 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDischargeSim: A Simulation Benchmark for Educational Doctor-Patient Communication at Discharge
Sep 10, 2025Discharge communication is a critical yet underexplored component of patient care, where the goal shifts from diagnosis to education. While recent large language model (LLM) benchmarks emphasize in-visit diagnostic reasoning, they fail to evaluate models' ability to support patients after the visit. We introduce DischargeSim, a novel benchmark that evaluates LLMs on their ability to act as personalized discharge educators. DischargeSim simulates post-visit, multi-turn conversations between LLM-driven DoctorAgents and PatientAgents with diverse psychosocial profiles (e.g., health literacy, education, emotion). Interactions are structured across six clinically grounded discharge topics and assessed along three axes: (1) dialogue quality via automatic and LLM-as-judge evaluation, (2) personalized document generation including free-text summaries and structured AHRQ checklists, and (3) patient comprehension through a downstream multiple-choice exam. Experiments across 18 LLMs reveal significant gaps in discharge education capability, with performance varying widely across patient profiles. Notably, model size does not always yield better education outcomes, highlighting trade-offs in strategy use and content prioritization. DischargeSim offers a first step toward benchmarking LLMs in post-visit clinical education and promoting equitable, personalized patient support.
Enhancing LLMs for Identifying and Prioritizing Important Medical Jargons from Electronic Health Record Notes Utilizing Data Augmentation
Feb 25, 2025OpenNotes enables patients to access EHR notes, but medical jargon can hinder comprehension. To improve understanding, we evaluated closed- and open-source LLMs for extracting and prioritizing key medical terms using prompting, fine-tuning, and data augmentation. We assessed LLMs on 106 expert-annotated EHR notes, experimenting with (i) general vs. structured prompts, (ii) zero-shot vs. few-shot prompting, (iii) fine-tuning, and (iv) data augmentation. To enhance open-source models in low-resource settings, we used ChatGPT for data augmentation and applied ranking techniques. We incrementally increased the augmented dataset size (10 to 10,000) and conducted 5-fold cross-validation, reporting F1 score and Mean Reciprocal Rank (MRR). Our result show that fine-tuning and data augmentation improved performance over other strategies. GPT-4 Turbo achieved the highest F1 (0.433), while Mistral7B with data augmentation had the highest MRR (0.746). Open-source models, when fine-tuned or augmented, outperformed closed-source models. Notably, the best F1 and MRR scores did not always align. Few-shot prompting outperformed zero-shot in vanilla models, and structured prompts yielded different preferences across models. Fine-tuning improved zero-shot performance but sometimes degraded few-shot performance. Data augmentation performed comparably or better than other methods. Our evaluation highlights the effectiveness of prompting, fine-tuning, and data augmentation in improving model performance for medical jargon extraction in low-resource scenarios.
Blocks Architecture (BloArk): Efficient, Cost-Effective, and Incremental Dataset Architecture for Wikipedia Revision History
Oct 06, 2024
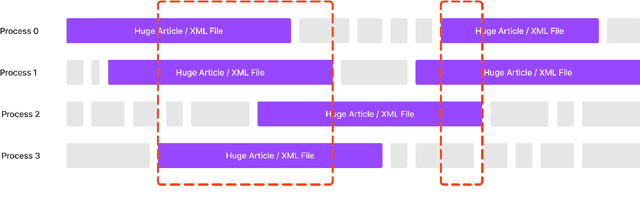
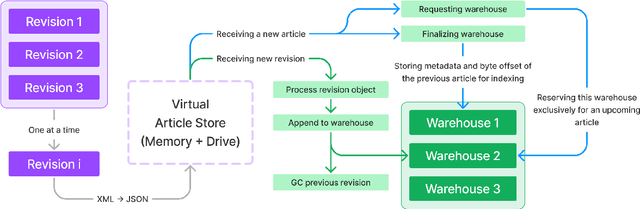
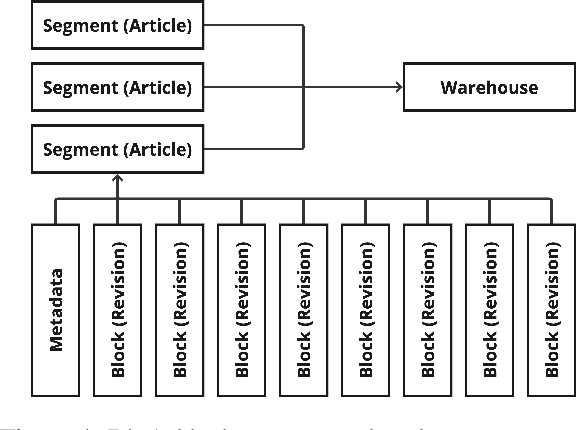
Wikipedia (Wiki) is one of the most widely used and publicly available resources for natural language processing (NLP) applications. Wikipedia Revision History (WikiRevHist) shows the order in which edits were made to any Wiki page since its first modification. While the most up-to-date Wiki has been widely used as a training source, WikiRevHist can also be valuable resources for NLP applications. However, there are insufficient tools available to process WikiRevHist without having substantial computing resources, making additional customization, and spending extra time adapting others' works. Therefore, we report Blocks Architecture (BloArk), an efficiency-focused data processing architecture that reduces running time, computing resource requirements, and repeated works in processing WikiRevHist dataset. BloArk consists of three parts in its infrastructure: blocks, segments, and warehouses. On top of that, we build the core data processing pipeline: builder and modifier. The BloArk builder transforms the original WikiRevHist dataset from XML syntax into JSON Lines (JSONL) format for improving the concurrent and storage efficiency. The BloArk modifier takes previously-built warehouses to operate incremental modifications for improving the utilization of existing databases and reducing the cost of reusing others' works. In the end, BloArk can scale up easily in both processing Wikipedia Revision History and incrementally modifying existing dataset for downstream NLP use cases. The source code, documentations, and example usages are publicly available online and open-sourced under GPL-2.0 license.
Large Language Model-based Role-Playing for Personalized Medical Jargon Extraction
Aug 10, 2024Previous studies reveal that Electronic Health Records (EHR), which have been widely adopted in the U.S. to allow patients to access their personal medical information, do not have high readability to patients due to the prevalence of medical jargon. Tailoring medical notes to individual comprehension by identifying jargon that is difficult for each person will enhance the utility of generative models. We present the first quantitative analysis to measure the impact of role-playing in LLM in medical term extraction. By comparing the results of Mechanical Turk workers over 20 sentences, our study demonstrates that LLM role-playing improves F1 scores in 95% of cases across 14 different socio-demographic backgrounds. Furthermore, applying role-playing with in-context learning outperformed the previous state-of-the-art models. Our research showed that ChatGPT can improve traditional medical term extraction systems by utilizing role-play to deliver personalized patient education, a potential that previous models had not achieved.
UMass-BioNLP at MEDIQA-M3G 2024: DermPrompt -- A Systematic Exploration of Prompt Engineering with GPT-4V for Dermatological Diagnosis
Apr 27, 2024



This paper presents our team's participation in the MEDIQA-ClinicalNLP2024 shared task B. We present a novel approach to diagnosing clinical dermatology cases by integrating large multimodal models, specifically leveraging the capabilities of GPT-4V under a retriever and a re-ranker framework. Our investigation reveals that GPT-4V, when used as a retrieval agent, can accurately retrieve the correct skin condition 85% of the time using dermatological images and brief patient histories. Additionally, we empirically show that Naive Chain-of-Thought (CoT) works well for retrieval while Medical Guidelines Grounded CoT is required for accurate dermatological diagnosis. Further, we introduce a Multi-Agent Conversation (MAC) framework and show its superior performance and potential over the best CoT strategy. The experiments suggest that using naive CoT for retrieval and multi-agent conversation for critique-based diagnosis, GPT-4V can lead to an early and accurate diagnosis of dermatological conditions. The implications of this work extend to improving diagnostic workflows, supporting dermatological education, and enhancing patient care by providing a scalable, accessible, and accurate diagnostic tool.
ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
Mar 09, 2024



The advancement of natural language processing (NLP) systems in healthcare hinges on language model ability to interpret the intricate information contained within clinical notes. This process often requires integrating information from various time points in a patient's medical history. However, most earlier clinical language models were pretrained with a context length limited to roughly one clinical document. In this study, We introduce ClinicalMamba, a specialized version of the Mamba language model, pretrained on a vast corpus of longitudinal clinical notes to address the unique linguistic characteristics and information processing needs of the medical domain. ClinicalMamba, with 130 million and 2.8 billion parameters, demonstrates a superior performance in modeling clinical language across extended text lengths compared to Mamba and clinical Llama. With few-shot learning, ClinicalMamba achieves notable benchmarks in speed and accuracy, outperforming existing clinical language models and general domain large models like GPT-4 in longitudinal clinical notes information extraction tasks.
Is it safe to cross? Interpretable Risk Assessment with GPT-4V for Safety-Aware Street Crossing
Feb 09, 2024



Safely navigating street intersections is a complex challenge for blind and low-vision individuals, as it requires a nuanced understanding of the surrounding context - a task heavily reliant on visual cues. Traditional methods for assisting in this decision-making process often fall short, lacking the ability to provide a comprehensive scene analysis and safety level. This paper introduces an innovative approach that leverages large multimodal models (LMMs) to interpret complex street crossing scenes, offering a potential advancement over conventional traffic signal recognition techniques. By generating a safety score and scene description in natural language, our method supports safe decision-making for the blind and low-vision individuals. We collected crosswalk intersection data that contains multiview egocentric images captured by a quadruped robot and annotated the images with corresponding safety scores based on our predefined safety score categorization. Grounded on the visual knowledge, extracted from images, and text prompt, we evaluate a large multimodal model for safety score prediction and scene description. Our findings highlight the reasoning and safety score prediction capabilities of a LMM, activated by various prompts, as a pathway to developing a trustworthy system, crucial for applications requiring reliable decision-making support.
README: Bridging Medical Jargon and Lay Understanding for Patient Education through Data-Centric NLP
Dec 24, 2023The advancement in healthcare has shifted focus toward patient-centric approaches, particularly in self-care and patient education, facilitated by access to Electronic Health Records (EHR). However, medical jargon in EHRs poses significant challenges in patient comprehension. To address this, we introduce a new task of automatically generating lay definitions, aiming to simplify complex medical terms into patient-friendly lay language. We first created the README dataset, an extensive collection of over 20,000 unique medical terms and 300,000 mentions, each offering context-aware lay definitions manually annotated by domain experts. We have also engineered a data-centric Human-AI pipeline that synergizes data filtering, augmentation, and selection to improve data quality. We then used README as the training data for models and leveraged a Retrieval-Augmented Generation (RAG) method to reduce hallucinations and improve the quality of model outputs. Our extensive automatic and human evaluations demonstrate that open-source mobile-friendly models, when fine-tuned with high-quality data, are capable of matching or even surpassing the performance of state-of-the-art closed-source large language models like ChatGPT. This research represents a significant stride in closing the knowledge gap in patient education and advancing patient-centric healthcare solutions
CR-COPEC: Causal Rationale of Corporate Performance Changes to Learn from Financial Reports
Oct 24, 2023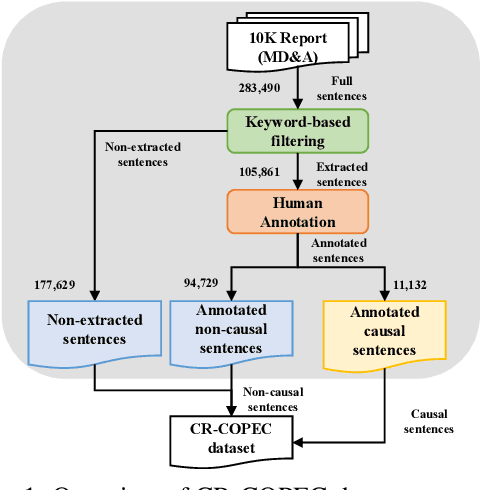
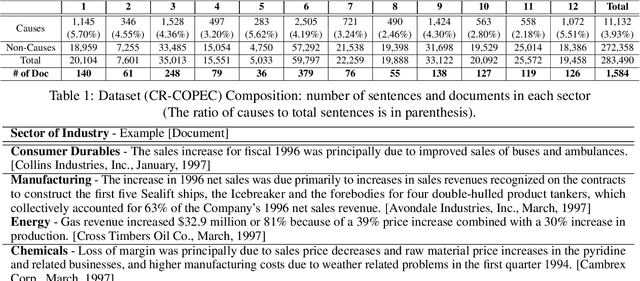
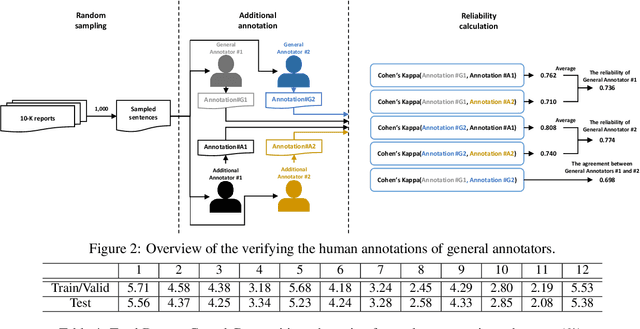
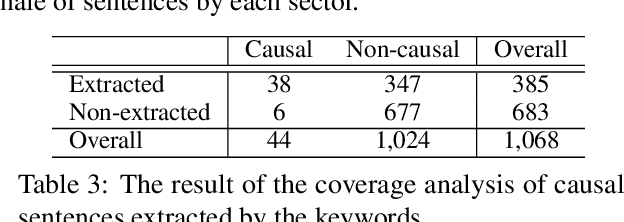
In this paper, we introduce CR-COPEC called Causal Rationale of Corporate Performance Changes from financial reports. This is a comprehensive large-scale domain-adaptation causal sentence dataset to detect financial performance changes of corporate. CR-COPEC contributes to two major achievements. First, it detects causal rationale from 10-K annual reports of the U.S. companies, which contain experts' causal analysis following accounting standards in a formal manner. This dataset can be widely used by both individual investors and analysts as material information resources for investing and decision making without tremendous effort to read through all the documents. Second, it carefully considers different characteristics which affect the financial performance of companies in twelve industries. As a result, CR-COPEC can distinguish causal sentences in various industries by taking unique narratives in each industry into consideration. We also provide an extensive analysis of how well CR-COPEC dataset is constructed and suited for classifying target sentences as causal ones with respect to industry characteristics. Our dataset and experimental codes are publicly available.
ODD: A Benchmark Dataset for the NLP-based Opioid Related Aberrant Behavior Detection
Jul 24, 2023



Opioid related aberrant behaviors (ORAB) present novel risk factors for opioid overdose. Previously, ORAB have been mainly assessed by survey results and by monitoring drug administrations. Such methods however, cannot scale up and do not cover the entire spectrum of aberrant behaviors. On the other hand, ORAB are widely documented in electronic health record notes. This paper introduces a novel biomedical natural language processing benchmark dataset named ODD, for ORAB Detection Dataset. ODD is an expert-annotated dataset comprising of more than 750 publicly available EHR notes. ODD has been designed to identify ORAB from patients' EHR notes and classify them into nine categories; 1) Confirmed Aberrant Behavior, 2) Suggested Aberrant Behavior, 3) Opioids, 4) Indication, 5) Diagnosed opioid dependency, 6) Benzodiapines, 7) Medication Changes, 8) Central Nervous System-related, and 9) Social Determinants of Health. We explored two state-of-the-art natural language processing (NLP) models (finetuning pretrained language models and prompt-tuning approaches) to identify ORAB. Experimental results show that the prompt-tuning models outperformed the finetuning models in most cateogories and the gains were especially higher among uncommon categories (Suggested aberrant behavior, Diagnosed opioid dependency and Medication change). Although the best model achieved the highest 83.92% on area under precision recall curve, uncommon classes (Suggested Aberrant Behavior, Diagnosed Opioid Dependence, and Medication Change) still have a large room for performance improvement.