 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiST: A Cross-Attention-Based Multimodal Model for Spatial Transcriptomic
Jan 19, 2026Spatial transcriptomics (ST) enables transcriptome-wide profiling while preserving the spatial context of tissues, offering unprecedented opportunities to study tissue organization and cell-cell interactions in situ. Despite recent advances, existing methods often lack effective integration of histological morphology with molecular profiles, relying on shallow fusion strategies or omitting tissue images altogether, which limits their ability to resolve ambiguous spatial domain boundaries. To address this challenge, we propose MultiST, a unified multimodal framework that jointly models spatial topology, gene expression, and tissue morphology through cross-attention-based fusion. MultiST employs graph-based gene encoders with adversarial alignment to learn robust spatial representations, while integrating color-normalized histological features to capture molecular-morphological dependencies and refine domain boundaries. We evaluated the proposed method on 13 diverse ST datasets spanning two organs, including human brain cortex and breast cancer tissue. MultiST yields spatial domains with clearer and more coherent boundaries than existing methods, leading to more stable pseudotime trajectories and more biologically interpretable cell-cell interaction patterns. The MultiST framework and source code are available at https://github.com/LabJunBMI/MultiST.git.
EGM: Efficiently Learning General Motion Tracking Policy for High Dynamic Humanoid Whole-Body Control
Dec 22, 2025Learning a general motion tracking policy from human motions shows great potential for versatile humanoid whole-body control. Conventional approaches are not only inefficient in data utilization and training processes but also exhibit limited performance when tracking highly dynamic motions. To address these challenges, we propose EGM, a framework that enables efficient learning of a general motion tracking policy. EGM integrates four core designs. Firstly, we introduce a Bin-based Cross-motion Curriculum Adaptive Sampling strategy to dynamically orchestrate the sampling probabilities based on tracking error of each motion bin, eficiently balancing the training process across motions with varying dificulty and durations. The sampled data is then processed by our proposed Composite Decoupled Mixture-of-Experts (CDMoE) architecture, which efficiently enhances the ability to track motions from different distributions by grouping experts separately for upper and lower body and decoupling orthogonal experts from shared experts to separately handle dedicated features and general features. Central to our approach is a key insight we identified: for training a general motion tracking policy, data quality and diversity are paramount. Building on these designs, we develop a three-stage curriculum training flow to progressively enhance the policy's robustness against disturbances. Despite training on only 4.08 hours of data, EGM generalized robustly across 49.25 hours of test motions, outperforming baselines on both routine and highly dynamic tasks.
Pioneering 4-Bit FP Quantization for Diffusion Models: Mixup-Sign Quantization and Timestep-Aware Fine-Tuning
May 27, 2025Model quantization reduces the bit-width of weights and activations, improving memory efficiency and inference speed in diffusion models. However, achieving 4-bit quantization remains challenging. Existing methods, primarily based on integer quantization and post-training quantization fine-tuning, struggle with inconsistent performance. Inspired by the success of floating-point (FP) quantization in large language models, we explore low-bit FP quantization for diffusion models and identify key challenges: the failure of signed FP quantization to handle asymmetric activation distributions, the insufficient consideration of temporal complexity in the denoising process during fine-tuning, and the misalignment between fine-tuning loss and quantization error. To address these challenges, we propose the mixup-sign floating-point quantization (MSFP) framework, first introducing unsigned FP quantization in model quantization, along with timestep-aware LoRA (TALoRA) and denoising-factor loss alignment (DFA), which ensure precise and stable fine-tuning. Extensive experiments show that we are the first to achieve superior performance in 4-bit FP quantization for diffusion models, outperforming existing PTQ fine-tuning methods in 4-bit INT quantization.
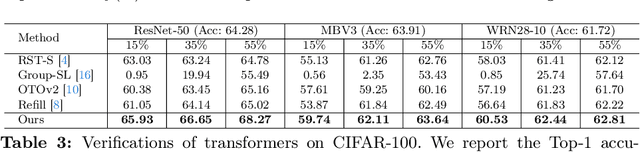
S2HPruner: Soft-to-Hard Distillation Bridges the Discretization Gap in Pruning
Oct 09, 2024Recently, differentiable mask pruning methods optimize the continuous relaxation architecture (soft network) as the proxy of the pruned discrete network (hard network) for superior sub-architecture search. However, due to the agnostic impact of the discretization process, the hard network struggles with the equivalent representational capacity as the soft network, namely discretization gap, which severely spoils the pruning performance. In this paper, we first investigate the discretization gap and propose a novel structural differentiable mask pruning framework named S2HPruner to bridge the discretization gap in a one-stage manner. In the training procedure, SH2Pruner forwards both the soft network and its corresponding hard network, then distills the hard network under the supervision of the soft network. To optimize the mask and prevent performance degradation, we propose a decoupled bidirectional knowledge distillation. It blocks the weight updating from the hard to the soft network while maintaining the gradient corresponding to the mask. Compared with existing pruning arts, S2HPruner achieves surpassing pruning performance without fine-tuning on comprehensive benchmarks, including CIFAR-100, Tiny ImageNet, and ImageNet with a variety of network architectures. Besides, investigation and analysis experiments explain the effectiveness of S2HPruner. Codes will be released soon.
Communication-Efficient Hybrid Federated Learning for E-health with Horizontal and Vertical Data Partitioning
Apr 15, 2024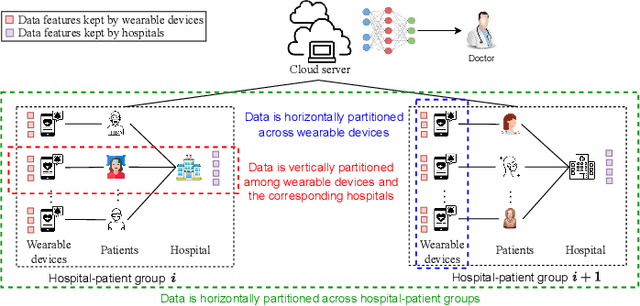
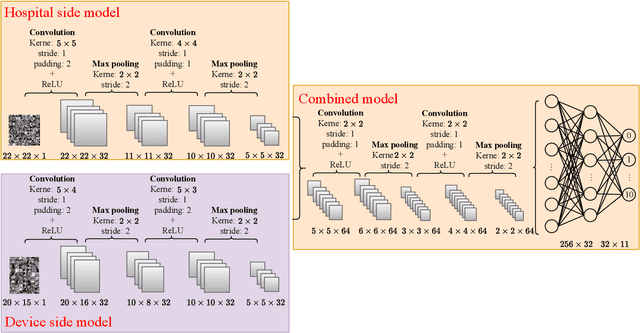

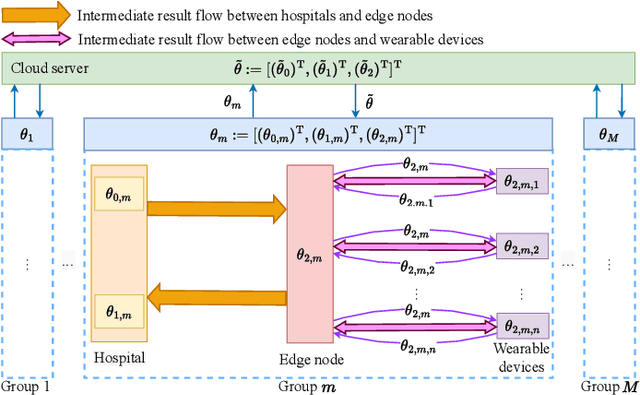
E-health allows smart devices and medical institutions to collaboratively collect patients' data, which is trained by Artificial Intelligence (AI) technologies to help doctors make diagnosis. By allowing multiple devices to train models collaboratively, federated learning is a promising solution to address the communication and privacy issues in e-health. However, applying federated learning in e-health faces many challenges. First, medical data is both horizontally and vertically partitioned. Since single Horizontal Federated Learning (HFL) or Vertical Federated Learning (VFL) techniques cannot deal with both types of data partitioning, directly applying them may consume excessive communication cost due to transmitting a part of raw data when requiring high modeling accuracy. Second, a naive combination of HFL and VFL has limitations including low training efficiency, unsound convergence analysis, and lack of parameter tuning strategies. In this paper, we provide a thorough study on an effective integration of HFL and VFL, to achieve communication efficiency and overcome the above limitations when data is both horizontally and vertically partitioned. Specifically, we propose a hybrid federated learning framework with one intermediate result exchange and two aggregation phases. Based on this framework, we develop a Hybrid Stochastic Gradient Descent (HSGD) algorithm to train models. Then, we theoretically analyze the convergence upper bound of the proposed algorithm. Using the convergence results, we design adaptive strategies to adjust the training parameters and shrink the size of transmitted data. Experimental results validate that the proposed HSGD algorithm can achieve the desired accuracy while reducing communication cost, and they also verify the effectiveness of the adaptive strategies.
Once for Both: Single Stage of Importance and Sparsity Search for Vision Transformer Compression
Mar 23, 2024



Recent Vision Transformer Compression (VTC) works mainly follow a two-stage scheme, where the importance score of each model unit is first evaluated or preset in each submodule, followed by the sparsity score evaluation according to the target sparsity constraint. Such a separate evaluation process induces the gap between importance and sparsity score distributions, thus causing high search costs for VTC. In this work, for the first time, we investigate how to integrate the evaluations of importance and sparsity scores into a single stage, searching the optimal subnets in an efficient manner. Specifically, we present OFB, a cost-efficient approach that simultaneously evaluates both importance and sparsity scores, termed Once for Both (OFB), for VTC. First, a bi-mask scheme is developed by entangling the importance score and the differentiable sparsity score to jointly determine the pruning potential (prunability) of each unit. Such a bi-mask search strategy is further used together with a proposed adaptive one-hot loss to realize the progressive-and-efficient search for the most important subnet. Finally, Progressive Masked Image Modeling (PMIM) is proposed to regularize the feature space to be more representative during the search process, which may be degraded by the dimension reduction. Extensive experiments demonstrate that OFB can achieve superior compression performance over state-of-the-art searching-based and pruning-based methods under various Vision Transformer architectures, meanwhile promoting search efficiency significantly, e.g., costing one GPU search day for the compression of DeiT-S on ImageNet-1K.
Enhanced Sparsification via Stimulative Training
Mar 11, 2024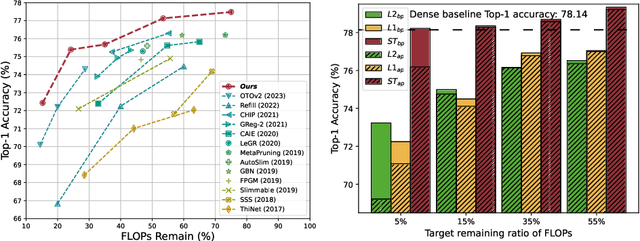

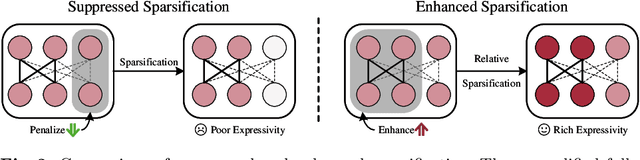
Sparsification-based pruning has been an important category in model compression. Existing methods commonly set sparsity-inducing penalty terms to suppress the importance of dropped weights, which is regarded as the suppressed sparsification paradigm. However, this paradigm inactivates the dropped parts of networks causing capacity damage before pruning, thereby leading to performance degradation. To alleviate this issue, we first study and reveal the relative sparsity effect in emerging stimulative training and then propose a structured pruning framework, named STP, based on an enhanced sparsification paradigm which maintains the magnitude of dropped weights and enhances the expressivity of kept weights by self-distillation. Besides, to find an optimal architecture for the pruned network, we propose a multi-dimension architecture space and a knowledge distillation-guided exploration strategy. To reduce the huge capacity gap of distillation, we propose a subnet mutating expansion technique. Extensive experiments on various benchmarks indicate the effectiveness of STP. Specifically, without fine-tuning, our method consistently achieves superior performance at different budgets, especially under extremely aggressive pruning scenarios, e.g., remaining 95.11% Top-1 accuracy (72.43% in 76.15%) while reducing 85% FLOPs for ResNet-50 on ImageNet. Codes will be released soon.
MADTP: Multimodal Alignment-Guided Dynamic Token Pruning for Accelerating Vision-Language Transformer
Mar 05, 2024Vision-Language Transformers (VLTs) have shown great success recently, but are meanwhile accompanied by heavy computation costs, where a major reason can be attributed to the large number of visual and language tokens. Existing token pruning research for compressing VLTs mainly follows a single-modality-based scheme yet ignores the critical role of aligning different modalities for guiding the token pruning process, causing the important tokens for one modality to be falsely pruned in another modality branch. Meanwhile, existing VLT pruning works also lack the flexibility to dynamically compress each layer based on different input samples. To this end, we propose a novel framework named Multimodal Alignment-Guided Dynamic Token Pruning (MADTP) for accelerating various VLTs. Specifically, we first introduce a well-designed Multi-modality Alignment Guidance (MAG) module that can align features of the same semantic concept from different modalities, to ensure the pruned tokens are less important for all modalities. We further design a novel Dynamic Token Pruning (DTP) module, which can adaptively adjust the token compression ratio in each layer based on different input instances. Extensive experiments on various benchmarks demonstrate that MADTP significantly reduces the computational complexity of kinds of multimodal models while preserving competitive performance. Notably, when applied to the BLIP model in the NLVR2 dataset, MADTP can reduce the GFLOPs by 80% with less than 4% performance degradation.
* 19 pages, 9 figures, Published in CVPR2024
Efficient Architecture Search via Bi-level Data Pruning
Dec 21, 2023Improving the efficiency of Neural Architecture Search (NAS) is a challenging but significant task that has received much attention. Previous works mainly adopted the Differentiable Architecture Search (DARTS) and improved its search strategies or modules to enhance search efficiency. Recently, some methods have started considering data reduction for speedup, but they are not tightly coupled with the architecture search process, resulting in sub-optimal performance. To this end, this work pioneers an exploration into the critical role of dataset characteristics for DARTS bi-level optimization, and then proposes a novel Bi-level Data Pruning (BDP) paradigm that targets the weights and architecture levels of DARTS to enhance efficiency from a data perspective. Specifically, we introduce a new progressive data pruning strategy that utilizes supernet prediction dynamics as the metric, to gradually prune unsuitable samples for DARTS during the search. An effective automatic class balance constraint is also integrated into BDP, to suppress potential class imbalances resulting from data-efficient algorithms. Comprehensive evaluations on the NAS-Bench-201 search space, DARTS search space, and MobileNet-like search space validate that BDP reduces search costs by over 50% while achieving superior performance when applied to baseline DARTS. Besides, we demonstrate that BDP can harmoniously integrate with advanced DARTS variants, like PC-DARTS and \b{eta}-DARTS, offering an approximately 2 times speedup with minimal performance compromises.
SpVOS: Efficient Video Object Segmentation with Triple Sparse Convolution
Oct 23, 2023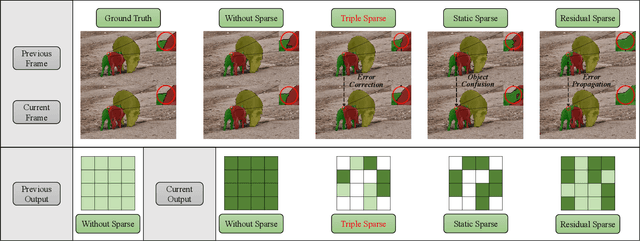
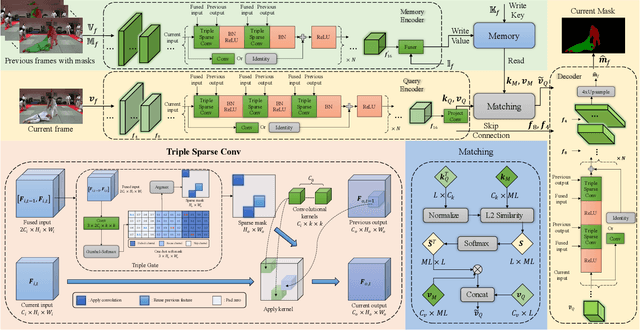
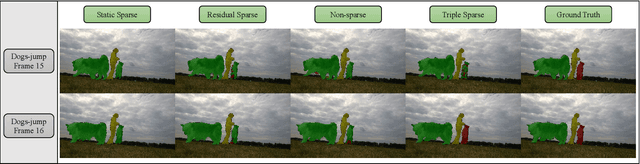
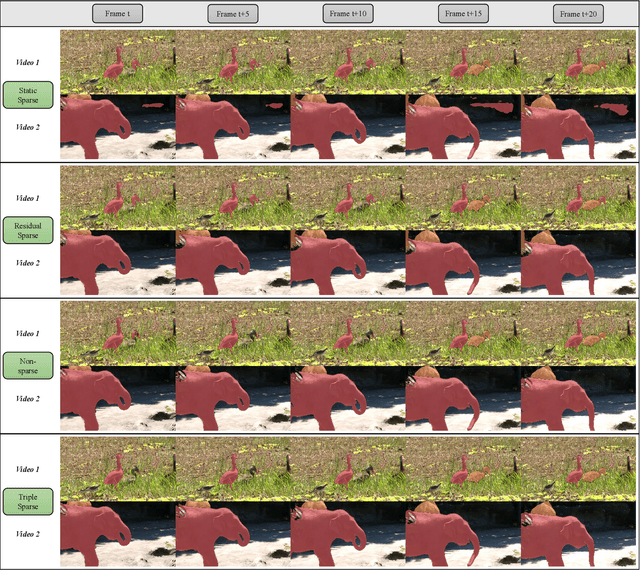
Semi-supervised video object segmentation (Semi-VOS), which requires only annotating the first frame of a video to segment future frames, has received increased attention recently. Among existing pipelines, the memory-matching-based one is becoming the main research stream, as it can fully utilize the temporal sequence information to obtain high-quality segmentation results. Even though this type of method has achieved promising performance, the overall framework still suffers from heavy computation overhead, mainly caused by the per-frame dense convolution operations between high-resolution feature maps and each kernel filter. Therefore, we propose a sparse baseline of VOS named SpVOS in this work, which develops a novel triple sparse convolution to reduce the computation costs of the overall VOS framework. The designed triple gate, taking full consideration of both spatial and temporal redundancy between adjacent video frames, adaptively makes a triple decision to decide how to apply the sparse convolution on each pixel to control the computation overhead of each layer, while maintaining sufficient discrimination capability to distinguish similar objects and avoid error accumulation. A mixed sparse training strategy, coupled with a designed objective considering the sparsity constraint, is also developed to balance the VOS segmentation performance and computation costs. Experiments are conducted on two mainstream VOS datasets, including DAVIS and Youtube-VOS. Results show that, the proposed SpVOS achieves superior performance over other state-of-the-art sparse methods, and even maintains comparable performance, e.g., an 83.04% (79.29%) overall score on the DAVIS-2017 (Youtube-VOS) validation set, with the typical non-sparse VOS baseline (82.88% for DAVIS-2017 and 80.36% for Youtube-VOS) while saving up to 42% FLOPs, showing its application potential for resource-constrained scenarios.