 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINDA: Unsupervised Learning to Interpolate in Natural Language Processing
Dec 28, 2021
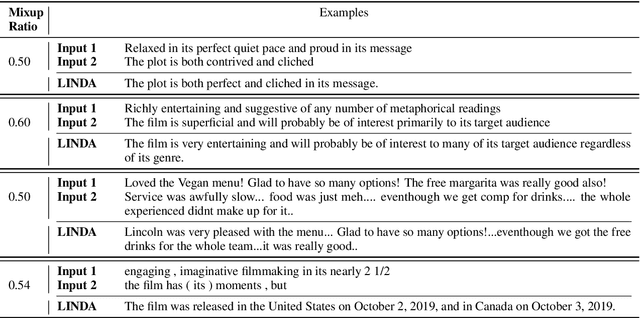
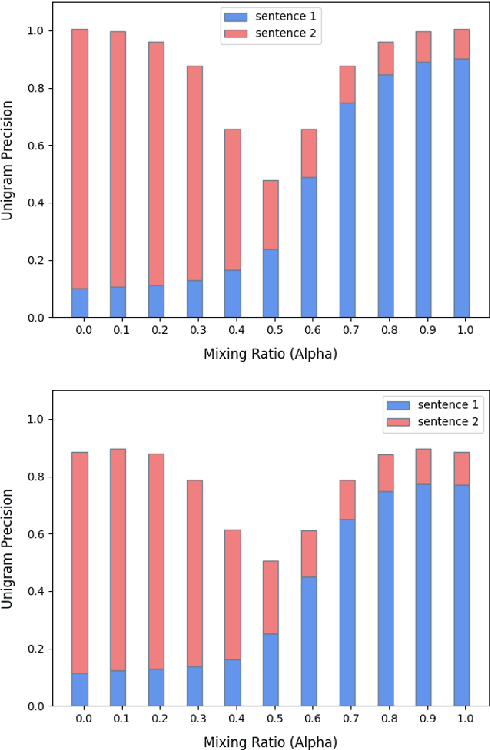
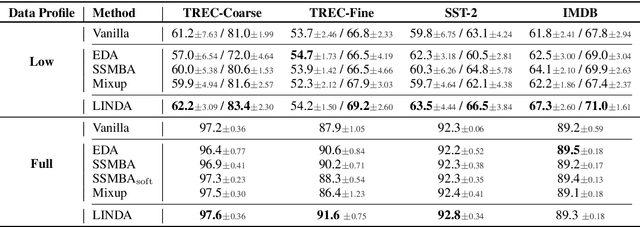
Despite the success of mixup in data augmentation, its applicability to natural language processing (NLP) tasks has been limited due to the discrete and variable-length nature of natural languages. Recent studies have thus relied on domain-specific heuristics and manually crafted resources, such as dictionaries, in order to apply mixup in NLP. In this paper, we instead propose an unsupervised learning approach to text interpolation for the purpose of data augmentation, to which we refer as "Learning to INterpolate for Data Augmentation" (LINDA), that does not require any heuristics nor manually crafted resources but learns to interpolate between any pair of natural language sentences over a natural language manifold. After empirically demonstrating the LINDA's interpolation capability, we show that LINDA indeed allows us to seamlessly apply mixup in NLP and leads to better generalization in text classification both in-domain and out-of-domain.
Learning Dynamic BERT via Trainable Gate Variables and a Bi-modal Regularizer
Feb 19, 2021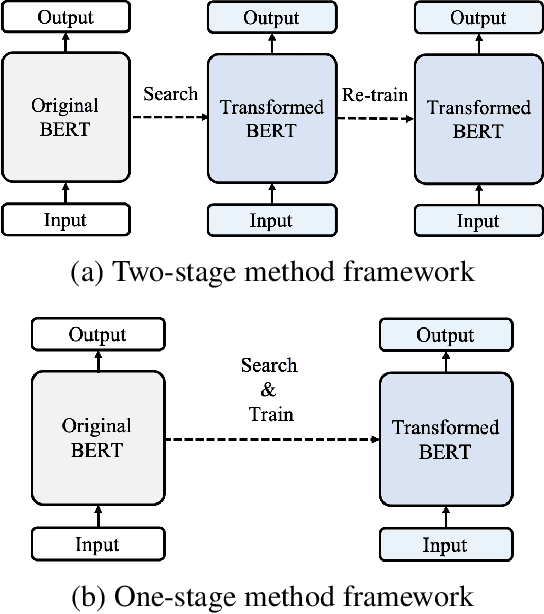



The BERT model has shown significant success on various natural language processing tasks. However, due to the heavy model size and high computational cost, the model suffers from high latency, which is fatal to its deployments on resource-limited devices. To tackle this problem, we propose a dynamic inference method on BERT via trainable gate variables applied on input tokens and a regularizer that has a bi-modal property. Our method shows reduced computational cost on the GLUE dataset with a minimal performance drop. Moreover, the model adjusts with a trade-off between performance and computational cost with the user-specified hyperparameter.
Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation
Dec 21, 2020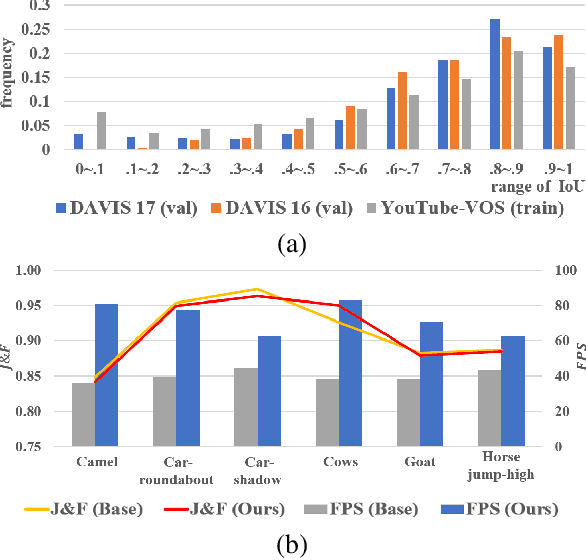
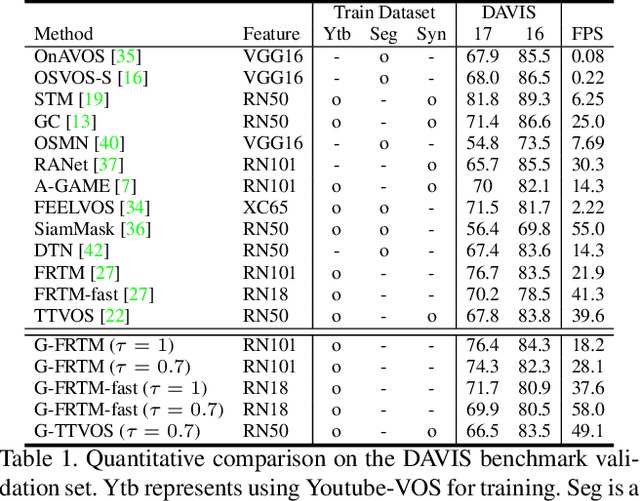
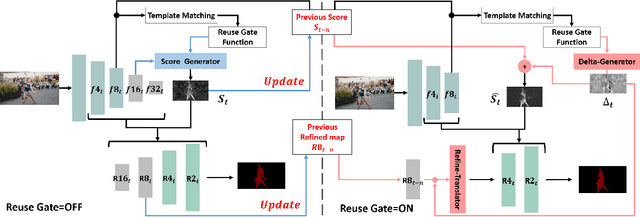
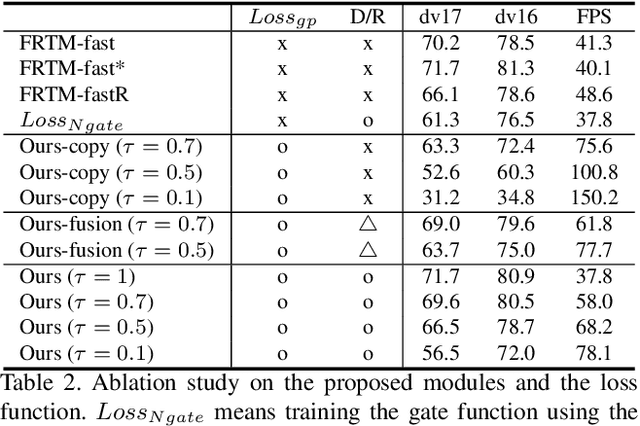
Current state-of-the-art approaches for Semi-supervised Video Object Segmentation (Semi-VOS) propagates information from previous frames to generate segmentation mask for the current frame. This results in high-quality segmentation across challenging scenarios such as changes in appearance and occlusion. But it also leads to unnecessary computations for stationary or slow-moving objects where the change across frames is minimal. In this work, we exploit this observation by using temporal information to quickly identify frames with minimal change and skip the heavyweight mask generation step. To realize this efficiency, we propose a novel dynamic network that estimates change across frames and decides which path -- computing a full network or reusing previous frame's feature -- to choose depending on the expected similarity. Experimental results show that our approach significantly improves inference speed without much accuracy degradation on challenging Semi-VOS datasets -- DAVIS 16, DAVIS 17, and YouTube-VOS. Furthermore, our approach can be applied to multiple Semi-VOS methods demonstrating its generality.
Self-supervised pre-training and contrastive representation learning for multiple-choice video QA
Sep 17, 2020
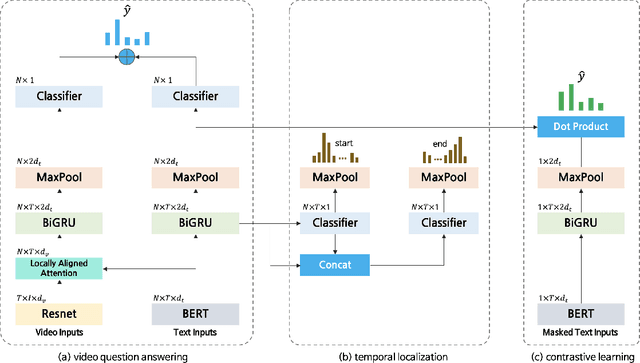
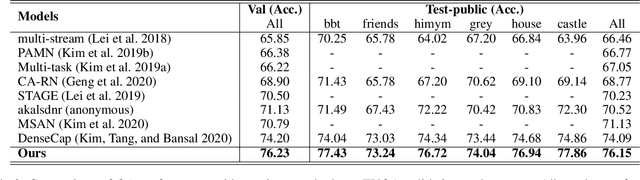
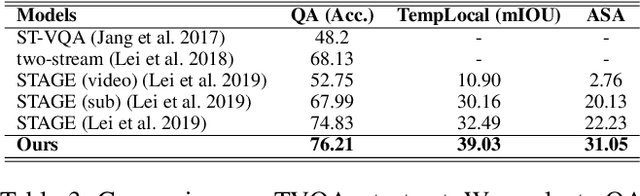
Video Question Answering (Video QA) requires fine-grained understanding of both video and language modalities to answer the given questions. In this paper, we propose novel training schemes for multiple-choice video question answering with a self-supervised pre-training stage and a supervised contrastive learning in the main stage as an auxiliary learning. In the self-supervised pre-training stage, we transform the original problem format of predicting the correct answer into the one that predicts the relevant question to provide a model with broader contextual inputs without any further dataset or annotation. For contrastive learning in the main stage, we add a masking noise to the input corresponding to the ground-truth answer, and consider the original input of the ground-truth answer as a positive sample, while treating the rest as negative samples. By mapping the positive sample closer to the masked input, we show that the model performance is improved. We further employ locally aligned attention to focus more effectively on the video frames that are particularly relevant to the given corresponding subtitle sentences. We evaluate our proposed model on highly competitive benchmark datasets related to multiple-choice videoQA: TVQA, TVQA+, and DramaQA. Experimental results show that our model achieves state-of-the-art performance on all datasets. We also validate our approaches through further analyses.