 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRPN: Wide Reduced-Precision Networks
Sep 04, 2017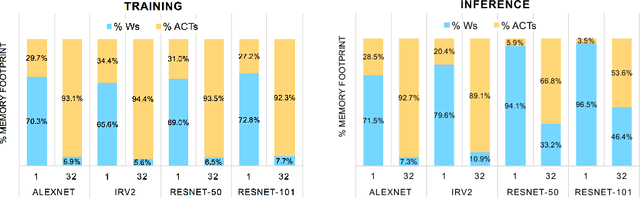
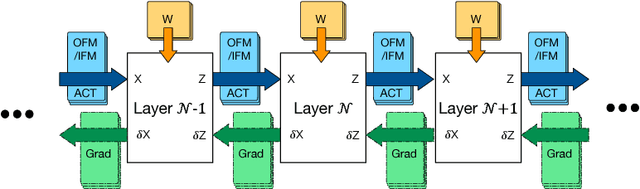

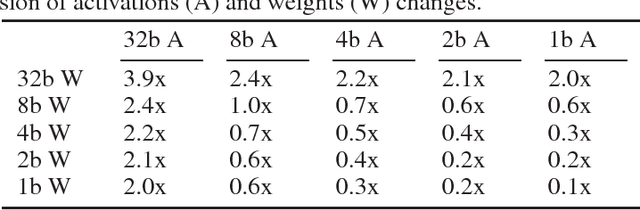
For computer vision applications, prior works have shown the efficacy of reducing numeric precision of model parameters (network weights) in deep neural networks. Activation maps, however, occupy a large memory footprint during both the training and inference step when using mini-batches of inputs. One way to reduce this large memory footprint is to reduce the precision of activations. However, past works have shown that reducing the precision of activations hurts model accuracy. We study schemes to train networks from scratch using reduced-precision activations without hurting accuracy. We reduce the precision of activation maps (along with model parameters) and increase the number of filter maps in a layer, and find that this scheme matches or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly improve the execution efficiency (e.g. reduce dynamic memory footprint, memory bandwidth and computational energy) and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results and show that WRPN scheme is better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.
WRPN: Training and Inference using Wide Reduced-Precision Networks
Apr 10, 2017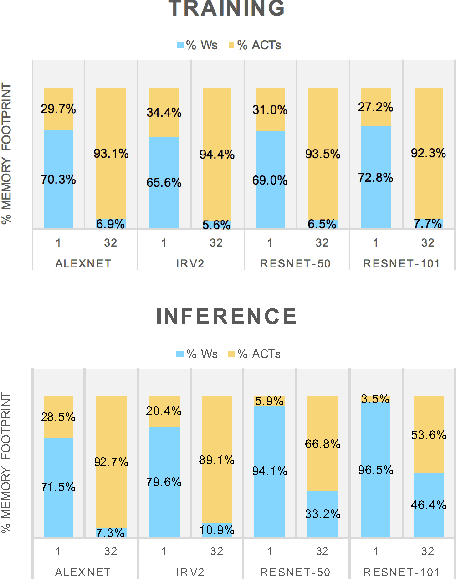

For computer vision applications, prior works have shown the efficacy of reducing the numeric precision of model parameters (network weights) in deep neural networks but also that reducing the precision of activations hurts model accuracy much more than reducing the precision of model parameters. We study schemes to train networks from scratch using reduced-precision activations without hurting the model accuracy. We reduce the precision of activation maps (along with model parameters) using a novel quantization scheme and increase the number of filter maps in a layer, and find that this scheme compensates or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly reduce the dynamic memory footprint, memory bandwidth, computational energy and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results using our proposed schemes and show that our results are better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.