 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-MOV: Audio-Visual LSTM Autoencoder for 3D Reconstruction of Multiple Objects from Video
Paper and Code
Oct 05, 2021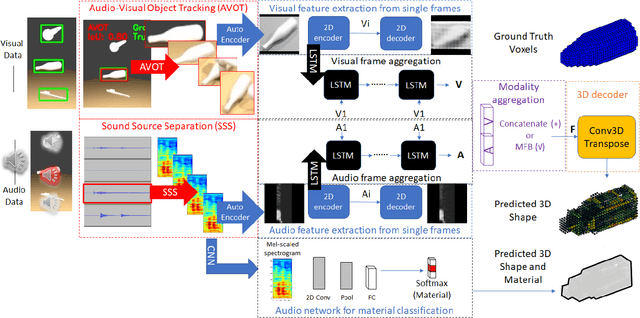
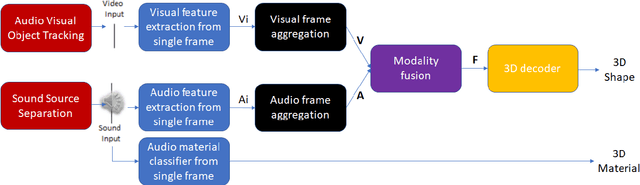
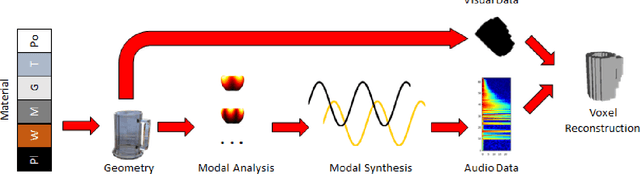
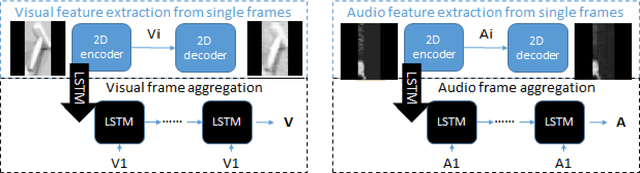
3D object reconstructions of transparent and concave structured objects, with inferred material properties, remains an open research problem for robot navigation in unstructured environments. In this paper, we propose a multimodal single- and multi-frame neural network for 3D reconstructions using audio-visual inputs. Our trained reconstruction LSTM autoencoder 3D-MOV accepts multiple inputs to account for a variety of surface types and views. Our neural network produces high-quality 3D reconstructions using voxel representation. Based on Intersection-over-Union (IoU), we evaluate against other baseline methods using synthetic audio-visual datasets ShapeNet and Sound20K with impact sounds and bounding box annotations. To the best of our knowledge, our single- and multi-frame model is the first audio-visual reconstruction neural network for 3D geometry and material representation.