 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Masking for Cost-Constrained Channel Pruning
Nov 04, 2022Structured channel pruning has been shown to significantly accelerate inference time for convolution neural networks (CNNs) on modern hardware, with a relatively minor loss of network accuracy. Recent works permanently zero these channels during training, which we observe to significantly hamper final accuracy, particularly as the fraction of the network being pruned increases. We propose Soft Masking for cost-constrained Channel Pruning (SMCP) to allow pruned channels to adaptively return to the network while simultaneously pruning towards a target cost constraint. By adding a soft mask re-parameterization of the weights and channel pruning from the perspective of removing input channels, we allow gradient updates to previously pruned channels and the opportunity for the channels to later return to the network. We then formulate input channel pruning as a global resource allocation problem. Our method outperforms prior works on both the ImageNet classification and PASCAL VOC detection datasets.
Accelerating Sparse Deep Neural Networks
Apr 16, 2021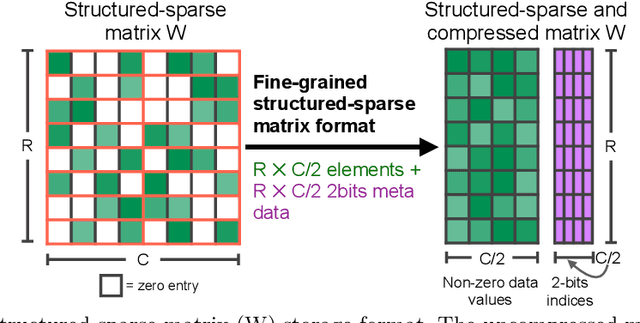
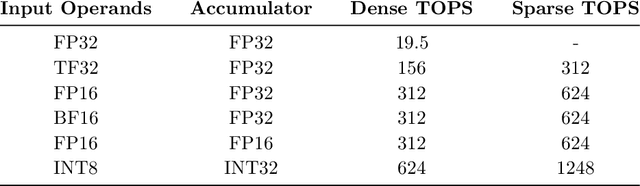
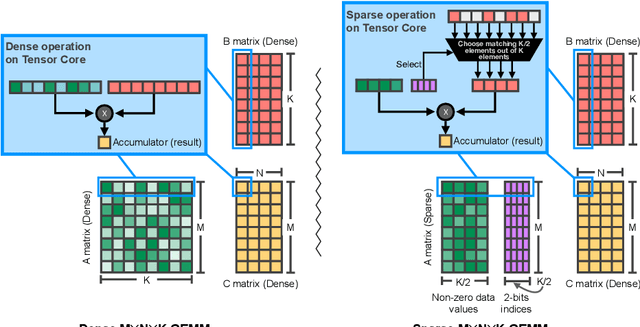
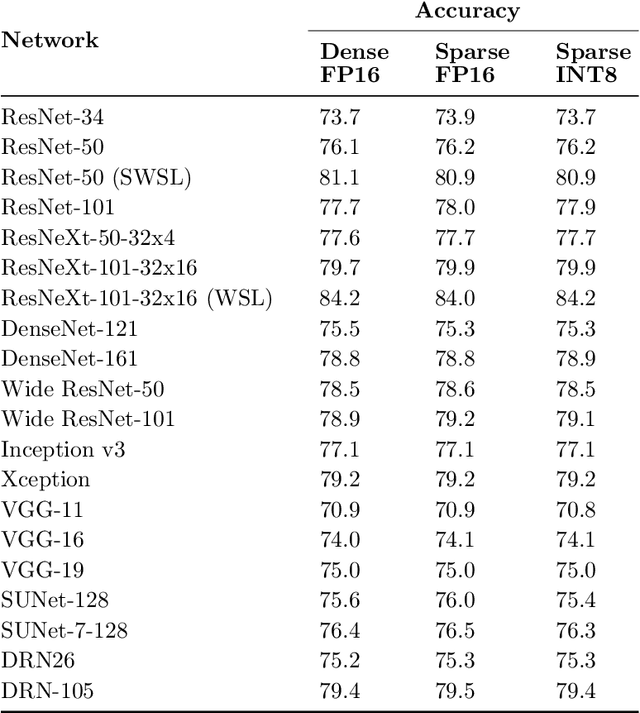
As neural network model sizes have dramatically increased, so has the interest in various techniques to reduce their parameter counts and accelerate their execution. An active area of research in this field is sparsity - encouraging zero values in parameters that can then be discarded from storage or computations. While most research focuses on high levels of sparsity, there are challenges in universally maintaining model accuracy as well as achieving significant speedups over modern matrix-math hardware. To make sparsity adoption practical, the NVIDIA Ampere GPU architecture introduces sparsity support in its matrix-math units, Tensor Cores. We present the design and behavior of Sparse Tensor Cores, which exploit a 2:4 (50%) sparsity pattern that leads to twice the math throughput of dense matrix units. We also describe a simple workflow for training networks that both satisfy 2:4 sparsity pattern requirements and maintain accuracy, verifying it on a wide range of common tasks and model architectures. This workflow makes it easy to prepare accurate models for efficient deployment on Sparse Tensor Cores.