Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRPN & Apprentice: Methods for Training and Inference using Low-Precision Numerics
Paper and Code
Mar 01, 2018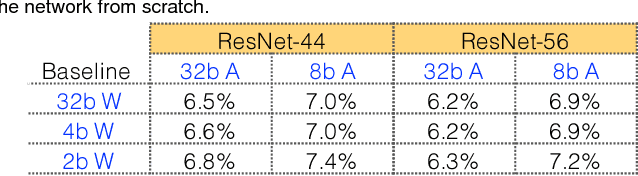
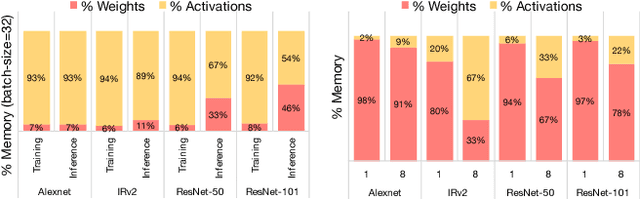
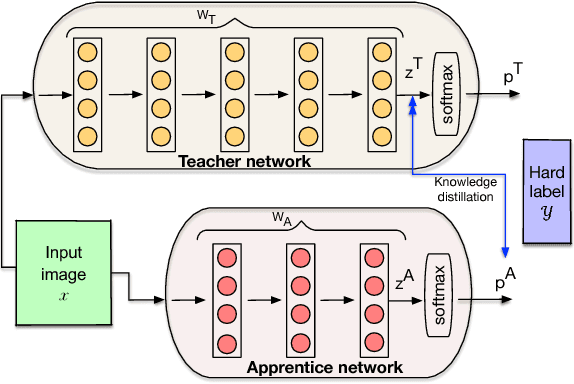
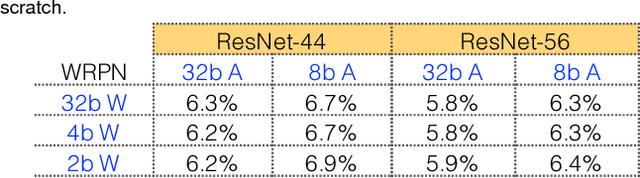
Today's high performance deep learning architectures involve large models with numerous parameters. Low precision numerics has emerged as a popular technique to reduce both the compute and memory requirements of these large models. However, lowering precision often leads to accuracy degradation. We describe three schemes whereby one can both train and do efficient inference using low precision numerics without hurting accuracy. Finally, we describe an efficient hardware accelerator that can take advantage of the proposed low precision numerics.
* Tech report
View paper on