 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhats in a Video: Factorized Autoregressive Decoding for Online Dense Video Captioning
Nov 22, 2024



Generating automatic dense captions for videos that accurately describe their contents remains a challenging area of research. Most current models require processing the entire video at once. Instead, we propose an efficient, online approach which outputs frequent, detailed and temporally aligned captions, without access to future frames. Our model uses a novel autoregressive factorized decoding architecture, which models the sequence of visual features for each time segment, outputting localized descriptions and efficiently leverages the context from the previous video segments. This allows the model to output frequent, detailed captions to more comprehensively describe the video, according to its actual local content, rather than mimic the training data. Second, we propose an optimization for efficient training and inference, which enables scaling to longer videos. Our approach shows excellent performance compared to both offline and online methods, and uses 20\% less compute. The annotations produced are much more comprehensive and frequent, and can further be utilized in automatic video tagging and in large-scale video data harvesting.
Memory Augmented Language Models through Mixture of Word Experts
Nov 15, 2023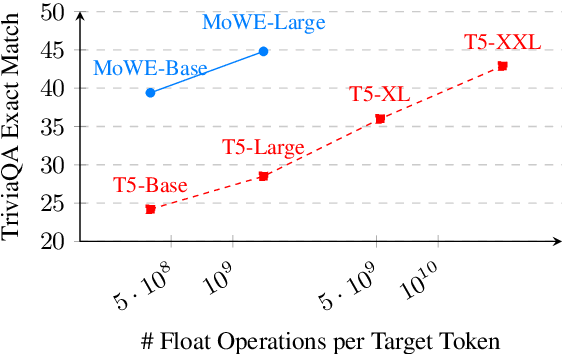
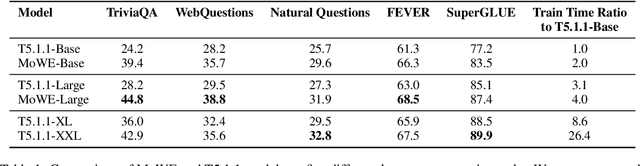
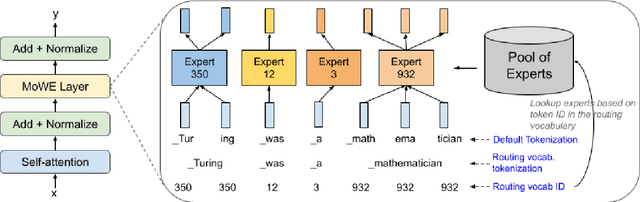
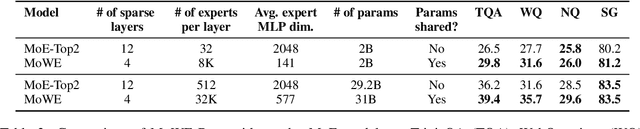
Scaling up the number of parameters of language models has proven to be an effective approach to improve performance. For dense models, increasing model size proportionally increases the model's computation footprint. In this work, we seek to aggressively decouple learning capacity and FLOPs through Mixture-of-Experts (MoE) style models with large knowledge-rich vocabulary based routing functions and experts. Our proposed approach, dubbed Mixture of Word Experts (MoWE), can be seen as a memory augmented model, where a large set of word-specific experts play the role of a sparse memory. We demonstrate that MoWE performs significantly better than the T5 family of models with similar number of FLOPs in a variety of NLP tasks. Additionally, MoWE outperforms regular MoE models on knowledge intensive tasks and has similar performance to more complex memory augmented approaches that often require to invoke custom mechanisms to search the sparse memory.
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities
Nov 13, 2023



One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
TaskLAMA: Probing the Complex Task Understanding of Language Models
Aug 29, 2023Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute to achieving the task, with edges specifying temporal dependencies between them. SCTD is an important component of assistive planning tools, and a challenge for commonsense reasoning systems. We probe how accurately SCTD can be done with the knowledge extracted from Large Language Models (LLMs). We introduce a high-quality human-annotated dataset for this problem and novel metrics to fairly assess performance of LLMs against several baselines. Our experiments reveal that LLMs are able to decompose complex tasks into individual steps effectively, with a relative improvement of 15% to 280% over the best baseline. We also propose a number of approaches to further improve their performance, with a relative improvement of 7% to 37% over the base model. However, we find that LLMs still struggle to predict pairwise temporal dependencies, which reveals a gap in their understanding of complex tasks.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.