Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Precision RNNs: Quantizing RNNs Without Losing Accuracy
Paper and Code
Oct 20, 2017
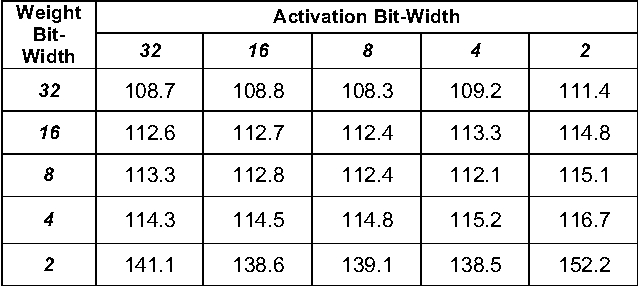
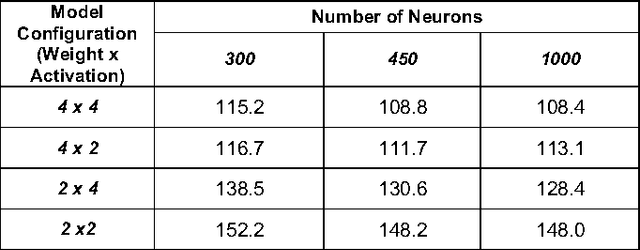

Similar to convolution neural networks, recurrent neural networks (RNNs) typically suffer from over-parameterization. Quantizing bit-widths of weights and activations results in runtime efficiency on hardware, yet it often comes at the cost of reduced accuracy. This paper proposes a quantization approach that increases model size with bit-width reduction. This approach will allow networks to perform at their baseline accuracy while still maintaining the benefits of reduced precision and overall model size reduction.
View paper on