 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Tradeoffs in Language Model Decoding with Informational Interpretations
Nov 16, 2023We propose a theoretical framework for formulating language model decoder algorithms with dynamic programming and information theory. With dynamic programming, we lift the design of decoder algorithms from the logit space to the action-state value function space, and show that the decoding algorithms are consequences of optimizing the action-state value functions. Each component in the action-state value function space has an information theoretical interpretation. With the lifting and interpretation, it becomes evident what the decoder algorithm is optimized for, and hence facilitating the arbitration of the tradeoffs in sensibleness, diversity, and attribution.
Memory Augmented Language Models through Mixture of Word Experts
Nov 15, 2023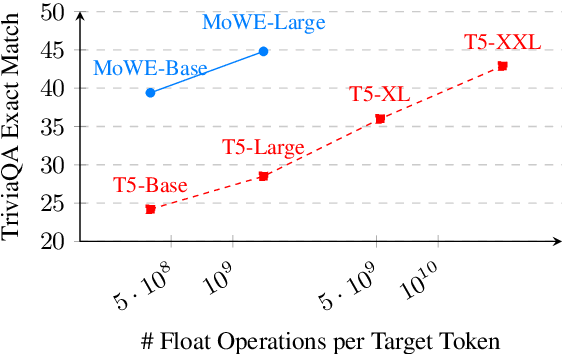
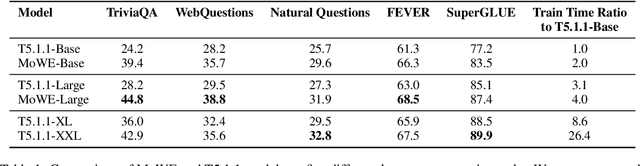
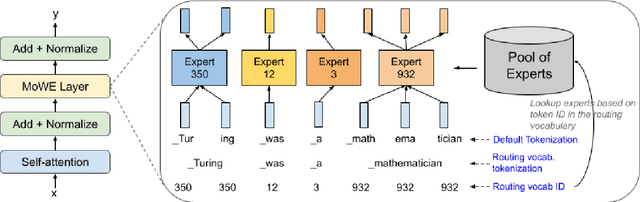
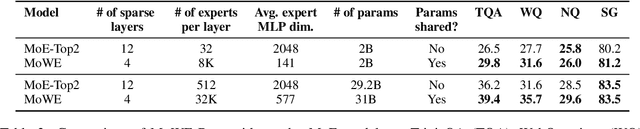
Scaling up the number of parameters of language models has proven to be an effective approach to improve performance. For dense models, increasing model size proportionally increases the model's computation footprint. In this work, we seek to aggressively decouple learning capacity and FLOPs through Mixture-of-Experts (MoE) style models with large knowledge-rich vocabulary based routing functions and experts. Our proposed approach, dubbed Mixture of Word Experts (MoWE), can be seen as a memory augmented model, where a large set of word-specific experts play the role of a sparse memory. We demonstrate that MoWE performs significantly better than the T5 family of models with similar number of FLOPs in a variety of NLP tasks. Additionally, MoWE outperforms regular MoE models on knowledge intensive tasks and has similar performance to more complex memory augmented approaches that often require to invoke custom mechanisms to search the sparse memory.
Hallucination Augmented Recitations for Language Models
Nov 13, 2023Attribution is a key concept in large language models (LLMs) as it enables control over information sources and enhances the factuality of LLMs. While existing approaches utilize open book question answering to improve attribution, factual datasets may reward language models to recall facts that they already know from their pretraining data, not attribution. In contrast, counterfactual open book QA datasets would further improve attribution because the answer could only be grounded in the given text. We propose Hallucination Augmented Recitations (HAR) for creating counterfactual datasets by utilizing hallucination in LLMs to improve attribution. For open book QA as a case study, we demonstrate that models finetuned with our counterfactual datasets improve text grounding, leading to better open book QA performance, with up to an 8.0% increase in F1 score. Our counterfactual dataset leads to significantly better performance than using humanannotated factual datasets, even with 4x smaller datasets and 4x smaller models. We observe that improvements are consistent across various model sizes and datasets, including multi-hop, biomedical, and adversarial QA datasets.
KL-Divergence Guided Temperature Sampling
Jun 02, 2023Temperature sampling is a conventional approach to diversify large language model predictions. As temperature increases, the prediction becomes diverse but also vulnerable to hallucinations -- generating tokens that are sensible but not factual. One common approach to mitigate hallucinations is to provide source/grounding documents and the model is trained to produce predictions that bind to and are attributable to the provided source. It appears that there is a trade-off between diversity and attribution. To mitigate any such trade-off, we propose to relax the constraint of having a fixed temperature over decoding steps, and a mechanism to guide the dynamic temperature according to its relevance to the source through KL-divergence. Our experiments justifies the trade-off, and shows that our sampling algorithm outperforms the conventional top-k and top-p algorithms in conversational question-answering and summarization tasks.
Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models
Feb 14, 2023Despite recent progress, it has been difficult to prevent semantic hallucinations in generative Large Language Models. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information. Given this new added constraint, it is plausible to expect that the overall quality of the output will be affected, for example, in terms of fluency. Can scaling language models help? Here we examine the relationship between fluency and attribution in LLMs prompted with retrieved evidence in knowledge-heavy dialog settings. Our experiments were implemented with a set of auto-metrics that are aligned with human preferences. They were used to evaluate a large set of generations, produced under varying parameters of LLMs and supplied context. We show that larger models tend to do much better in both fluency and attribution, and that (naively) using top-k retrieval versus top-1 retrieval improves attribution but hurts fluency. We next propose a recipe that could allow smaller models to both close the gap with larger models and preserve the benefits of top-k retrieval while avoiding its drawbacks.
Counterfactual Data Augmentation improves Factuality of Abstractive Summarization
May 25, 2022
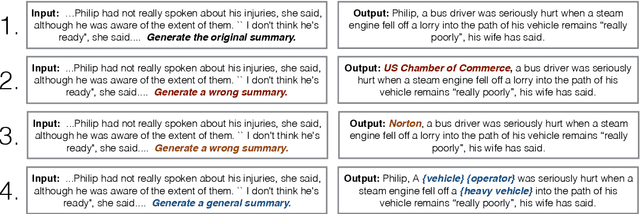
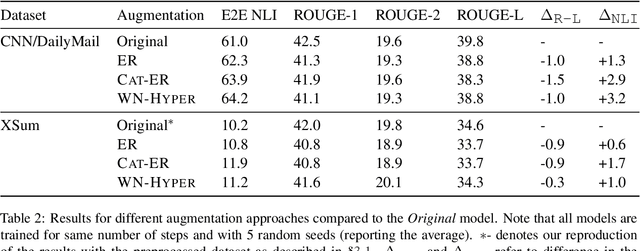

Abstractive summarization systems based on pretrained language models often generate coherent but factually inconsistent sentences. In this paper, we present a counterfactual data augmentation approach where we augment data with perturbed summaries that increase the training data diversity. Specifically, we present three augmentation approaches based on replacing (i) entities from other and the same category and (ii) nouns with their corresponding WordNet hypernyms. We show that augmenting the training data with our approach improves the factual correctness of summaries without significantly affecting the ROUGE score. We show that in two commonly used summarization datasets (CNN/Dailymail and XSum), we improve the factual correctness by about 2.5 points on average
LaMDA: Language Models for Dialog Applications
Feb 10, 2022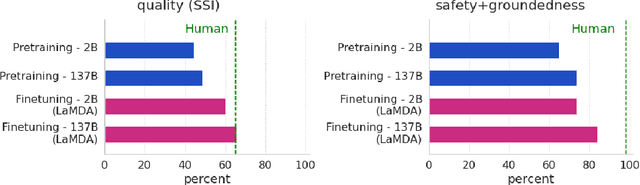
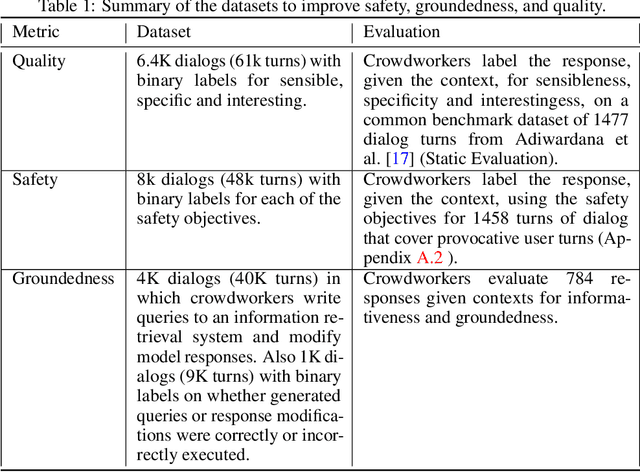
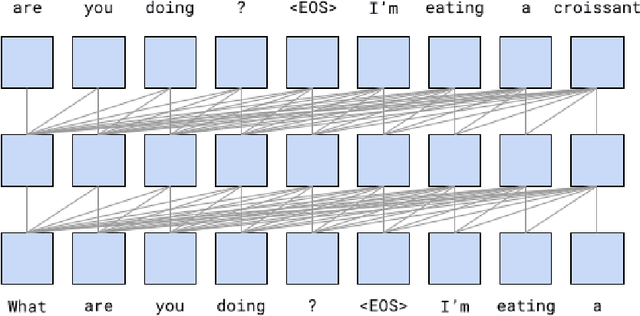

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.