 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Accelerating Sparse Deep Neural Networks
Apr 16, 2021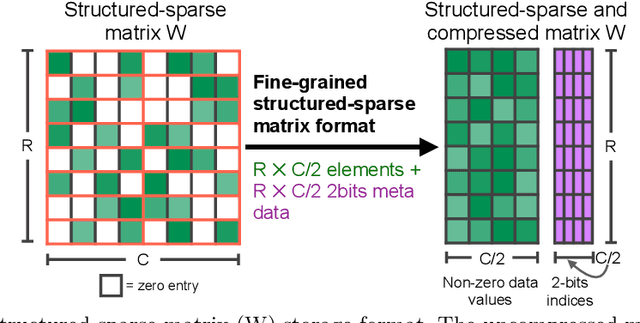
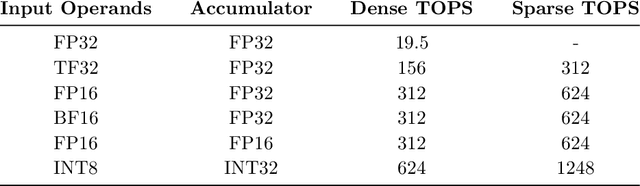
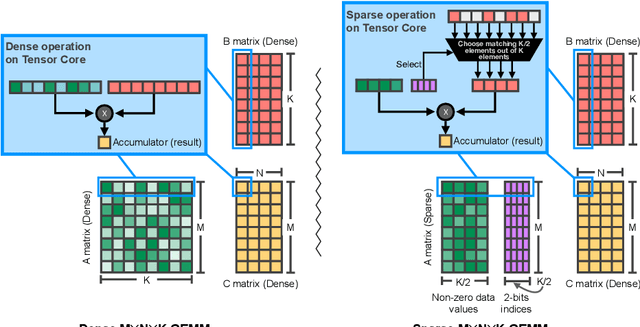
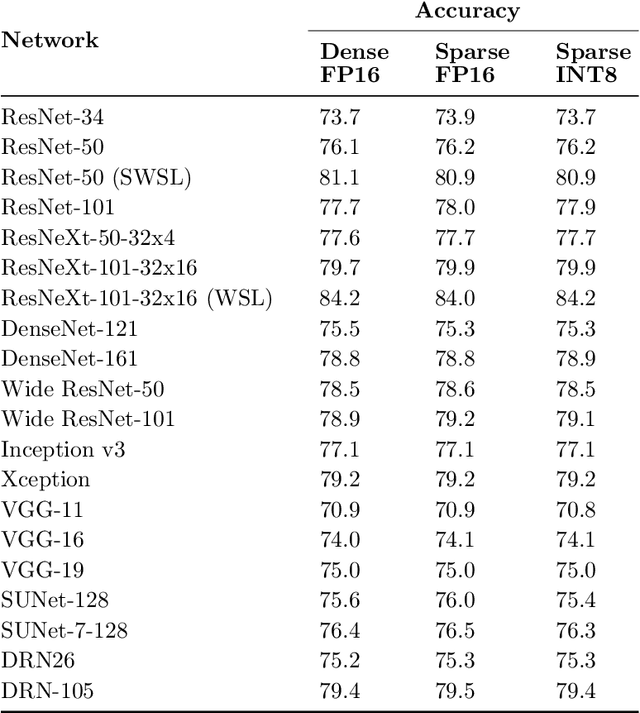
As neural network model sizes have dramatically increased, so has the interest in various techniques to reduce their parameter counts and accelerate their execution. An active area of research in this field is sparsity - encouraging zero values in parameters that can then be discarded from storage or computations. While most research focuses on high levels of sparsity, there are challenges in universally maintaining model accuracy as well as achieving significant speedups over modern matrix-math hardware. To make sparsity adoption practical, the NVIDIA Ampere GPU architecture introduces sparsity support in its matrix-math units, Tensor Cores. We present the design and behavior of Sparse Tensor Cores, which exploit a 2:4 (50%) sparsity pattern that leads to twice the math throughput of dense matrix units. We also describe a simple workflow for training networks that both satisfy 2:4 sparsity pattern requirements and maintain accuracy, verifying it on a wide range of common tasks and model architectures. This workflow makes it easy to prepare accurate models for efficient deployment on Sparse Tensor Cores.
WRPN & Apprentice: Methods for Training and Inference using Low-Precision Numerics
Mar 01, 2018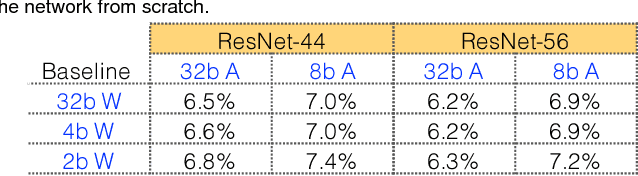
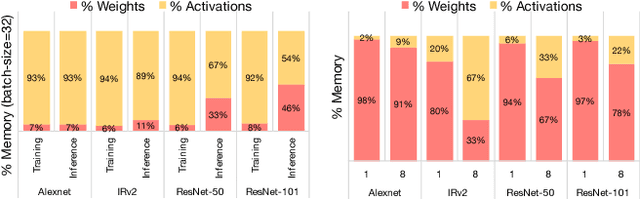
Today's high performance deep learning architectures involve large models with numerous parameters. Low precision numerics has emerged as a popular technique to reduce both the compute and memory requirements of these large models. However, lowering precision often leads to accuracy degradation. We describe three schemes whereby one can both train and do efficient inference using low precision numerics without hurting accuracy. Finally, we describe an efficient hardware accelerator that can take advantage of the proposed low precision numerics.
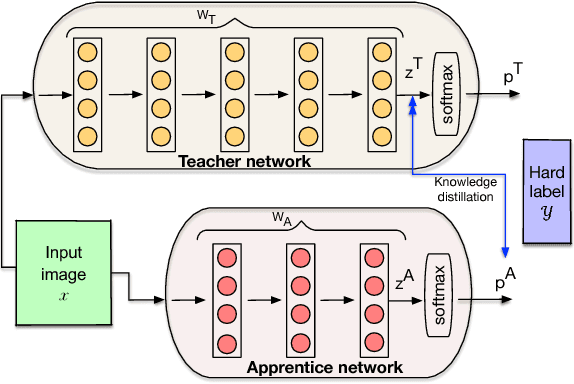
Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy
Nov 15, 2017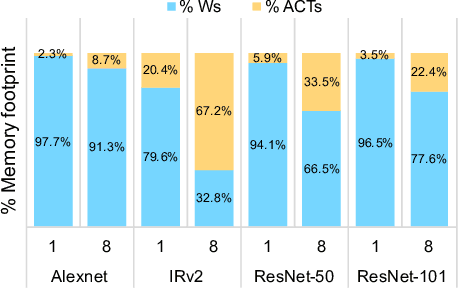

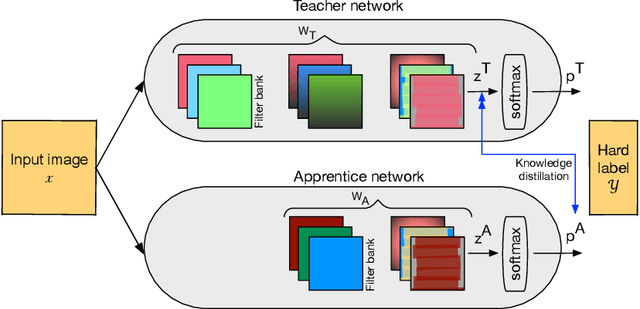

Deep learning networks have achieved state-of-the-art accuracies on computer vision workloads like image classification and object detection. The performant systems, however, typically involve big models with numerous parameters. Once trained, a challenging aspect for such top performing models is deployment on resource constrained inference systems - the models (often deep networks or wide networks or both) are compute and memory intensive. Low-precision numerics and model compression using knowledge distillation are popular techniques to lower both the compute requirements and memory footprint of these deployed models. In this paper, we study the combination of these two techniques and show that the performance of low-precision networks can be significantly improved by using knowledge distillation techniques. Our approach, Apprentice, achieves state-of-the-art accuracies using ternary precision and 4-bit precision for variants of ResNet architecture on ImageNet dataset. We present three schemes using which one can apply knowledge distillation techniques to various stages of the train-and-deploy pipeline.
Low Precision RNNs: Quantizing RNNs Without Losing Accuracy
Oct 20, 2017
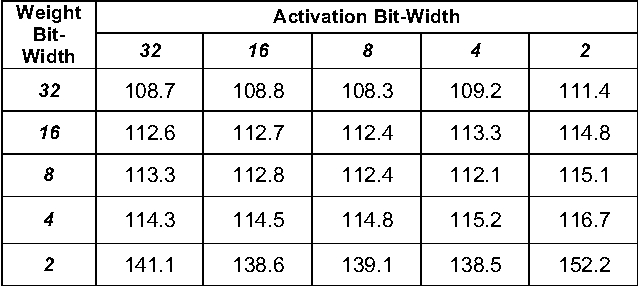
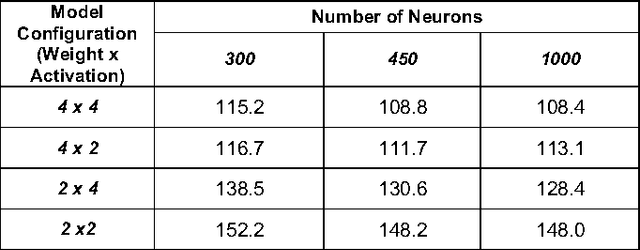

Similar to convolution neural networks, recurrent neural networks (RNNs) typically suffer from over-parameterization. Quantizing bit-widths of weights and activations results in runtime efficiency on hardware, yet it often comes at the cost of reduced accuracy. This paper proposes a quantization approach that increases model size with bit-width reduction. This approach will allow networks to perform at their baseline accuracy while still maintaining the benefits of reduced precision and overall model size reduction.
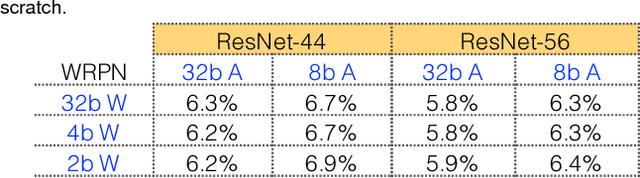
WRPN: Wide Reduced-Precision Networks
Sep 04, 2017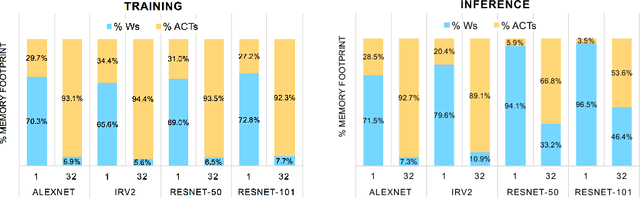
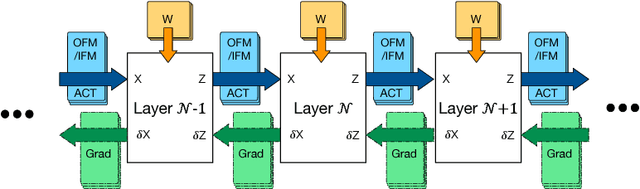

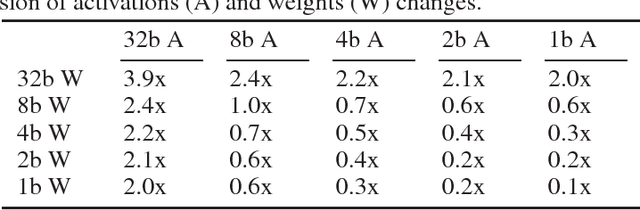
For computer vision applications, prior works have shown the efficacy of reducing numeric precision of model parameters (network weights) in deep neural networks. Activation maps, however, occupy a large memory footprint during both the training and inference step when using mini-batches of inputs. One way to reduce this large memory footprint is to reduce the precision of activations. However, past works have shown that reducing the precision of activations hurts model accuracy. We study schemes to train networks from scratch using reduced-precision activations without hurting accuracy. We reduce the precision of activation maps (along with model parameters) and increase the number of filter maps in a layer, and find that this scheme matches or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly improve the execution efficiency (e.g. reduce dynamic memory footprint, memory bandwidth and computational energy) and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results and show that WRPN scheme is better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.
WRPN: Training and Inference using Wide Reduced-Precision Networks
Apr 10, 2017

For computer vision applications, prior works have shown the efficacy of reducing the numeric precision of model parameters (network weights) in deep neural networks but also that reducing the precision of activations hurts model accuracy much more than reducing the precision of model parameters. We study schemes to train networks from scratch using reduced-precision activations without hurting the model accuracy. We reduce the precision of activation maps (along with model parameters) using a novel quantization scheme and increase the number of filter maps in a layer, and find that this scheme compensates or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly reduce the dynamic memory footprint, memory bandwidth, computational energy and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results using our proposed schemes and show that our results are better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.