 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Peril of Preference: Why GRPO fails on Ordinal Rewards
Nov 06, 2025

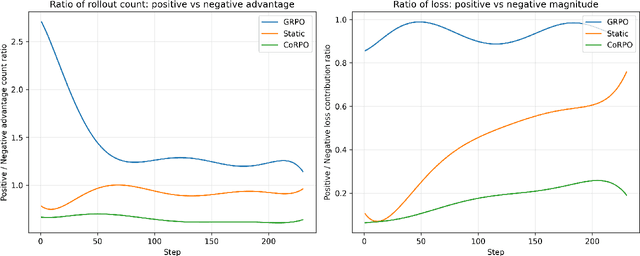
Group-relative Policy Optimization's (GRPO) simplicity makes it highly desirable for adapting LLMs to become experts at specific tasks. But this simplicity also makes it ill-specified as we seek to enhance RL training with richer, non-binary feedback. When using ordinal rewards to give partial credit, GRPO's simplicity starts to hurt, as its group-average baseline often assigns a positive advantage to failed trajectories and reinforces incorrect behavior. We introduce Correctness Relative Policy Optimization (CoRPO), a new formulation that solves this flaw. CoRPO uses an adaptive baseline that enforces a minimum quality threshold, ensuring failed solutions are never positively reinforced. Once the policy consistently meets this threshold, the baseline automatically transitions to a relative preference mode, pushing the model to find optimal solutions rather than just "acceptable" ones. We empirically validate CoRPO on a code verification task, where it demonstrates more stable convergence and better out-of-domain generalization. This work represents a critical step in our broader research program to enable LLMs to learn genuinely new capabilities through reinforcement learning. We achieve this by enabling LLMs to learn from rich, multi-dimensional feedback - progressing from binary to ordinal rewards in this work, and onward to denser, per-step supervision.
From Amateur to Master: Infusing Knowledge into LLMs via Automated Curriculum Learning
Oct 30, 2025



Large Language Models (LLMs) excel at general tasks but underperform in specialized domains like economics and psychology, which require deep, principled understanding. To address this, we introduce ACER (Automated Curriculum-Enhanced Regimen) that transforms generalist models into domain experts without sacrificing their broad capabilities. ACER first synthesizes a comprehensive, textbook-style curriculum by generating a table of contents for a subject and then creating question-answer (QA) pairs guided by Bloom's taxonomy. This ensures systematic topic coverage and progressively increasing difficulty. The resulting synthetic corpus is used for continual pretraining with an interleaved curriculum schedule, aligning learning across both content and cognitive dimensions. Experiments with Llama 3.2 (1B and 3B) show significant gains in specialized MMLU subsets. In challenging domains like microeconomics, where baselines struggle, ACER boosts accuracy by 5 percentage points. Across all target domains, we observe a consistent macro-average improvement of 3 percentage points. Notably, ACER not only prevents catastrophic forgetting but also facilitates positive cross-domain knowledge transfer, improving performance on non-target domains by 0.7 points. Beyond MMLU, ACER enhances performance on knowledge-intensive benchmarks like ARC and GPQA by over 2 absolute points, while maintaining stable performance on general reasoning tasks. Our results demonstrate that ACER offers a scalable and effective recipe for closing critical domain gaps in LLMs.
Looking Beyond Language Priors: Enhancing Visual Comprehension and Attention in Multimodal Models
May 08, 2025

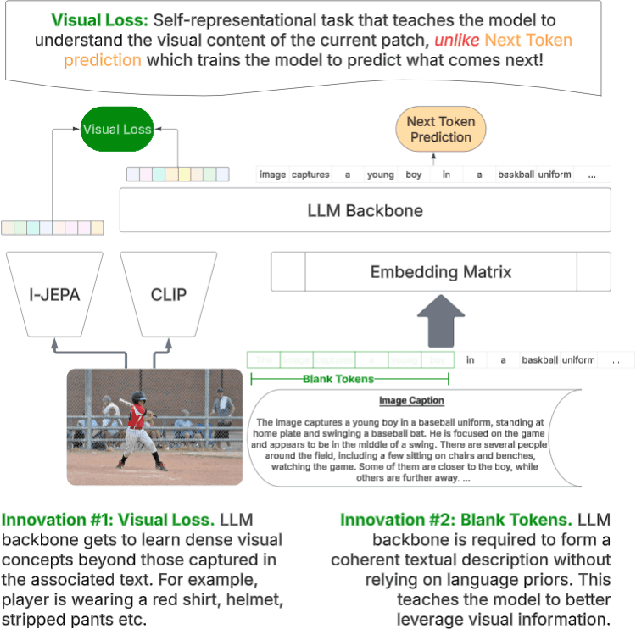
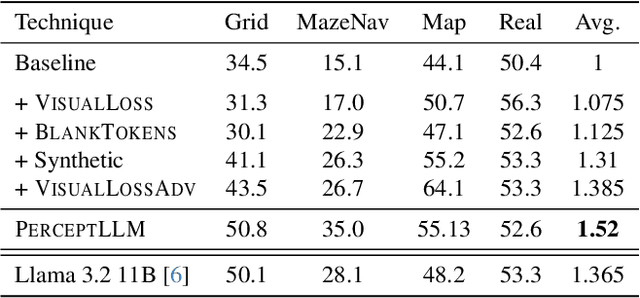
Achieving deep alignment between vision and language remains a central challenge for Multimodal Large Language Models (MLLMs). These models often fail to fully leverage visual input, defaulting to strong language priors. Our approach first provides insights into how MLLMs internally build visual understanding of image regions and then introduces techniques to amplify this capability. Specifically, we explore techniques designed both to deepen the model's understanding of visual content and to ensure that these visual insights actively guide language generation. We demonstrate the superior multimodal understanding of our resultant model through a detailed upstream analysis quantifying its ability to predict visually-dependent tokens as well as 10 pt boost on visually challenging tasks.
Self-Data Distillation for Recovering Quality in Pruned Large Language Models
Oct 15, 2024Large language models have driven significant progress in natural language processing, but their deployment requires substantial compute and memory resources. As models scale, compression techniques become essential for balancing model quality with computational efficiency. Structured pruning, which removes less critical components of the model, is a promising strategy for reducing complexity. However, one-shot pruning often results in significant quality degradation, particularly in tasks requiring multi-step reasoning. To recover lost quality, supervised fine-tuning (SFT) is commonly applied, but it can lead to catastrophic forgetting by shifting the model's learned data distribution. Therefore, addressing the degradation from both pruning and SFT is essential to preserve the original model's quality. In this work, we propose self-data distilled fine-tuning to address these challenges. Our approach leverages the original, unpruned model to generate a distilled dataset that preserves semantic richness and mitigates catastrophic forgetting by maintaining alignment with the base model's knowledge. Empirically, we demonstrate that self-data distillation consistently outperforms standard SFT, improving average accuracy by up to 8% on the HuggingFace OpenLLM Leaderboard v1. Specifically, when pruning 6 decoder blocks on Llama3.1-8B Instruct (i.e., 32 to 26 layers, reducing the model size from 8.03B to 6.72B parameters), our method retains 91.2% of the original model's accuracy compared to 81.7% with SFT, while reducing real-world FLOPs by 16.30%. Furthermore, our approach scales effectively across datasets, with the quality improving as the dataset size increases.
Temporally Consistent Online Depth Estimation in Dynamic Scenes
Nov 17, 2021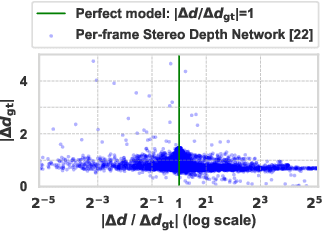
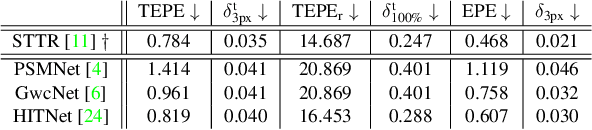
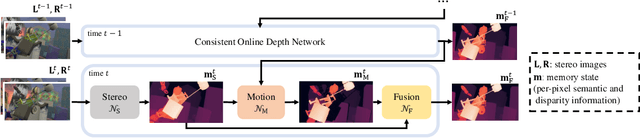
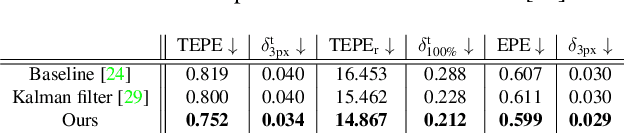
Temporally consistent depth estimation is crucial for real-time applications such as augmented reality. While stereo depth estimation has received substantial attention that led to improvements on a frame-by-frame basis, there is relatively little work focused on maintaining temporal consistency across frames. Indeed, based on our analysis, current stereo depth estimation techniques still suffer from poor temporal consistency. Stabilizing depth temporally in dynamic scenes is challenging due to concurrent object and camera motion. In an online setting, this process is further aggravated because only past frames are available. In this paper, we present a technique to produce temporally consistent depth estimates in dynamic scenes in an online setting. Our network augments current per-frame stereo networks with novel motion and fusion networks. The motion network accounts for both object and camera motion by predicting a per-pixel SE3 transformation. The fusion network improves consistency in prediction by aggregating the current and previous predictions with regressed weights. We conduct extensive experiments across varied datasets (synthetic, outdoor, indoor and medical). In both zero-shot generalization and domain fine-tuning, we demonstrate that our proposed approach outperforms competing methods in terms of temporal stability and per-frame accuracy, both quantitatively and qualitatively. Our code will be available online.
Omni-sparsity DNN: Fast Sparsity Optimization for On-Device Streaming E2E ASR via Supernet
Oct 15, 2021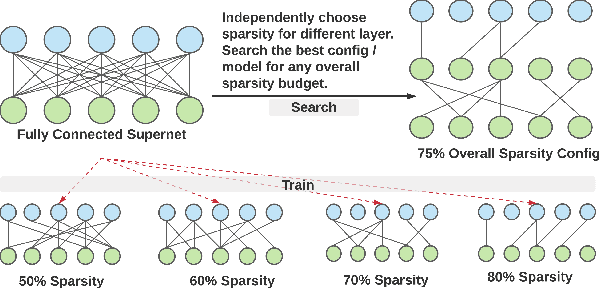
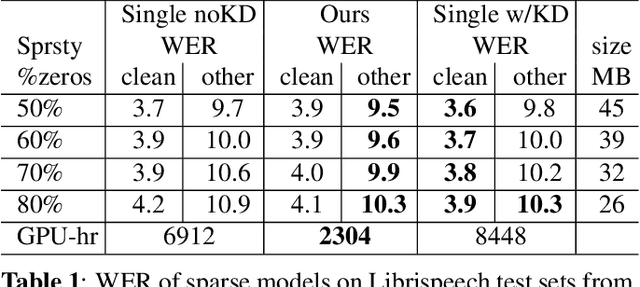
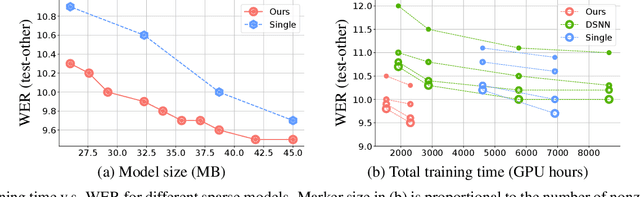
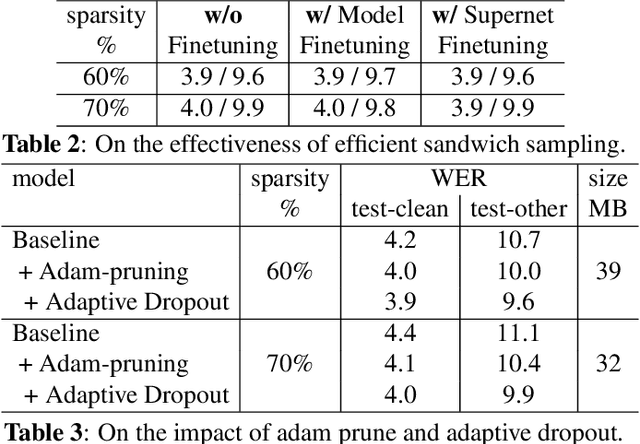
From wearables to powerful smart devices, modern automatic speech recognition (ASR) models run on a variety of edge devices with different computational budgets. To navigate the Pareto front of model accuracy vs model size, researchers are trapped in a dilemma of optimizing model accuracy by training and fine-tuning models for each individual edge device while keeping the training GPU-hours tractable. In this paper, we propose Omni-sparsity DNN, where a single neural network can be pruned to generate optimized model for a large range of model sizes. We develop training strategies for Omni-sparsity DNN that allows it to find models along the Pareto front of word-error-rate (WER) vs model size while keeping the training GPU-hours to no more than that of training one singular model. We demonstrate the Omni-sparsity DNN with streaming E2E ASR models. Our results show great saving on training time and resources with similar or better accuracy on LibriSpeech compared to individually pruned sparse models: 2%-6.6% better WER on Test-other.
Collaborative Training of Acoustic Encoders for Speech Recognition
Jul 13, 2021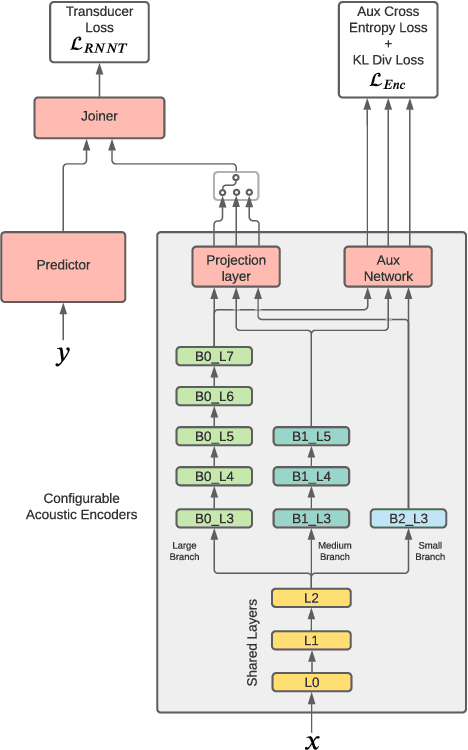
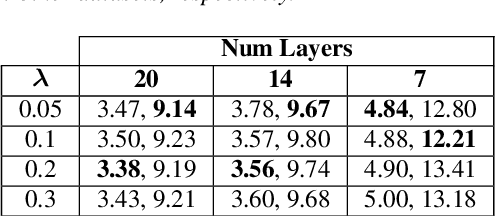
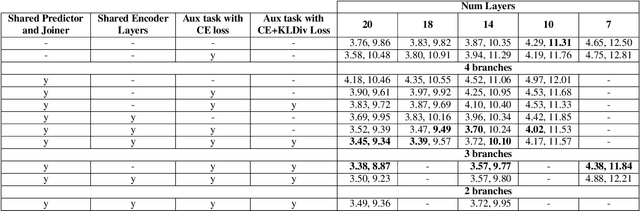
On-device speech recognition requires training models of different sizes for deploying on devices with various computational budgets. When building such different models, we can benefit from training them jointly to take advantage of the knowledge shared between them. Joint training is also efficient since it reduces the redundancy in the training procedure's data handling operations. We propose a method for collaboratively training acoustic encoders of different sizes for speech recognition. We use a sequence transducer setup where different acoustic encoders share a common predictor and joiner modules. The acoustic encoders are also trained using co-distillation through an auxiliary task for frame level chenone prediction, along with the transducer loss. We perform experiments using the LibriSpeech corpus and demonstrate that the collaboratively trained acoustic encoders can provide up to a 11% relative improvement in the word error rate on both the test partitions.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021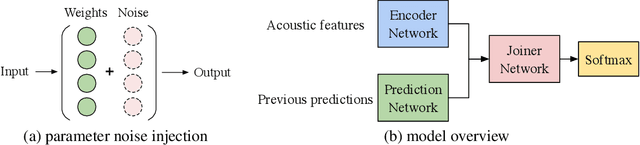
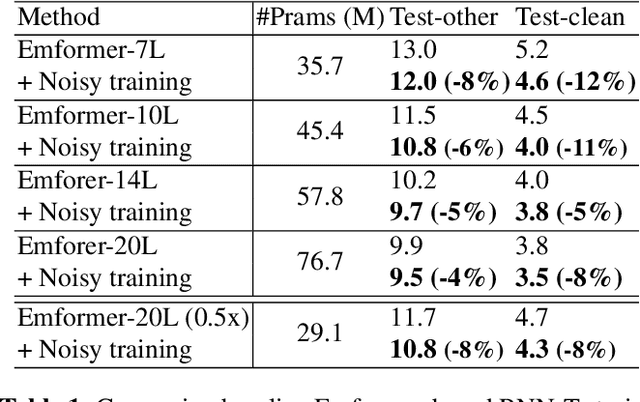
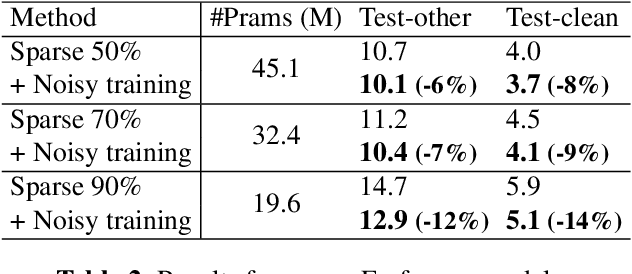
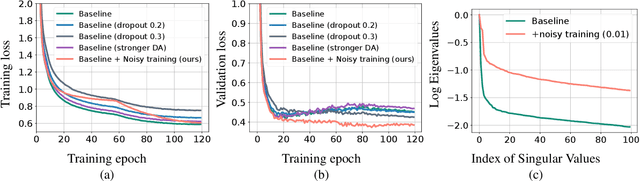
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.
Latency-Aware Neural Architecture Search with Multi-Objective Bayesian Optimization
Jun 25, 2021

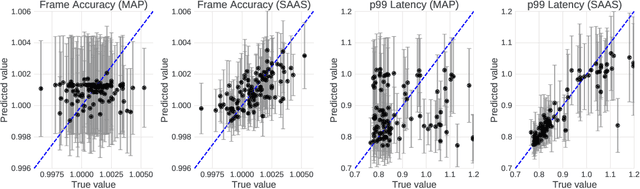
When tuning the architecture and hyperparameters of large machine learning models for on-device deployment, it is desirable to understand the optimal trade-offs between on-device latency and model accuracy. In this work, we leverage recent methodological advances in Bayesian optimization over high-dimensional search spaces and multi-objective Bayesian optimization to efficiently explore these trade-offs for a production-scale on-device natural language understanding model at Facebook.
Accelerating Sparse Deep Neural Networks
Apr 16, 2021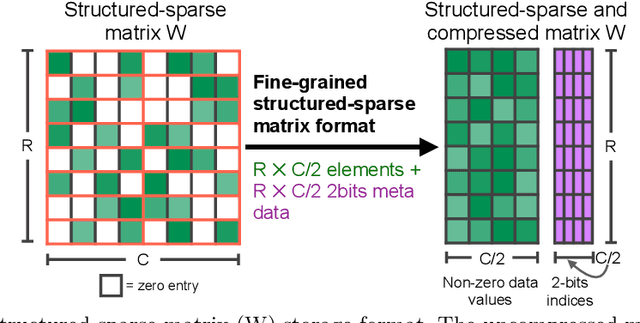
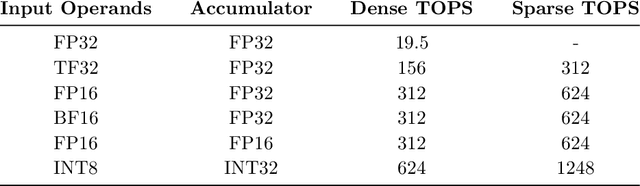
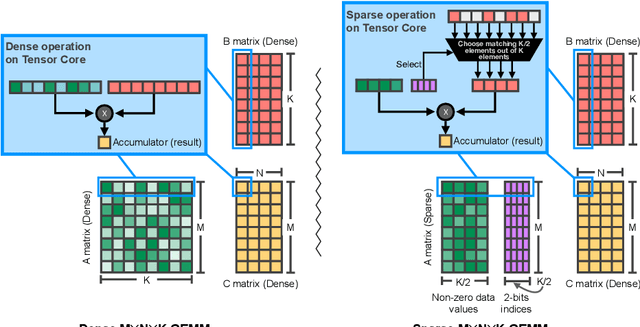
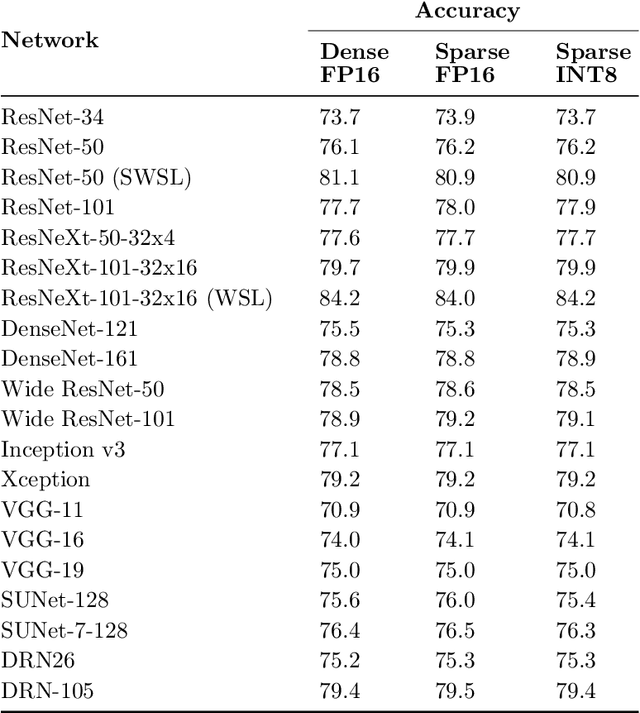
As neural network model sizes have dramatically increased, so has the interest in various techniques to reduce their parameter counts and accelerate their execution. An active area of research in this field is sparsity - encouraging zero values in parameters that can then be discarded from storage or computations. While most research focuses on high levels of sparsity, there are challenges in universally maintaining model accuracy as well as achieving significant speedups over modern matrix-math hardware. To make sparsity adoption practical, the NVIDIA Ampere GPU architecture introduces sparsity support in its matrix-math units, Tensor Cores. We present the design and behavior of Sparse Tensor Cores, which exploit a 2:4 (50%) sparsity pattern that leads to twice the math throughput of dense matrix units. We also describe a simple workflow for training networks that both satisfy 2:4 sparsity pattern requirements and maintain accuracy, verifying it on a wide range of common tasks and model architectures. This workflow makes it easy to prepare accurate models for efficient deployment on Sparse Tensor Cores.