 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRPN & Apprentice: Methods for Training and Inference using Low-Precision Numerics
Mar 01, 2018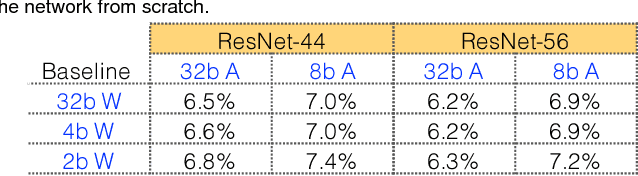
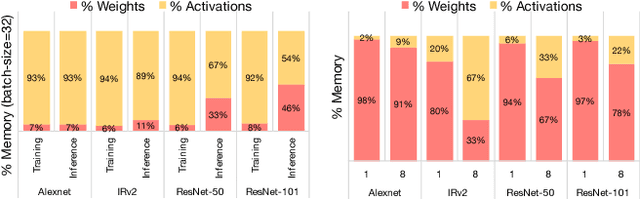
Today's high performance deep learning architectures involve large models with numerous parameters. Low precision numerics has emerged as a popular technique to reduce both the compute and memory requirements of these large models. However, lowering precision often leads to accuracy degradation. We describe three schemes whereby one can both train and do efficient inference using low precision numerics without hurting accuracy. Finally, we describe an efficient hardware accelerator that can take advantage of the proposed low precision numerics.
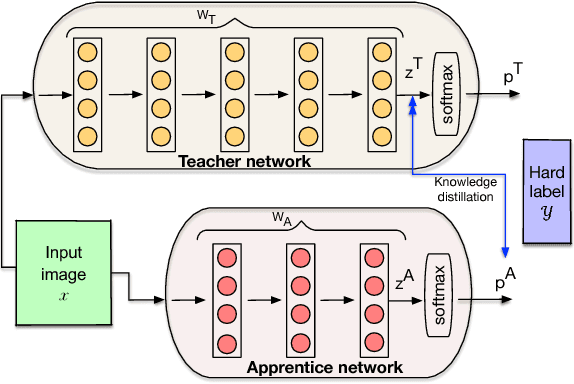
Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy
Nov 15, 2017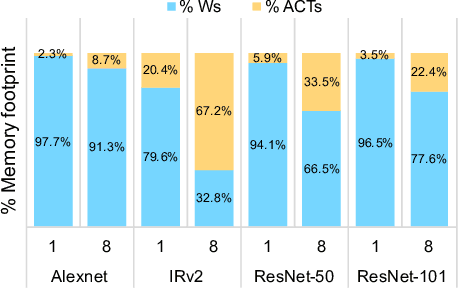

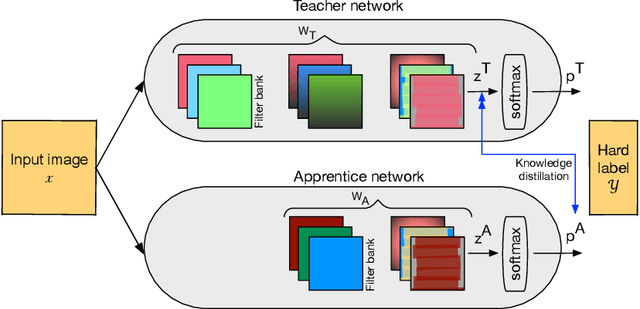

Deep learning networks have achieved state-of-the-art accuracies on computer vision workloads like image classification and object detection. The performant systems, however, typically involve big models with numerous parameters. Once trained, a challenging aspect for such top performing models is deployment on resource constrained inference systems - the models (often deep networks or wide networks or both) are compute and memory intensive. Low-precision numerics and model compression using knowledge distillation are popular techniques to lower both the compute requirements and memory footprint of these deployed models. In this paper, we study the combination of these two techniques and show that the performance of low-precision networks can be significantly improved by using knowledge distillation techniques. Our approach, Apprentice, achieves state-of-the-art accuracies using ternary precision and 4-bit precision for variants of ResNet architecture on ImageNet dataset. We present three schemes using which one can apply knowledge distillation techniques to various stages of the train-and-deploy pipeline.
Low Precision RNNs: Quantizing RNNs Without Losing Accuracy
Oct 20, 2017
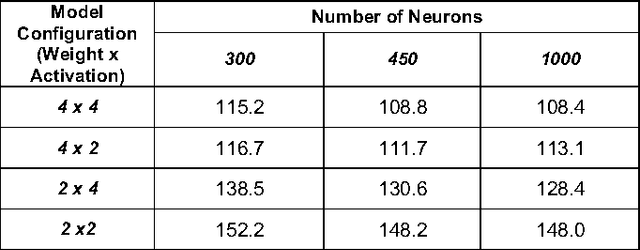

Similar to convolution neural networks, recurrent neural networks (RNNs) typically suffer from over-parameterization. Quantizing bit-widths of weights and activations results in runtime efficiency on hardware, yet it often comes at the cost of reduced accuracy. This paper proposes a quantization approach that increases model size with bit-width reduction. This approach will allow networks to perform at their baseline accuracy while still maintaining the benefits of reduced precision and overall model size reduction.
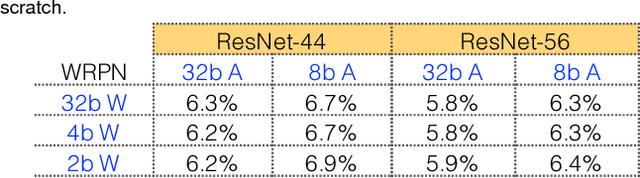
WRPN: Wide Reduced-Precision Networks
Sep 04, 2017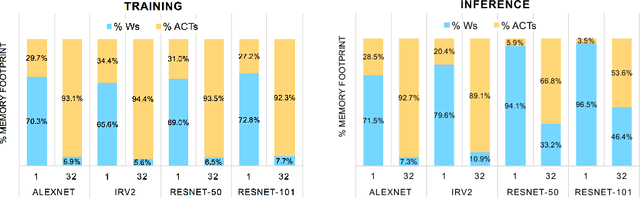
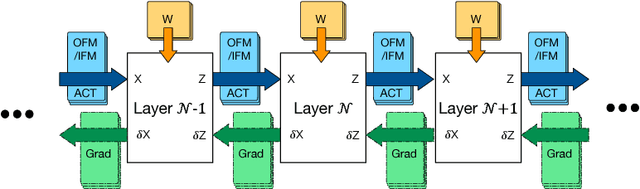

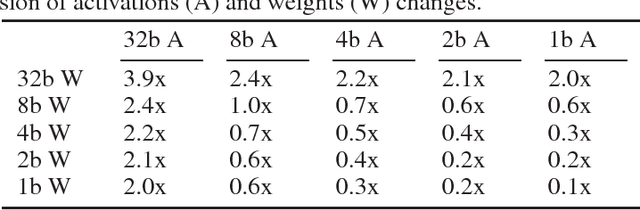
For computer vision applications, prior works have shown the efficacy of reducing numeric precision of model parameters (network weights) in deep neural networks. Activation maps, however, occupy a large memory footprint during both the training and inference step when using mini-batches of inputs. One way to reduce this large memory footprint is to reduce the precision of activations. However, past works have shown that reducing the precision of activations hurts model accuracy. We study schemes to train networks from scratch using reduced-precision activations without hurting accuracy. We reduce the precision of activation maps (along with model parameters) and increase the number of filter maps in a layer, and find that this scheme matches or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly improve the execution efficiency (e.g. reduce dynamic memory footprint, memory bandwidth and computational energy) and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results and show that WRPN scheme is better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.
WRPN: Training and Inference using Wide Reduced-Precision Networks
Apr 10, 2017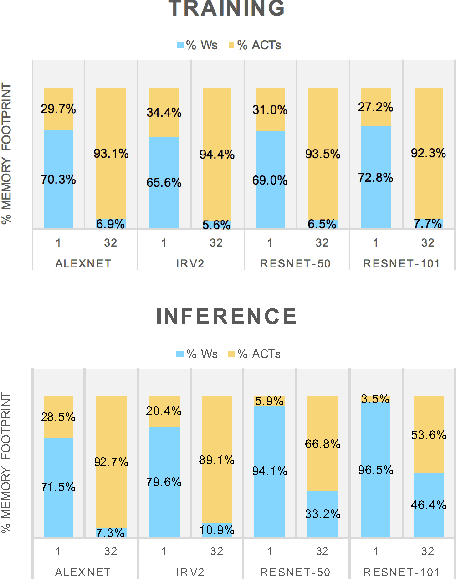

For computer vision applications, prior works have shown the efficacy of reducing the numeric precision of model parameters (network weights) in deep neural networks but also that reducing the precision of activations hurts model accuracy much more than reducing the precision of model parameters. We study schemes to train networks from scratch using reduced-precision activations without hurting the model accuracy. We reduce the precision of activation maps (along with model parameters) using a novel quantization scheme and increase the number of filter maps in a layer, and find that this scheme compensates or surpasses the accuracy of the baseline full-precision network. As a result, one can significantly reduce the dynamic memory footprint, memory bandwidth, computational energy and speed up the training and inference process with appropriate hardware support. We call our scheme WRPN - wide reduced-precision networks. We report results using our proposed schemes and show that our results are better than previously reported accuracies on ILSVRC-12 dataset while being computationally less expensive compared to previously reported reduced-precision networks.
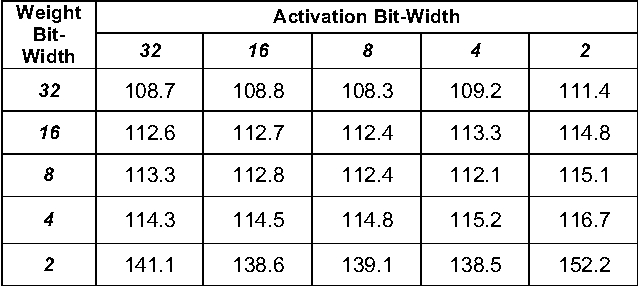
Accelerating Deep Convolutional Networks using low-precision and sparsity
Oct 02, 2016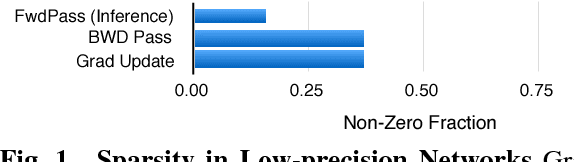



We explore techniques to significantly improve the compute efficiency and performance of Deep Convolution Networks without impacting their accuracy. To improve the compute efficiency, we focus on achieving high accuracy with extremely low-precision (2-bit) weight networks, and to accelerate the execution time, we aggressively skip operations on zero-values. We achieve the highest reported accuracy of 76.6% Top-1/93% Top-5 on the Imagenet object classification challenge with low-precision network\footnote{github release of the source code coming soon} while reducing the compute requirement by ~3x compared to a full-precision network that achieves similar accuracy. Furthermore, to fully exploit the benefits of our low-precision networks, we build a deep learning accelerator core, dLAC, that can achieve up to 1 TFLOP/mm^2 equivalent for single-precision floating-point operations (~2 TFLOP/mm^2 for half-precision).