 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.
DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion
Sep 15, 2024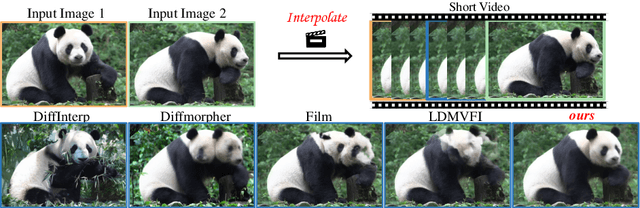
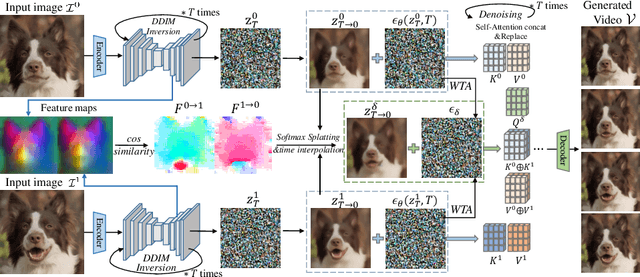
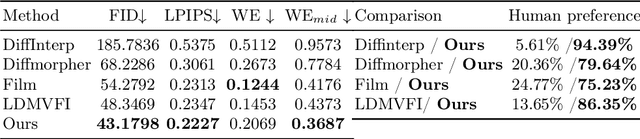

We study the problem of generating intermediate images from image pairs with large motion while maintaining semantic consistency. Due to the large motion, the intermediate semantic information may be absent in input images. Existing methods either limit to small motion or focus on topologically similar objects, leading to artifacts and inconsistency in the interpolation results. To overcome this challenge, we delve into pre-trained image diffusion models for their capabilities in semantic cognition and representations, ensuring consistent expression of the absent intermediate semantic representations with the input. To this end, we propose DreamMover, a novel image interpolation framework with three main components: 1) A natural flow estimator based on the diffusion model that can implicitly reason about the semantic correspondence between two images. 2) To avoid the loss of detailed information during fusion, our key insight is to fuse information in two parts, high-level space and low-level space. 3) To enhance the consistency between the generated images and input, we propose the self-attention concatenation and replacement approach. Lastly, we present a challenging benchmark dataset InterpBench to evaluate the semantic consistency of generated results. Extensive experiments demonstrate the effectiveness of our method. Our project is available at https://dreamm0ver.github.io .
Robust 3D Face Alignment with Multi-Path Neural Architecture Search
Jun 12, 20243D face alignment is a very challenging and fundamental problem in computer vision. Existing deep learning-based methods manually design different networks to regress either parameters of a 3D face model or 3D positions of face vertices. However, designing such networks relies on expert knowledge, and these methods often struggle to produce consistent results across various face poses. To address this limitation, we employ Neural Architecture Search (NAS) to automatically discover the optimal architecture for 3D face alignment. We propose a novel Multi-path One-shot Neural Architecture Search (MONAS) framework that leverages multi-scale features and contextual information to enhance face alignment across various poses. The MONAS comprises two key algorithms: Multi-path Networks Unbiased Sampling Based Training and Simulated Annealing based Multi-path One-shot Search. Experimental results on three popular benchmarks demonstrate the superior performance of the MONAS for both sparse alignment and dense alignment.
3D Multi-frame Fusion for Video Stabilization
Apr 19, 2024
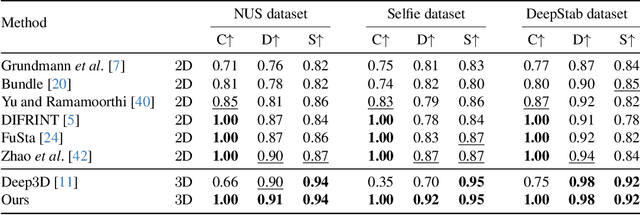
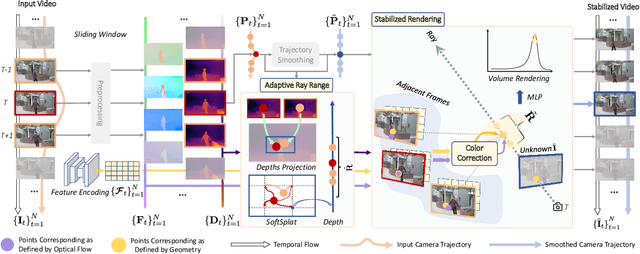

In this paper, we present RStab, a novel framework for video stabilization that integrates 3D multi-frame fusion through volume rendering. Departing from conventional methods, we introduce a 3D multi-frame perspective to generate stabilized images, addressing the challenge of full-frame generation while preserving structure. The core of our approach lies in Stabilized Rendering (SR), a volume rendering module, which extends beyond the image fusion by incorporating feature fusion. The core of our RStab framework lies in Stabilized Rendering (SR), a volume rendering module, fusing multi-frame information in 3D space. Specifically, SR involves warping features and colors from multiple frames by projection, fusing them into descriptors to render the stabilized image. However, the precision of warped information depends on the projection accuracy, a factor significantly influenced by dynamic regions. In response, we introduce the Adaptive Ray Range (ARR) module to integrate depth priors, adaptively defining the sampling range for the projection process. Additionally, we propose Color Correction (CC) assisting geometric constraints with optical flow for accurate color aggregation. Thanks to the three modules, our RStab demonstrates superior performance compared with previous stabilizers in the field of view (FOV), image quality, and video stability across various datasets.
Continuous Spiking Graph Neural Networks
Apr 02, 2024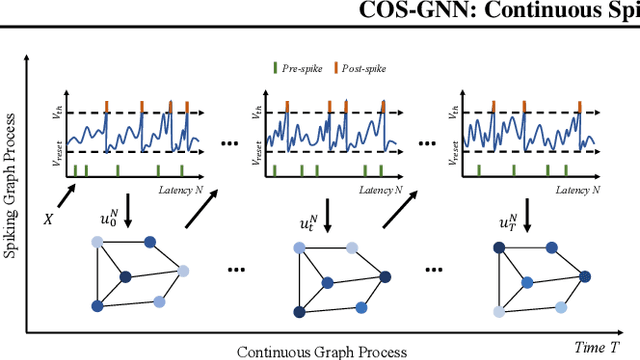
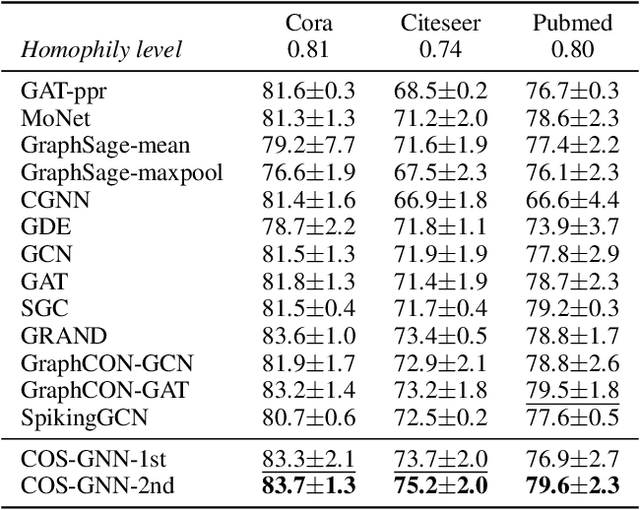
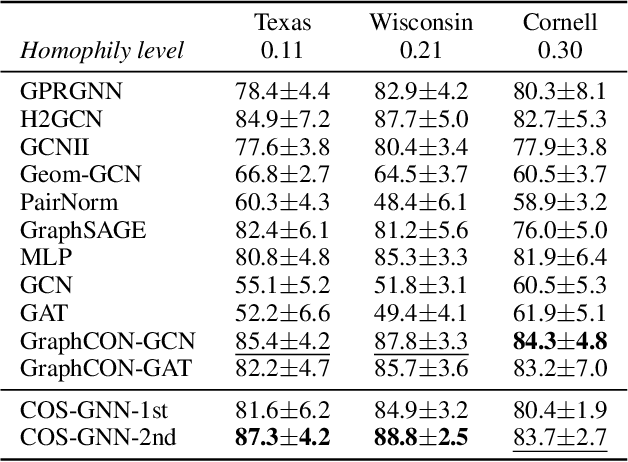
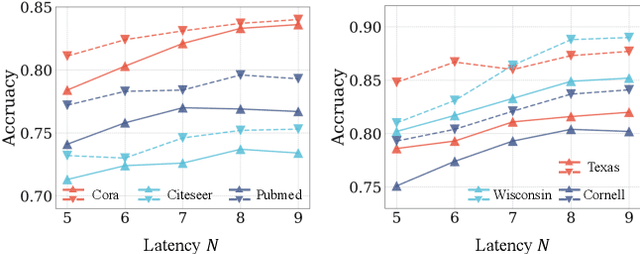
Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.
Enhanced Sparsification via Stimulative Training
Mar 11, 2024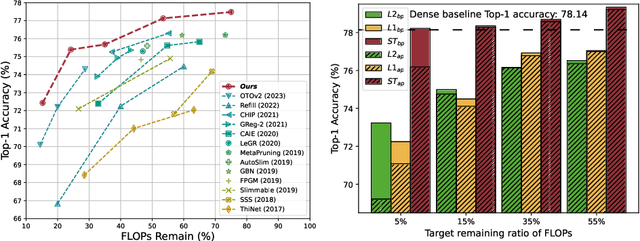

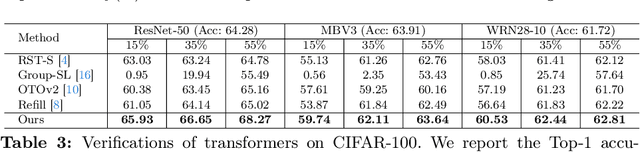
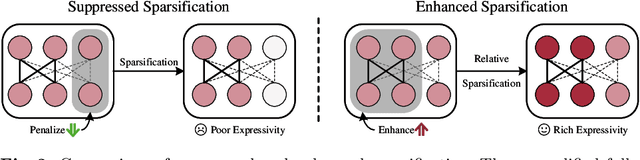
Sparsification-based pruning has been an important category in model compression. Existing methods commonly set sparsity-inducing penalty terms to suppress the importance of dropped weights, which is regarded as the suppressed sparsification paradigm. However, this paradigm inactivates the dropped parts of networks causing capacity damage before pruning, thereby leading to performance degradation. To alleviate this issue, we first study and reveal the relative sparsity effect in emerging stimulative training and then propose a structured pruning framework, named STP, based on an enhanced sparsification paradigm which maintains the magnitude of dropped weights and enhances the expressivity of kept weights by self-distillation. Besides, to find an optimal architecture for the pruned network, we propose a multi-dimension architecture space and a knowledge distillation-guided exploration strategy. To reduce the huge capacity gap of distillation, we propose a subnet mutating expansion technique. Extensive experiments on various benchmarks indicate the effectiveness of STP. Specifically, without fine-tuning, our method consistently achieves superior performance at different budgets, especially under extremely aggressive pruning scenarios, e.g., remaining 95.11% Top-1 accuracy (72.43% in 76.15%) while reducing 85% FLOPs for ResNet-50 on ImageNet. Codes will be released soon.
Rethinking of Feature Interaction for Multi-task Learning on Dense Prediction
Dec 21, 2023



Existing works generally adopt the encoder-decoder structure for Multi-task Dense Prediction, where the encoder extracts the task-generic features, and multiple decoders generate task-specific features for predictions. We observe that low-level representations with rich details and high-level representations with abundant task information are not both involved in the multi-task interaction process. Additionally, low-quality and low-efficiency issues also exist in current multi-task learning architectures. In this work, we propose to learn a comprehensive intermediate feature globally from both task-generic and task-specific features, we reveal an important fact that this intermediate feature, namely the bridge feature, is a good solution to the above issues. Based on this, we propose a novel Bridge-Feature-Centirc Interaction (BRFI) method. A Bridge Feature Extractor (BFE) is designed for the generation of strong bridge features and Task Pattern Propagation (TPP) is applied to ensure high-quality task interaction participants. Then a Task-Feature Refiner (TFR) is developed to refine final task predictions with the well-learned knowledge from the bridge features. Extensive experiments are conducted on NYUD-v2 and PASCAL Context benchmarks, and the superior performance shows the proposed architecture is effective and powerful in promoting different dense prediction tasks simultaneously.
Efficient Architecture Search via Bi-level Data Pruning
Dec 21, 2023Improving the efficiency of Neural Architecture Search (NAS) is a challenging but significant task that has received much attention. Previous works mainly adopted the Differentiable Architecture Search (DARTS) and improved its search strategies or modules to enhance search efficiency. Recently, some methods have started considering data reduction for speedup, but they are not tightly coupled with the architecture search process, resulting in sub-optimal performance. To this end, this work pioneers an exploration into the critical role of dataset characteristics for DARTS bi-level optimization, and then proposes a novel Bi-level Data Pruning (BDP) paradigm that targets the weights and architecture levels of DARTS to enhance efficiency from a data perspective. Specifically, we introduce a new progressive data pruning strategy that utilizes supernet prediction dynamics as the metric, to gradually prune unsuitable samples for DARTS during the search. An effective automatic class balance constraint is also integrated into BDP, to suppress potential class imbalances resulting from data-efficient algorithms. Comprehensive evaluations on the NAS-Bench-201 search space, DARTS search space, and MobileNet-like search space validate that BDP reduces search costs by over 50% while achieving superior performance when applied to baseline DARTS. Besides, we demonstrate that BDP can harmoniously integrate with advanced DARTS variants, like PC-DARTS and \b{eta}-DARTS, offering an approximately 2 times speedup with minimal performance compromises.
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023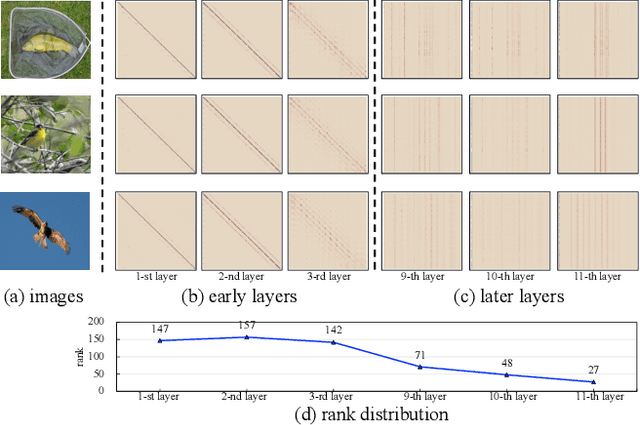
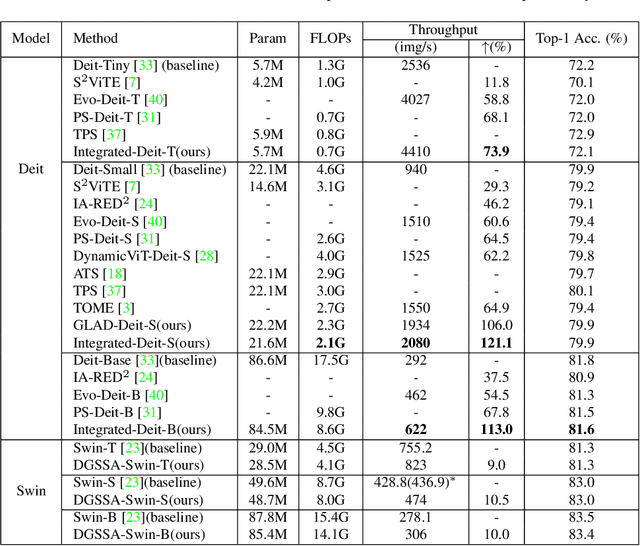
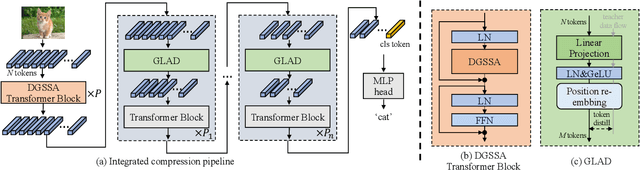
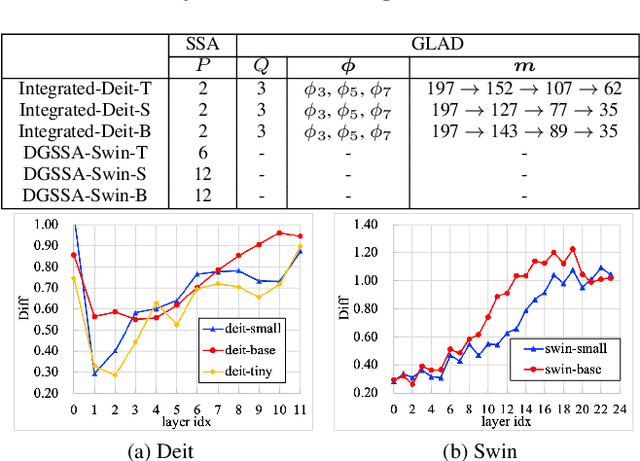
Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.
Rethinking Cross-Domain Pedestrian Detection: A Background-Focused Distribution Alignment Framework for Instance-Free One-Stage Detectors
Sep 15, 2023



Cross-domain pedestrian detection aims to generalize pedestrian detectors from one label-rich domain to another label-scarce domain, which is crucial for various real-world applications. Most recent works focus on domain alignment to train domain-adaptive detectors either at the instance level or image level. From a practical point of view, one-stage detectors are faster. Therefore, we concentrate on designing a cross-domain algorithm for rapid one-stage detectors that lacks instance-level proposals and can only perform image-level feature alignment. However, pure image-level feature alignment causes the foreground-background misalignment issue to arise, i.e., the foreground features in the source domain image are falsely aligned with background features in the target domain image. To address this issue, we systematically analyze the importance of foreground and background in image-level cross-domain alignment, and learn that background plays a more critical role in image-level cross-domain alignment. Therefore, we focus on cross-domain background feature alignment while minimizing the influence of foreground features on the cross-domain alignment stage. This paper proposes a novel framework, namely, background-focused distribution alignment (BFDA), to train domain adaptive onestage pedestrian detectors. Specifically, BFDA first decouples the background features from the whole image feature maps and then aligns them via a novel long-short-range discriminator.
* This paper published on IEEE Transactions on Image Processing on August 2023.See https://ieeexplore.ieee.org/document/10231122