 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking Shortcuts for Categorical VQA Using Super Neurons
Mar 11, 2026Sparse Attention Vectors (SAVs) have emerged as an excellent training-free alternative to supervised finetuning or low-rank adaptation to improve the performance of Vision Language Models (VLMs). At their heart, SAVs select a few accurate attention heads for a task of interest and use them as classifiers, rather than relying on the model's prediction. In a similar spirit, we find that directly probing the raw activations of the VLM, in the form of scalar values, is sufficient to yield accurate classifiers on diverse visually grounded downstream tasks. Shifting focus from attention vectors to scalar activations dramatically increases the search space for accurate parameters, allowing us to find more discriminative neurons immediately from the first generated token. We call such activations Super Neurons (SNs). In this probing setting, we discover that enough SNs appear in the shallower layers of the large language model to allow for extreme early exiting from the first layer of the model at the first generated token. Compared to the original network, SNs robustly improve the classification performance while achieving a speedup of up to 5.10x.
Time-Scaling State-Space Models for Dense Video Captioning
Sep 03, 2025Dense video captioning is a challenging video understanding task which aims to simultaneously segment the video into a sequence of meaningful consecutive events and to generate detailed captions to accurately describe each event. Existing methods often encounter difficulties when working with the long videos associated with dense video captioning, due to the computational complexity and memory limitations. Furthermore, traditional approaches require the entire video as input, in order to produce an answer, which precludes online processing of the video. We address these challenges by time-scaling State-Space Models (SSMs) to even longer sequences than before. Our approach, State-Space Models with Transfer State, combines both the long-sequence and recurrent properties of SSMs and addresses the main limitation of SSMs which are otherwise not able to sustain their state for very long contexts, effectively scaling SSMs further in time. The proposed model is particularly suitable for generating captions on-the-fly, in an online or streaming manner, without having to wait for the full video to be processed, which is more beneficial in practice. When applied to dense video captioning, our approach scales well with video lengths and uses 7x fewer FLOPs.
VideoComp: Advancing Fine-Grained Compositional and Temporal Alignment in Video-Text Models
Apr 10, 2025



We introduce VideoComp, a benchmark and learning framework for advancing video-text compositionality understanding, aimed at improving vision-language models (VLMs) in fine-grained temporal alignment. Unlike existing benchmarks focused on static image-text compositionality or isolated single-event videos, our benchmark targets alignment in continuous multi-event videos. Leveraging video-text datasets with temporally localized event captions (e.g. ActivityNet-Captions, YouCook2), we construct two compositional benchmarks, ActivityNet-Comp and YouCook2-Comp. We create challenging negative samples with subtle temporal disruptions such as reordering, action word replacement, partial captioning, and combined disruptions. These benchmarks comprehensively test models' compositional sensitivity across extended, cohesive video-text sequences. To improve model performance, we propose a hierarchical pairwise preference loss that strengthens alignment with temporally accurate pairs and gradually penalizes increasingly disrupted ones, encouraging fine-grained compositional learning. To mitigate the limited availability of densely annotated video data, we introduce a pretraining strategy that concatenates short video-caption pairs to simulate multi-event sequences. We evaluate video-text foundational models and large multimodal models (LMMs) on our benchmark, identifying both strengths and areas for improvement in compositionality. Overall, our work provides a comprehensive framework for evaluating and enhancing model capabilities in achieving fine-grained, temporally coherent video-text alignment.
Whats in a Video: Factorized Autoregressive Decoding for Online Dense Video Captioning
Nov 22, 2024



Generating automatic dense captions for videos that accurately describe their contents remains a challenging area of research. Most current models require processing the entire video at once. Instead, we propose an efficient, online approach which outputs frequent, detailed and temporally aligned captions, without access to future frames. Our model uses a novel autoregressive factorized decoding architecture, which models the sequence of visual features for each time segment, outputting localized descriptions and efficiently leverages the context from the previous video segments. This allows the model to output frequent, detailed captions to more comprehensively describe the video, according to its actual local content, rather than mimic the training data. Second, we propose an optimization for efficient training and inference, which enables scaling to longer videos. Our approach shows excellent performance compared to both offline and online methods, and uses 20\% less compute. The annotations produced are much more comprehensive and frequent, and can further be utilized in automatic video tagging and in large-scale video data harvesting.
Learning Visual Grounding from Generative Vision and Language Model
Jul 18, 2024



Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
OmniBind: Teach to Build Unequal-Scale Modality Interaction for Omni-Bind of All
May 25, 2024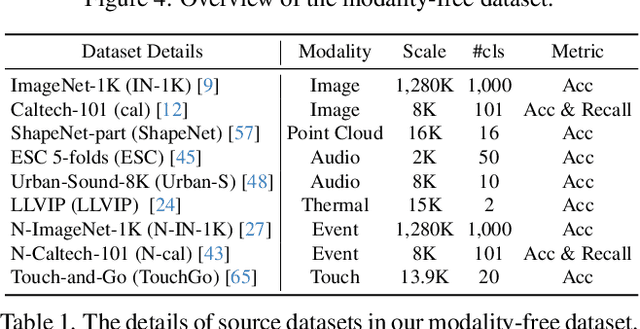
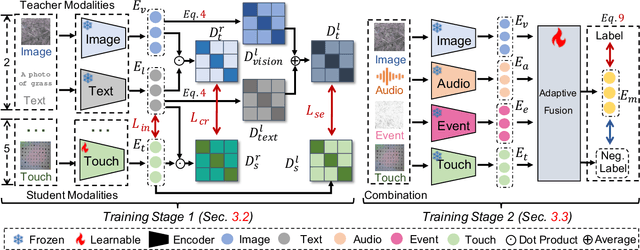
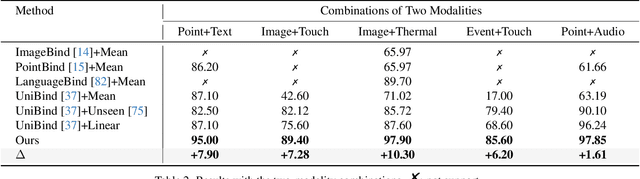
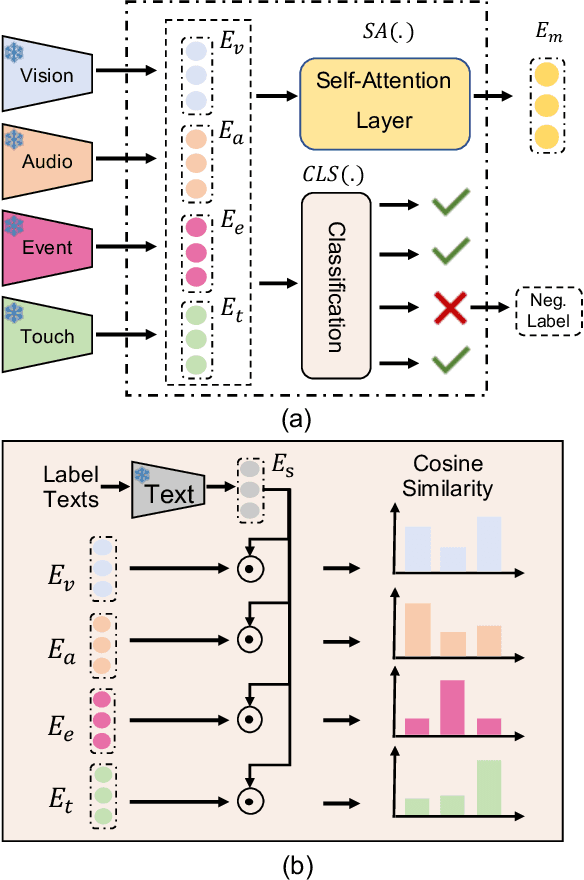
Research on multi-modal learning dominantly aligns the modalities in a unified space at training, and only a single one is taken for prediction at inference. However, for a real machine, e.g., a robot, sensors could be added or removed at any time. Thus, it is crucial to enable the machine to tackle the mismatch and unequal-scale problems of modality combinations between training and inference. In this paper, we tackle these problems from a new perspective: "Modalities Help Modalities". Intuitively, we present OmniBind, a novel two-stage learning framework that can achieve any modality combinations and interaction. It involves teaching data-constrained, a.k.a, student, modalities to be aligned with the well-trained data-abundant, a.k.a, teacher, modalities. This subtly enables the adaptive fusion of any modalities to build a unified representation space for any combinations. Specifically, we propose Cross-modal Alignment Distillation (CAD) to address the unequal-scale problem between student and teacher modalities and effectively align student modalities into the teacher modalities' representation space in stage one. We then propose an Adaptive Fusion (AF) module to fuse any modality combinations and learn a unified representation space in stage two. To address the mismatch problem, we aggregate existing datasets and combine samples from different modalities by the same semantics. This way, we build the first dataset for training and evaluation that consists of teacher (image, text) and student (touch, thermal, event, point cloud, audio) modalities and enables omni-bind for any of them. Extensive experiments on the recognition task show performance gains over prior arts by an average of 4.05 % on the arbitrary modality combination setting. It also achieves state-of-the-art performance for a single modality, e.g., touch, with a 4.34 % gain.
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities
Nov 13, 2023



One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
Detection-Oriented Image-Text Pretraining for Open-Vocabulary Detection
Sep 29, 2023



We present a new open-vocabulary detection approach based on detection-oriented image-text pretraining to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we replace the commonly used classification architecture with the detector architecture, which better serves the region-level recognition needs of detection by enabling the detector heads to learn from noisy image-text pairs. Using only standard contrastive loss and no pseudo-labeling, our approach is a simple yet effective extension of the contrastive learning method to learn emergent object-semantic cues. In addition, we propose a shifted-window learning approach upon window attention to make the backbone representation more robust, translation-invariant, and less biased by the window pattern. On the popular LVIS open-vocabulary detection benchmark, our approach sets a new state of the art of 40.4 mask AP$_r$ using the common ViT-L backbone, significantly outperforming the best existing approach by +6.5 mask AP$_r$ at system level. On the COCO benchmark, we achieve very competitive 40.8 novel AP without pseudo labeling or weak supervision. In addition, we evaluate our approach on the transfer detection setup, where ours outperforms the baseline significantly. Visualization reveals emerging object locality from the pretraining recipes compared to the baseline. Code and models will be publicly released.
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Sep 02, 2023



We present Contrastive Feature Masking Vision Transformer (CFM-ViT) - an image-text pretraining methodology that achieves simultaneous learning of image- and region-level representation for open-vocabulary object detection (OVD). Our approach combines the masked autoencoder (MAE) objective into the contrastive learning objective to improve the representation for localization tasks. Unlike standard MAE, we perform reconstruction in the joint image-text embedding space, rather than the pixel space as is customary with the classical MAE method, which causes the model to better learn region-level semantics. Moreover, we introduce Positional Embedding Dropout (PED) to address scale variation between image-text pretraining and detection finetuning by randomly dropping out the positional embeddings during pretraining. PED improves detection performance and enables the use of a frozen ViT backbone as a region classifier, preventing the forgetting of open-vocabulary knowledge during detection finetuning. On LVIS open-vocabulary detection benchmark, CFM-ViT achieves a state-of-the-art 33.9 AP$r$, surpassing the best approach by 7.6 points and achieves better zero-shot detection transfer. Finally, CFM-ViT acquires strong image-level representation, outperforming the state of the art on 8 out of 12 metrics on zero-shot image-text retrieval benchmarks.
Many-to-Many Spoken Language Translation via Unified Speech and Text Representation Learning with Unit-to-Unit Translation
Aug 03, 2023



In this paper, we propose a method to learn unified representations of multilingual speech and text with a single model, especially focusing on the purpose of speech synthesis. We represent multilingual speech audio with speech units, the quantized representations of speech features encoded from a self-supervised speech model. Therefore, we can focus on their linguistic content by treating the audio as pseudo text and can build a unified representation of speech and text. Then, we propose to train an encoder-decoder structured model with a Unit-to-Unit Translation (UTUT) objective on multilingual data. Specifically, by conditioning the encoder with the source language token and the decoder with the target language token, the model is optimized to translate the spoken language into that of the target language, in a many-to-many language translation setting. Therefore, the model can build the knowledge of how spoken languages are comprehended and how to relate them to different languages. A single pre-trained model with UTUT can be employed for diverse multilingual speech- and text-related tasks, such as Speech-to-Speech Translation (STS), multilingual Text-to-Speech Synthesis (TTS), and Text-to-Speech Translation (TTST). By conducting comprehensive experiments encompassing various languages, we validate the efficacy of the proposed method across diverse multilingual tasks. Moreover, we show UTUT can perform many-to-many language STS, which has not been previously explored in the literature. Samples are available on https://choijeongsoo.github.io/utut.