 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering off Course: Reliability Challenges in Steering Language Models
Apr 06, 2025Steering methods for language models (LMs) have gained traction as lightweight alternatives to fine-tuning, enabling targeted modifications to model activations. However, prior studies primarily report results on a few models, leaving critical gaps in understanding the robustness of these methods. In this work, we systematically examine three prominent steering methods -- DoLa, function vectors, and task vectors. In contrast to the original studies, which evaluated a handful of models, we test up to 36 models belonging to 14 families with sizes ranging from 1.5B to 70B parameters. Our experiments reveal substantial variability in the effectiveness of the steering approaches, with a large number of models showing no improvement and at times degradation in steering performance. Our analysis demonstrate fundamental flaws in the assumptions underlying these methods, challenging their reliability as scalable steering solutions.
Scalable Influence and Fact Tracing for Large Language Model Pretraining
Oct 22, 2024Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names.
How Far Can We Extract Diverse Perspectives from Large Language Models? Criteria-Based Diversity Prompting!
Nov 16, 2023



Collecting diverse human data on subjective NLP topics is costly and challenging. As Large Language Models (LLMs) have developed human-like capabilities, there is a recent trend in collaborative efforts between humans and LLMs for generating diverse data, offering potential scalable and efficient solutions. However, the extent of LLMs' capability to generate diverse perspectives on subjective topics remains an unexplored question. In this study, we investigate LLMs' capacity for generating diverse perspectives and rationales on subjective topics, such as social norms and argumentative texts. We formulate this problem as diversity extraction in LLMs and propose a criteria-based prompting technique to ground diverse opinions and measure perspective diversity from the generated criteria words. Our results show that measuring semantic diversity through sentence embeddings and distance metrics is not enough to measure perspective diversity. To see how far we can extract diverse perspectives from LLMs, or called diversity coverage, we employ a step-by-step recall prompting for generating more outputs from the model in an iterative manner. As we apply our prompting method to other tasks (hate speech labeling and story continuation), indeed we find that LLMs are able to generate diverse opinions according to the degree of task subjectivity.
AutoMix: Automatically Mixing Language Models
Oct 19, 2023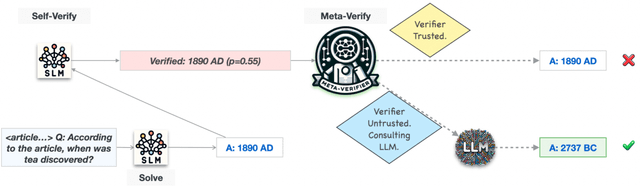
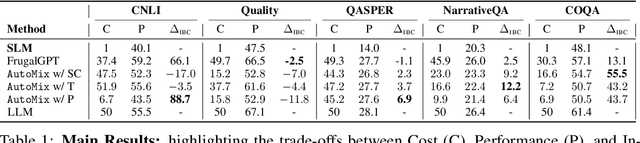
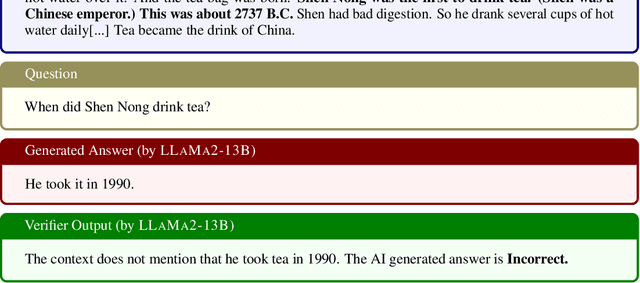

Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
StyLEx: Explaining Styles with Lexicon-Based Human Perception
Oct 14, 2022
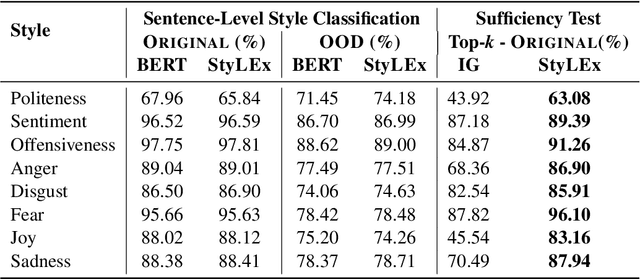
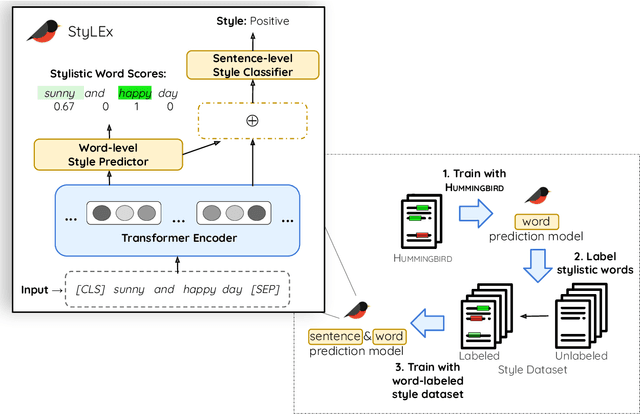
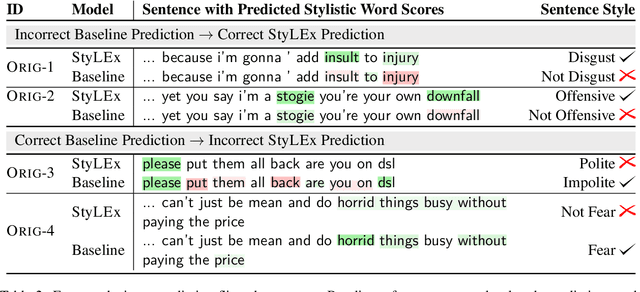
Style plays a significant role in how humans express themselves and communicate with others. Large pre-trained language models produce impressive results on various style classification tasks. However, they often learn spurious domain-specific words to make predictions. This incorrect word importance learned by the model often leads to ambiguous token-level explanations which do not align with human perception of linguistic styles. To tackle this challenge, we introduce StyLEx, a model that learns annotated human perceptions of stylistic lexica and uses these stylistic words as additional information for predicting the style of a sentence. Our experiments show that StyLEx can provide human-like stylistic lexical explanations without sacrificing the performance of sentence-level style prediction on both original and out-of-domain datasets. Explanations from StyLEx show higher sufficiency, and plausibility when compared to human annotations, and are also more understandable by human judges compared to the existing widely-used saliency baseline.
Conditional set generation using Seq2seq models
May 25, 2022
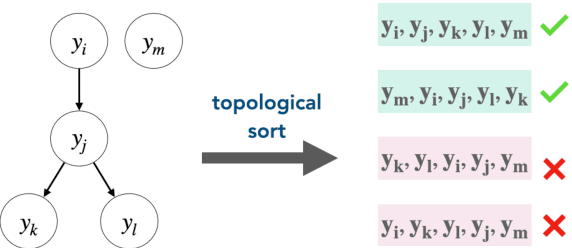
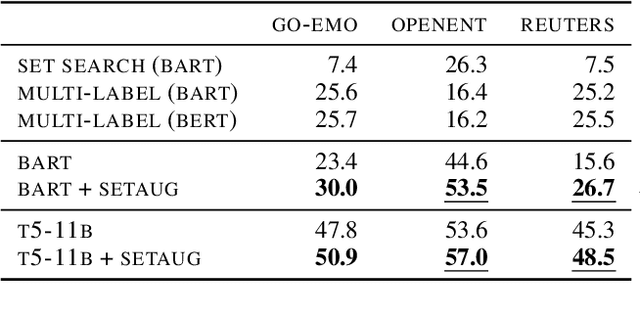
Conditional set generation learns a mapping from an input sequence of tokens to a set. Several NLP tasks, such as entity typing and dialogue emotion tagging, are instances of set generation. Sequence-to-sequence~(Seq2seq) models are a popular choice to model set generation, but they treat a set as a sequence and do not fully leverage its key properties, namely order-invariance and cardinality. We propose a novel algorithm for effectively sampling informative orders over the combinatorial space of label orders. Further, we jointly model the set cardinality and output by adding the set size as the first element and taking advantage of the autoregressive factorization used by Seq2seq models. Our method is a model-independent data augmentation approach that endows any Seq2seq model with the signals of order-invariance and cardinality. Training a Seq2seq model on this new augmented data~(without any additional annotations) gets an average relative improvement of 20% for four benchmarks datasets across models spanning from BART-base, T5-xxl, and GPT-3.
Counterfactual Data Augmentation improves Factuality of Abstractive Summarization
May 25, 2022
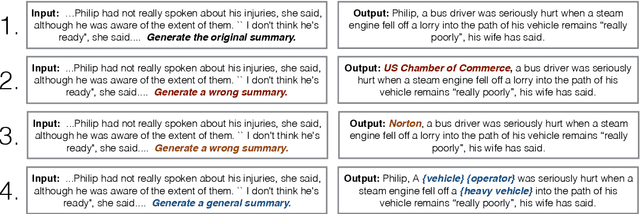
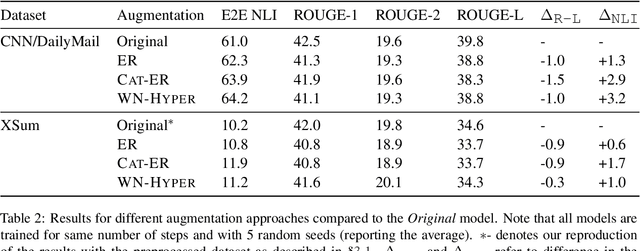

Abstractive summarization systems based on pretrained language models often generate coherent but factually inconsistent sentences. In this paper, we present a counterfactual data augmentation approach where we augment data with perturbed summaries that increase the training data diversity. Specifically, we present three augmentation approaches based on replacing (i) entities from other and the same category and (ii) nouns with their corresponding WordNet hypernyms. We show that augmenting the training data with our approach improves the factual correctness of summaries without significantly affecting the ROUGE score. We show that in two commonly used summarization datasets (CNN/Dailymail and XSum), we improve the factual correctness by about 2.5 points on average
Cross-Domain Reasoning via Template Filling
Oct 31, 2021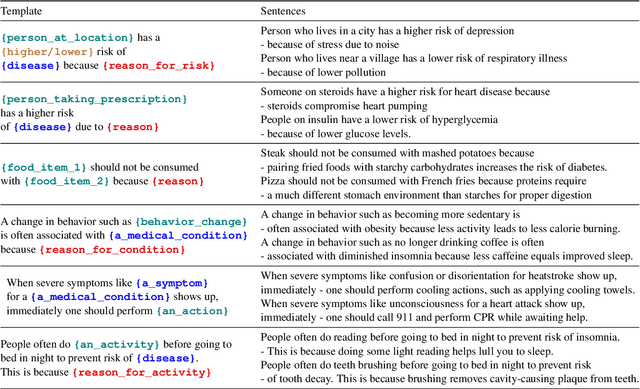
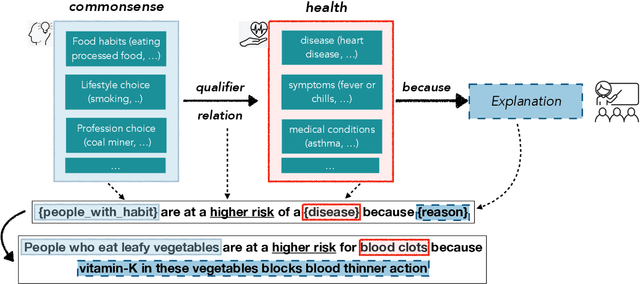

In this paper, we explore the ability of sequence to sequence models to perform cross-domain reasoning. Towards this, we present a prompt-template-filling approach to enable sequence to sequence models to perform cross-domain reasoning. We also present a case-study with commonsense and health and well-being domains, where we study how prompt-template-filling enables pretrained sequence to sequence models across domains. Our experiments across several pretrained encoder-decoder models show that cross-domain reasoning is challenging for current models. We also show an in-depth error analysis and avenues for future research for reasoning across domains
Think about it! Improving defeasible reasoning by first modeling the question scenario
Oct 24, 2021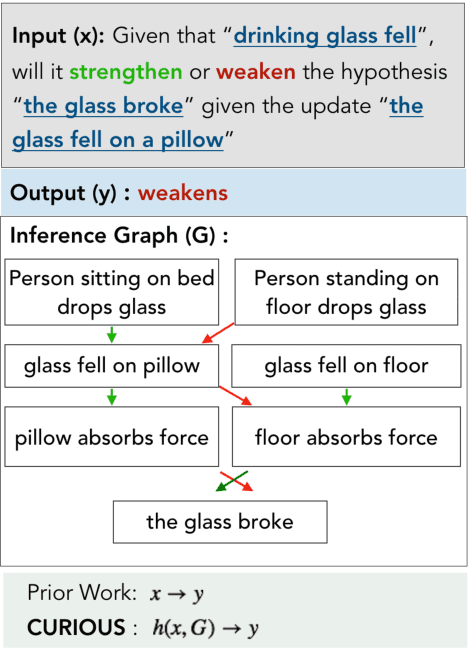
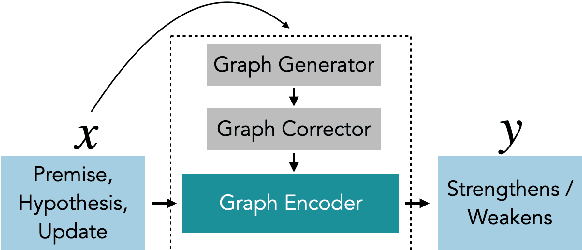
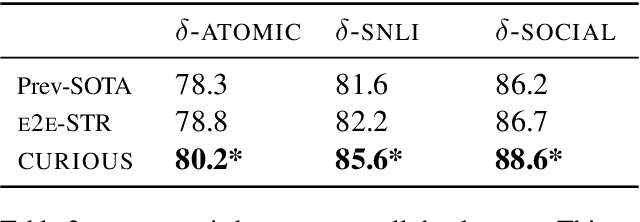
Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. Existing cognitive science literature on defeasible reasoning suggests that a person forms a mental model of the problem scenario before answering questions. Our research goal asks whether neural models can similarly benefit from envisioning the question scenario before answering a defeasible query. Our approach is, given a question, to have a model first create a graph of relevant influences, and then leverage that graph as an additional input when answering the question. Our system, CURIOUS, achieves a new state-of-the-art on three different defeasible reasoning datasets. This result is significant as it illustrates that performance can be improved by guiding a system to "think about" a question and explicitly model the scenario, rather than answering reflexively. Code, data, and pre-trained models are located at https://github.com/madaan/thinkaboutit.
Could you give me a hint? Generating inference graphs for defeasible reasoning
May 29, 2021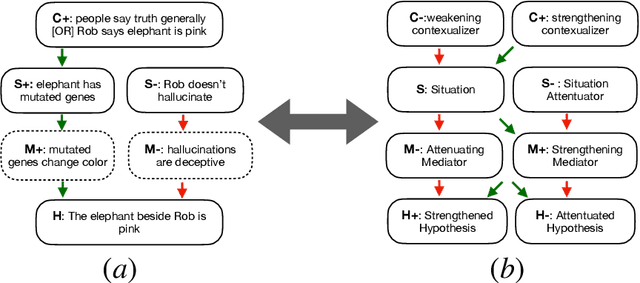



Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. A commonly used method in cognitive science and logic literature is to handcraft argumentation supporting inference graphs. While humans find inference graphs very useful for reasoning, constructing them at scale is difficult. In this paper, we automatically generate such inference graphs through transfer learning from another NLP task that shares the kind of reasoning that inference graphs support. Through automated metrics and human evaluation, we find that our method generates meaningful graphs for the defeasible inference task. Human accuracy on this task improves by 20% by consulting the generated graphs. Our findings open up exciting new research avenues for cases where machine reasoning can help human reasoning. (A dataset of 230,000 influence graphs for each defeasible query is located at: https://tinyurl.com/defeasiblegraphs.)