 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Collapse: LLMs Flatten Long-Form Public Debate
Jun 01, 2026As LLMs are increasingly used to draft public-facing arguments, they may flatten public debate by repeatedly introducing the same polished, plausible arguments. We study argument collapse, the tendency of essays generated by different LLMs to converge to a smaller set of main arguments, sub-arguments, and paragraph-level structures. We compare 1,039 human responses from 195 New York Times (NYT) debates, 448 human responses from 61 longer-form Boston Review (BR) forums, and 23,384 LLM-generated essays. In the NYT corpus, 65.3% of human main arguments are unique within a debate, compared to 3.4% of LLM main arguments. Asking LLMs to generate diverse answers adds variation, but a typical model recovers only about half of the distinct human main arguments, with much of the added variation falling outside the observed human argument space. Collapse also appears in sub-arguments, where among essays with the same main argument, 41.0% of human sub-arguments are unique versus 9.1% from LLM responses. Qualitatively, LLMs often reuse generalized and hedged sub-arguments, while humans prefer more concrete and topic-specific ones. Structure-wise, LLM-generated essays tend to follow a more fixed arc, often opening with a direct claim and moving quickly toward proposals. The same patterns hold in longer BR essays, suggesting that argument collapse extends beyond short-form responses.
BLEUBERI: BLEU is a surprisingly effective reward for instruction following
May 16, 2025



Reward models are central to aligning LLMs with human preferences, but they are costly to train, requiring large-scale human-labeled preference data and powerful pretrained LLM backbones. Meanwhile, the increasing availability of high-quality synthetic instruction-following datasets raises the question: can simpler, reference-based metrics serve as viable alternatives to reward models during RL-based alignment? In this paper, we show first that BLEU, a basic string-matching metric, surprisingly matches strong reward models in agreement with human preferences on general instruction-following datasets. Based on this insight, we develop BLEUBERI, a method that first identifies challenging instructions and then applies Group Relative Policy Optimization (GRPO) using BLEU directly as the reward function. We demonstrate that BLEUBERI-trained models are competitive with models trained via reward model-guided RL across four challenging instruction-following benchmarks and three different base language models. A human evaluation further supports that the quality of BLEUBERI model outputs is on par with those from reward model-aligned models. Moreover, BLEUBERI models generate outputs that are more factually grounded than competing methods. Overall, we show that given access to high-quality reference outputs (easily obtained via existing instruction-following datasets or synthetic data generation), string matching-based metrics are cheap yet effective proxies for reward models during alignment. We release our code and data at https://github.com/lilakk/BLEUBERI.
One ruler to measure them all: Benchmarking multilingual long-context language models
Mar 03, 2025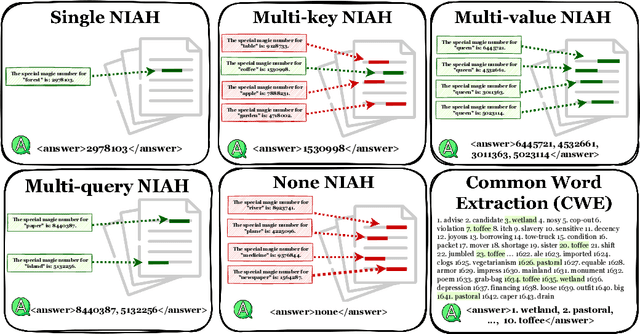
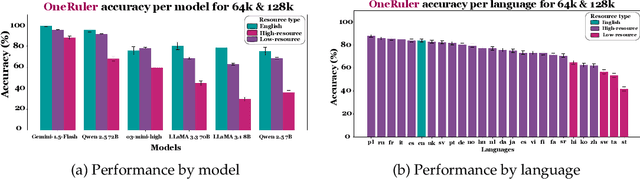
We present ONERULER, a multilingual benchmark designed to evaluate long-context language models across 26 languages. ONERULER adapts the English-only RULER benchmark (Hsieh et al., 2024) by including seven synthetic tasks that test both retrieval and aggregation, including new variations of the "needle-in-a-haystack" task that allow for the possibility of a nonexistent needle. We create ONERULER through a two-step process, first writing English instructions for each task and then collaborating with native speakers to translate them into 25 additional languages. Experiments with both open-weight and closed LLMs reveal a widening performance gap between low- and high-resource languages as context length increases from 8K to 128K tokens. Surprisingly, English is not the top-performing language on long-context tasks (ranked 6th out of 26), with Polish emerging as the top language. Our experiments also show that many LLMs (particularly OpenAI's o3-mini-high) incorrectly predict the absence of an answer, even in high-resource languages. Finally, in cross-lingual scenarios where instructions and context appear in different languages, performance can fluctuate by up to 20% depending on the instruction language. We hope the release of ONERULER will facilitate future research into improving multilingual and cross-lingual long-context training pipelines.
VERISCORE: Evaluating the factuality of verifiable claims in long-form text generation
Jun 27, 2024Existing metrics for evaluating the factuality of long-form text, such as FACTSCORE (Min et al., 2023) and SAFE (Wei et al., 2024), decompose an input text into "atomic claims" and verify each against a knowledge base like Wikipedia. These metrics are not suitable for most generation tasks because they assume that every claim is verifiable (i.e., can plausibly be proven true or false). We address this issue with VERISCORE, a metric for diverse long-form generation tasks that contain both verifiable and unverifiable content. VERISCORE can be effectively implemented with either closed or fine-tuned open-weight language models, and human evaluation confirms that VERISCORE's extracted claims are more sensible than those from competing methods across eight different long-form tasks. We use VERISCORE to evaluate generations from 16 different models across multiple long-form tasks and find that while GPT-4o is the best-performing model overall, open-weight models such as Mixtral-8x22 are closing the gap. We show that an LM's VERISCORE on one task (e.g., biography generation) does not necessarily correlate to its VERISCORE on a different task (e.g., long-form QA), highlighting the need for expanding factuality evaluation across tasks with varying fact density.
FABLES: Evaluating faithfulness and content selection in book-length summarization
Apr 01, 2024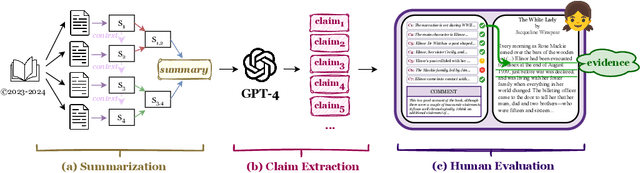
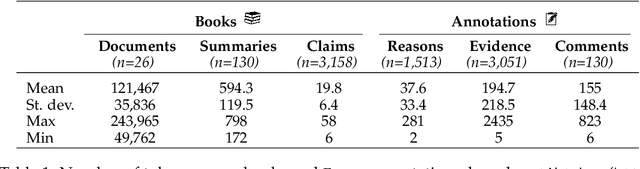


While long-context large language models (LLMs) can technically summarize book-length documents (>100K tokens), the length and complexity of the documents have so far prohibited evaluations of input-dependent aspects like faithfulness. In this paper, we conduct the first large-scale human evaluation of faithfulness and content selection on LLM-generated summaries of fictional books. Our study mitigates the issue of data contamination by focusing on summaries of books published in 2023 or 2024, and we hire annotators who have fully read each book prior to the annotation task to minimize cost and cognitive burden. We collect FABLES, a dataset of annotations on 3,158 claims made in LLM-generated summaries of 26 books, at a cost of $5.2K USD, which allows us to rank LLM summarizers based on faithfulness: Claude-3-Opus significantly outperforms all closed-source LLMs, while the open-source Mixtral is on par with GPT-3.5-Turbo. An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate. While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims. Our experiments suggest that detecting unfaithful claims is an important future direction not only for summarization evaluation but also as a testbed for long-context understanding. Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
Is it safe to cross? Interpretable Risk Assessment with GPT-4V for Safety-Aware Street Crossing
Feb 09, 2024



Safely navigating street intersections is a complex challenge for blind and low-vision individuals, as it requires a nuanced understanding of the surrounding context - a task heavily reliant on visual cues. Traditional methods for assisting in this decision-making process often fall short, lacking the ability to provide a comprehensive scene analysis and safety level. This paper introduces an innovative approach that leverages large multimodal models (LMMs) to interpret complex street crossing scenes, offering a potential advancement over conventional traffic signal recognition techniques. By generating a safety score and scene description in natural language, our method supports safe decision-making for the blind and low-vision individuals. We collected crosswalk intersection data that contains multiview egocentric images captured by a quadruped robot and annotated the images with corresponding safety scores based on our predefined safety score categorization. Grounded on the visual knowledge, extracted from images, and text prompt, we evaluate a large multimodal model for safety score prediction and scene description. Our findings highlight the reasoning and safety score prediction capabilities of a LMM, activated by various prompts, as a pathway to developing a trustworthy system, crucial for applications requiring reliable decision-making support.
infoVerse: A Universal Framework for Dataset Characterization with Multidimensional Meta-information
Jun 12, 2023



The success of NLP systems often relies on the availability of large, high-quality datasets. However, not all samples in these datasets are equally valuable for learning, as some may be redundant or noisy. Several methods for characterizing datasets based on model-driven meta-information (e.g., model's confidence) have been developed, but the relationship and complementary effects of these methods have received less attention. In this paper, we introduce infoVerse, a universal framework for dataset characterization, which provides a new feature space that effectively captures multidimensional characteristics of datasets by incorporating various model-driven meta-information. infoVerse reveals distinctive regions of the dataset that are not apparent in the original semantic space, hence guiding users (or models) in identifying which samples to focus on for exploration, assessment, or annotation. Additionally, we propose a novel sampling method on infoVerse to select a set of data points that maximizes informativeness. In three real-world applications (data pruning, active learning, and data annotation), the samples chosen on infoVerse space consistently outperform strong baselines in all applications. Our code and demo are publicly available.
LINDA: Unsupervised Learning to Interpolate in Natural Language Processing
Dec 28, 2021
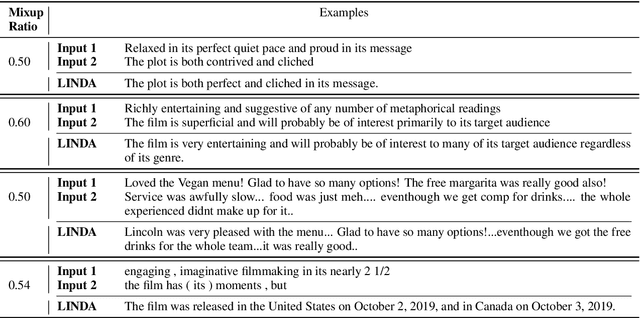
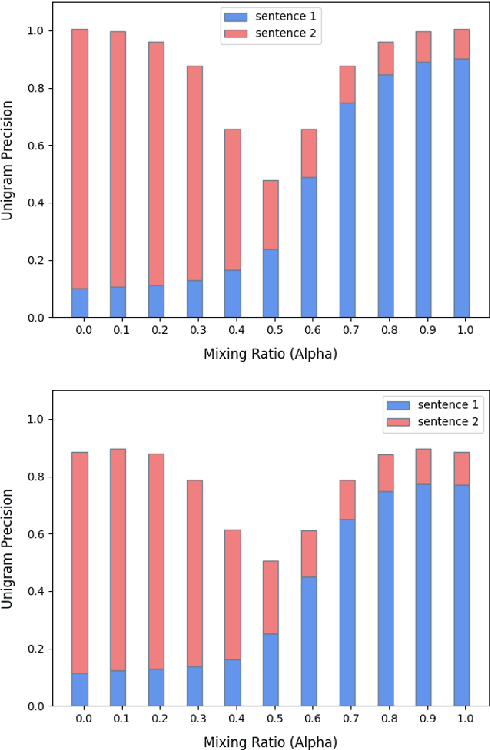
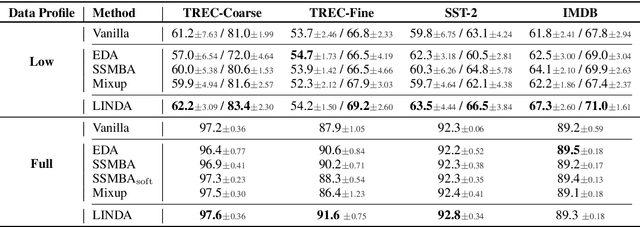
Despite the success of mixup in data augmentation, its applicability to natural language processing (NLP) tasks has been limited due to the discrete and variable-length nature of natural languages. Recent studies have thus relied on domain-specific heuristics and manually crafted resources, such as dictionaries, in order to apply mixup in NLP. In this paper, we instead propose an unsupervised learning approach to text interpolation for the purpose of data augmentation, to which we refer as "Learning to INterpolate for Data Augmentation" (LINDA), that does not require any heuristics nor manually crafted resources but learns to interpolate between any pair of natural language sentences over a natural language manifold. After empirically demonstrating the LINDA's interpolation capability, we show that LINDA indeed allows us to seamlessly apply mixup in NLP and leads to better generalization in text classification both in-domain and out-of-domain.
Deep Active Learning for Sequence Labeling Based on Diversity and Uncertainty in Gradient
Nov 27, 2020
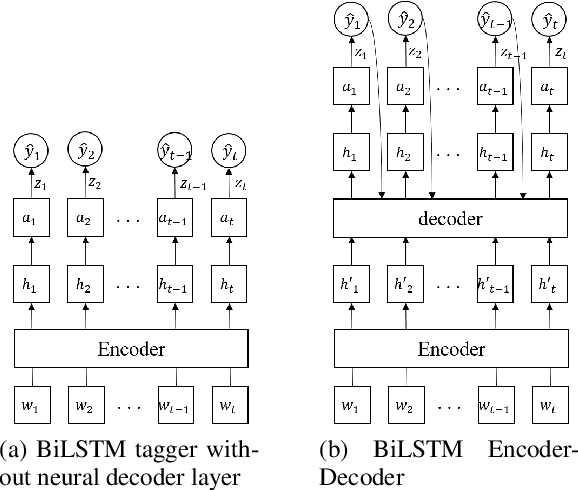

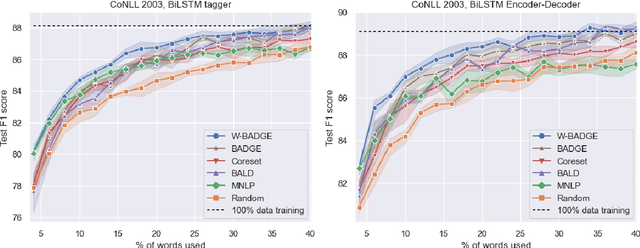
Recently, several studies have investigated active learning (AL) for natural language processing tasks to alleviate data dependency. However, for query selection, most of these studies mainly rely on uncertainty-based sampling, which generally does not exploit the structural information of the unlabeled data. This leads to a sampling bias in the batch active learning setting, which selects several samples at once. In this work, we demonstrate that the amount of labeled training data can be reduced using active learning when it incorporates both uncertainty and diversity in the sequence labeling task. We examined the effects of our sequence-based approach by selecting weighted diverse in the gradient embedding approach across multiple tasks, datasets, models, and consistently outperform classic uncertainty-based sampling and diversity-based sampling.