 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholaWrite: A Dataset of End-to-End Scholarly Writing Process
Feb 05, 2025



Writing is a cognitively demanding task involving continuous decision-making, heavy use of working memory, and frequent switching between multiple activities. Scholarly writing is particularly complex as it requires authors to coordinate many pieces of multiform knowledge. To fully understand writers' cognitive thought process, one should fully decode the end-to-end writing data (from individual ideas to final manuscript) and understand their complex cognitive mechanisms in scholarly writing. We introduce ScholaWrite dataset, the first-of-its-kind keystroke logs of an end-to-end scholarly writing process for complete manuscripts, with thorough annotations of cognitive writing intentions behind each keystroke. Our dataset includes LaTeX-based keystroke data from five preprints with nearly 62K total text changes and annotations across 4 months of paper writing. ScholaWrite shows promising usability and applications (e.g., iterative self-writing) for the future development of AI writing assistants for academic research, which necessitate complex methods beyond LLM prompting. Our experiments clearly demonstrated the importance of collection of end-to-end writing data, rather than the final manuscript, for the development of future writing assistants to support the cognitive thinking process of scientists. Our de-identified dataset, demo, and code repository are available on our project page.
Human-AI Collaborative Taxonomy Construction: A Case Study in Profession-Specific Writing Assistants
Jun 26, 2024Large Language Models (LLMs) have assisted humans in several writing tasks, including text revision and story generation. However, their effectiveness in supporting domain-specific writing, particularly in business contexts, is relatively less explored. Our formative study with industry professionals revealed the limitations in current LLMs' understanding of the nuances in such domain-specific writing. To address this gap, we propose an approach of human-AI collaborative taxonomy development to perform as a guideline for domain-specific writing assistants. This method integrates iterative feedback from domain experts and multiple interactions between these experts and LLMs to refine the taxonomy. Through larger-scale experiments, we aim to validate this methodology and thus improve LLM-powered writing assistance, tailoring it to meet the unique requirements of different stakeholder needs.
LocalTweets to LocalHealth: A Mental Health Surveillance Framework Based on Twitter Data
Feb 21, 2024Prior research on Twitter (now X) data has provided positive evidence of its utility in developing supplementary health surveillance systems. In this study, we present a new framework to surveil public health, focusing on mental health (MH) outcomes. We hypothesize that locally posted tweets are indicative of local MH outcomes and collect tweets posted from 765 neighborhoods (census block groups) in the USA. We pair these tweets from each neighborhood with the corresponding MH outcome reported by the Center for Disease Control (CDC) to create a benchmark dataset, LocalTweets. With LocalTweets, we present the first population-level evaluation task for Twitter-based MH surveillance systems. We then develop an efficient and effective method, LocalHealth, for predicting MH outcomes based on LocalTweets. When used with GPT3.5, LocalHealth achieves the highest F1-score and accuracy of 0.7429 and 79.78\%, respectively, a 59\% improvement in F1-score over the GPT3.5 in zero-shot setting. We also utilize LocalHealth to extrapolate CDC's estimates to proxy unreported neighborhoods, achieving an F1-score of 0.7291. Our work suggests that Twitter data can be effectively leveraged to simulate neighborhood-level MH outcomes.
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
How Far Can We Extract Diverse Perspectives from Large Language Models? Criteria-Based Diversity Prompting!
Nov 16, 2023



Collecting diverse human data on subjective NLP topics is costly and challenging. As Large Language Models (LLMs) have developed human-like capabilities, there is a recent trend in collaborative efforts between humans and LLMs for generating diverse data, offering potential scalable and efficient solutions. However, the extent of LLMs' capability to generate diverse perspectives on subjective topics remains an unexplored question. In this study, we investigate LLMs' capacity for generating diverse perspectives and rationales on subjective topics, such as social norms and argumentative texts. We formulate this problem as diversity extraction in LLMs and propose a criteria-based prompting technique to ground diverse opinions and measure perspective diversity from the generated criteria words. Our results show that measuring semantic diversity through sentence embeddings and distance metrics is not enough to measure perspective diversity. To see how far we can extract diverse perspectives from LLMs, or called diversity coverage, we employ a step-by-step recall prompting for generating more outputs from the model in an iterative manner. As we apply our prompting method to other tasks (hate speech labeling and story continuation), indeed we find that LLMs are able to generate diverse opinions according to the degree of task subjectivity.
Benchmarking Cognitive Biases in Large Language Models as Evaluators
Sep 29, 2023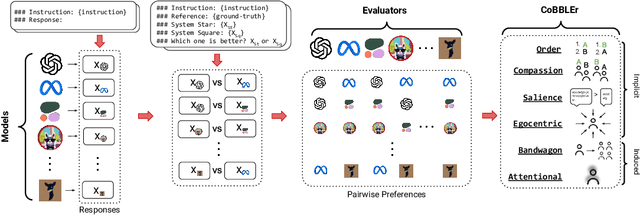



Large Language Models (LLMs) have recently been shown to be effective as automatic evaluators with simple prompting and in-context learning. In this work, we assemble 15 LLMs of four different size ranges and evaluate their output responses by preference ranking from the other LLMs as evaluators, such as System Star is better than System Square. We then evaluate the quality of ranking outputs introducing the Cognitive Bias Benchmark for LLMs as Evaluators (CoBBLEr), a benchmark to measure six different cognitive biases in LLM evaluation outputs, such as the Egocentric bias where a model prefers to rank its own outputs highly in evaluation. We find that LLMs are biased text quality evaluators, exhibiting strong indications on our bias benchmark (average of 40% of comparisons across all models) within each of their evaluations that question their robustness as evaluators. Furthermore, we examine the correlation between human and machine preferences and calculate the average Rank-Biased Overlap (RBO) score to be 49.6%, indicating that machine preferences are misaligned with humans. According to our findings, LLMs may still be unable to be utilized for automatic annotation aligned with human preferences. Our project page is at: https://minnesotanlp.github.io/cobbler.
Vision Meets Definitions: Unsupervised Visual Word Sense Disambiguation Incorporating Gloss Information
May 02, 2023



Visual Word Sense Disambiguation (VWSD) is a task to find the image that most accurately depicts the correct sense of the target word for the given context. Previously, image-text matching models often suffered from recognizing polysemous words. This paper introduces an unsupervised VWSD approach that uses gloss information of an external lexical knowledge-base, especially the sense definitions. Specifically, we suggest employing Bayesian inference to incorporate the sense definitions when sense information of the answer is not provided. In addition, to ameliorate the out-of-dictionary (OOD) issue, we propose a context-aware definition generation with GPT-3. Experimental results show that the VWSD performance significantly increased with our Bayesian inference-based approach. In addition, our context-aware definition generation achieved prominent performance improvement in OOD examples exhibiting better performance than the existing definition generation method. We will publish source codes as soon as possible.