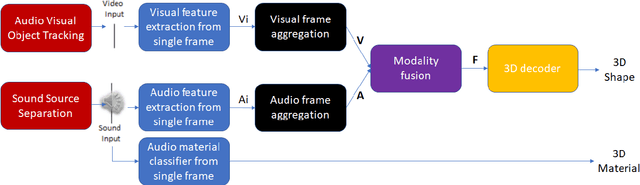
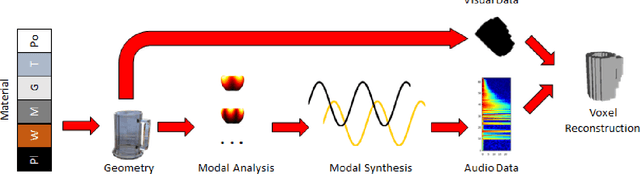
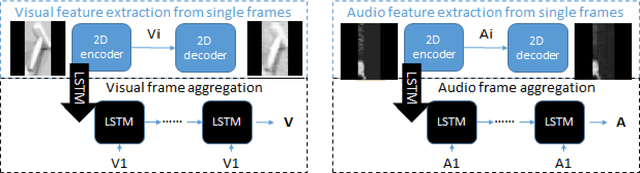
3D object reconstructions of transparent and concave structured objects, with inferred material properties, remains an open research problem for robot navigation in unstructured environments. In this paper, we propose a multimodal single- and multi-frame neural network for 3D reconstructions using audio-visual inputs. Our trained reconstruction LSTM autoencoder 3D-MOV accepts multiple inputs to account for a variety of surface types and views. Our neural network produces high-quality 3D reconstructions using voxel representation. Based on Intersection-over-Union (IoU), we evaluate against other baseline methods using synthetic audio-visual datasets ShapeNet and Sound20K with impact sounds and bounding box annotations. To the best of our knowledge, our single- and multi-frame model is the first audio-visual reconstruction neural network for 3D geometry and material representation.