 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust 3D Face Alignment with Multi-Path Neural Architecture Search
Jun 12, 20243D face alignment is a very challenging and fundamental problem in computer vision. Existing deep learning-based methods manually design different networks to regress either parameters of a 3D face model or 3D positions of face vertices. However, designing such networks relies on expert knowledge, and these methods often struggle to produce consistent results across various face poses. To address this limitation, we employ Neural Architecture Search (NAS) to automatically discover the optimal architecture for 3D face alignment. We propose a novel Multi-path One-shot Neural Architecture Search (MONAS) framework that leverages multi-scale features and contextual information to enhance face alignment across various poses. The MONAS comprises two key algorithms: Multi-path Networks Unbiased Sampling Based Training and Simulated Annealing based Multi-path One-shot Search. Experimental results on three popular benchmarks demonstrate the superior performance of the MONAS for both sparse alignment and dense alignment.
Does AI help humans make better decisions? A methodological framework for experimental evaluation
Mar 18, 2024The use of Artificial Intelligence (AI) based on data-driven algorithms has become ubiquitous in today's society. Yet, in many cases and especially when stakes are high, humans still make final decisions. The critical question, therefore, is whether AI helps humans make better decisions as compared to a human alone or AI an alone. We introduce a new methodological framework that can be used to answer experimentally this question with no additional assumptions. We measure a decision maker's ability to make correct decisions using standard classification metrics based on the baseline potential outcome. We consider a single-blinded experimental design, in which the provision of AI-generated recommendations is randomized across cases with a human making final decisions. Under this experimental design, we show how to compare the performance of three alternative decision-making systems--human-alone, human-with-AI, and AI-alone. We apply the proposed methodology to the data from our own randomized controlled trial of a pretrial risk assessment instrument. We find that AI recommendations do not improve the classification accuracy of a judge's decision to impose cash bail. Our analysis also shows that AI-alone decisions generally perform worse than human decisions with or without AI assistance. Finally, AI recommendations tend to impose cash bail on non-white arrestees more often than necessary when compared to white arrestees.
Policy learning with asymmetric utilities
Jun 21, 2022
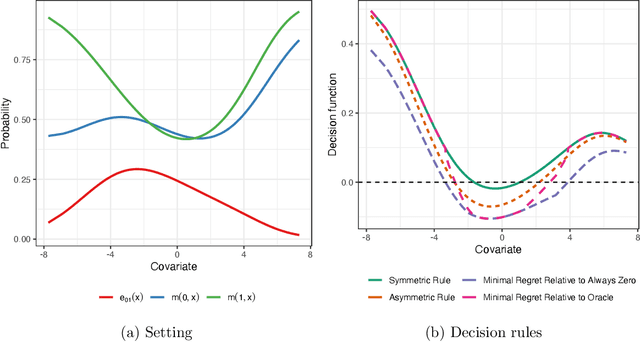

Data-driven decision making plays an important role even in high stakes settings like medicine and public policy. Learning optimal policies from observed data requires a careful formulation of the utility function whose expected value is maximized across a population. Although researchers typically use utilities that depend on observed outcomes alone, in many settings the decision maker's utility function is more properly characterized by the joint set of potential outcomes under all actions. For example, the Hippocratic principle to ``do no harm'' implies that the cost of causing death to a patient who would otherwise survive without treatment is greater than the cost of forgoing life-saving treatment. We consider optimal policy learning with asymmetric utility functions of this form. We show that asymmetric utilities lead to an unidentifiable social welfare function, and so we first partially identify it. Drawing on statistical decision theory, we then derive minimax decision rules by minimizing the maximum regret relative to alternative policies. We show that one can learn minimax decision rules from observed data by solving intermediate classification problems. We also establish that the finite sample regret of this procedure is bounded by the mis-classification rate of these intermediate classifiers. We apply this conceptual framework and methodology to the decision about whether or not to use right heart catheterization for patients with possible pulmonary hypertension.
Safe Policy Learning through Extrapolation: Application to Pre-trial Risk Assessment
Sep 22, 2021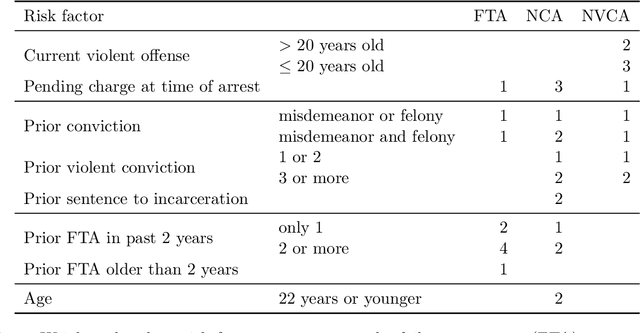
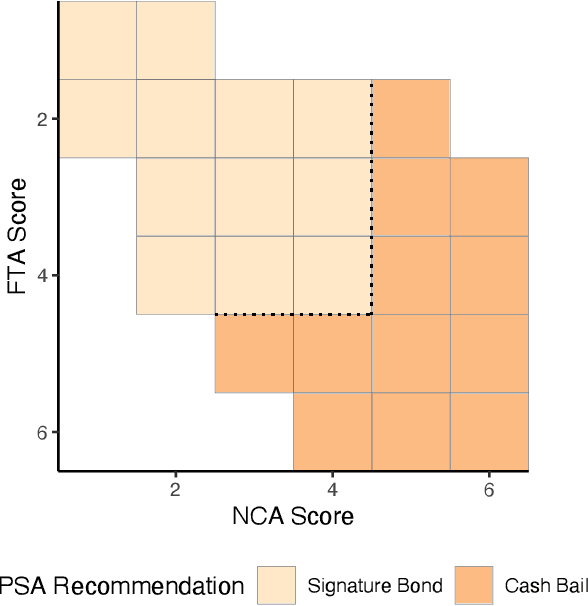

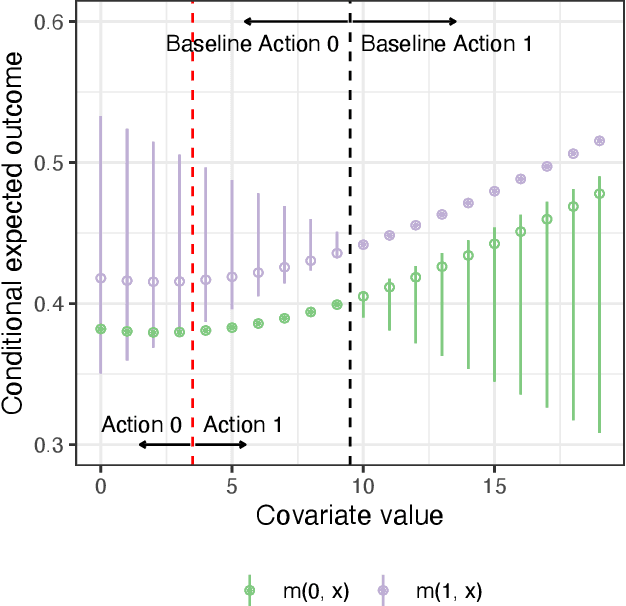
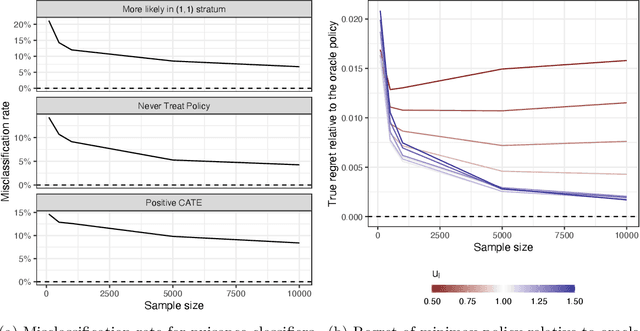
Algorithmic recommendations and decisions have become ubiquitous in today's society. Many of these and other data-driven policies are based on known, deterministic rules to ensure their transparency and interpretability. This is especially true when such policies are used for public policy decision-making. For example, algorithmic pre-trial risk assessments, which serve as our motivating application, provide relatively simple, deterministic classification scores and recommendations to help judges make release decisions. Unfortunately, existing methods for policy learning are not applicable because they require existing policies to be stochastic rather than deterministic. We develop a robust optimization approach that partially identifies the expected utility of a policy, and then finds an optimal policy by minimizing the worst-case regret. The resulting policy is conservative but has a statistical safety guarantee, allowing the policy-maker to limit the probability of producing a worse outcome than the existing policy. We extend this approach to common and important settings where humans make decisions with the aid of algorithmic recommendations. Lastly, we apply the proposed methodology to a unique field experiment on pre-trial risk assessments. We derive new classification and recommendation rules that retain the transparency and interpretability of the existing risk assessment instrument while potentially leading to better overall outcomes at a lower cost.
PURS: Personalized Unexpected Recommender System for Improving User Satisfaction
Jun 05, 2021
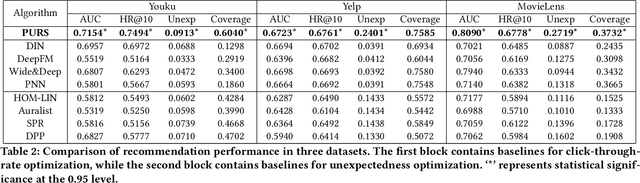
Classical recommender system methods typically face the filter bubble problem when users only receive recommendations of their familiar items, making them bored and dissatisfied. To address the filter bubble problem, unexpected recommendations have been proposed to recommend items significantly deviating from user's prior expectations and thus surprising them by presenting "fresh" and previously unexplored items to the users. In this paper, we describe a novel Personalized Unexpected Recommender System (PURS) model that incorporates unexpectedness into the recommendation process by providing multi-cluster modeling of user interests in the latent space and personalized unexpectedness via the self-attention mechanism and via selection of an appropriate unexpected activation function. Extensive offline experiments on three real-world datasets illustrate that the proposed PURS model significantly outperforms the state-of-the-art baseline approaches in terms of both accuracy and unexpectedness measures. In addition, we conduct an online A/B test at a major video platform Alibaba-Youku, where our model achieves over 3\% increase in the average video view per user metric. The proposed model is in the process of being deployed by the company.
Dual Attentive Sequential Learning for Cross-Domain Click-Through Rate Prediction
Jun 05, 2021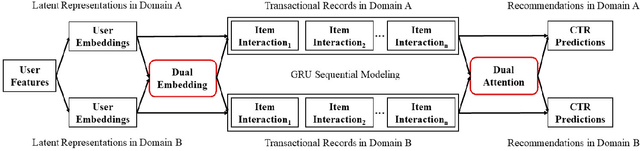
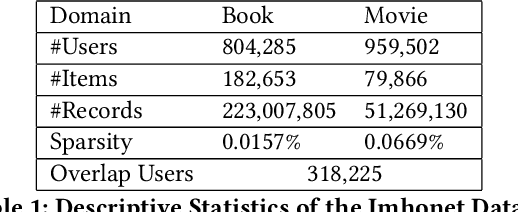
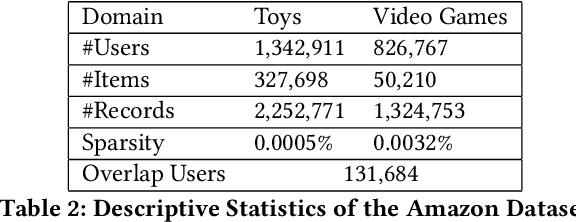
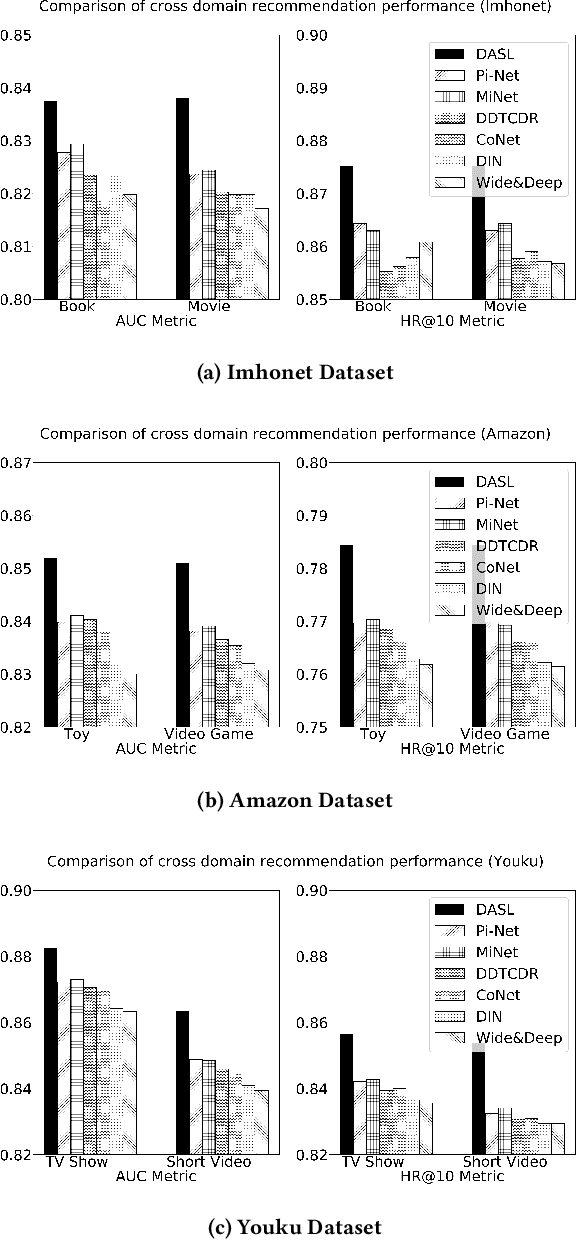
Cross domain recommender system constitutes a powerful method to tackle the cold-start and sparsity problem by aggregating and transferring user preferences across multiple category domains. Therefore, it has great potential to improve click-through-rate prediction performance in online commerce platforms having many domains of products. While several cross domain sequential recommendation models have been proposed to leverage information from a source domain to improve CTR predictions in a target domain, they did not take into account bidirectional latent relations of user preferences across source-target domain pairs. As such, they cannot provide enhanced cross-domain CTR predictions for both domains simultaneously. In this paper, we propose a novel approach to cross-domain sequential recommendations based on the dual learning mechanism that simultaneously transfers information between two related domains in an iterative manner until the learning process stabilizes. In particular, the proposed Dual Attentive Sequential Learning (DASL) model consists of two novel components Dual Embedding and Dual Attention, which jointly establish the two-stage learning process: we first construct dual latent embeddings that extract user preferences in both domains simultaneously, and subsequently provide cross-domain recommendations by matching the extracted latent embeddings with candidate items through dual-attention learning mechanism. We conduct extensive offline experiments on three real-world datasets to demonstrate the superiority of our proposed model, which significantly and consistently outperforms several state-of-the-art baselines across all experimental settings. We also conduct an online A/B test at a major video streaming platform Alibaba-Youku, where our proposed model significantly improves business performance over the latest production system in the company.
Principal Fairness for Human and Algorithmic Decision-Making
Jun 13, 2020

Using the concept of principal stratification from the causal inference literature, we introduce a new notion of fairness, called principal fairness, for human and algorithmic decision-making. The key idea is that one should not discriminate among individuals who would be similarly affected by the decision. Unlike the existing statistical definitions of fairness, principal fairness explicitly accounts for the fact that individuals can be influenced by the decision. We motivate principal fairness by the belief that all people are created equal, implying that the potential outcomes should not depend on protected attributes such as race and gender once we adjust for relevant covariates. Under this assumption, we show that principal fairness implies all three existing statistical fairness criteria, thereby resolving the previously recognized tradeoffs between them. Finally, we discuss how to empirically evaluate the principal fairness of a particular decision.
Discussion of "The Blessings of Multiple Causes" by Wang and Blei
Oct 15, 2019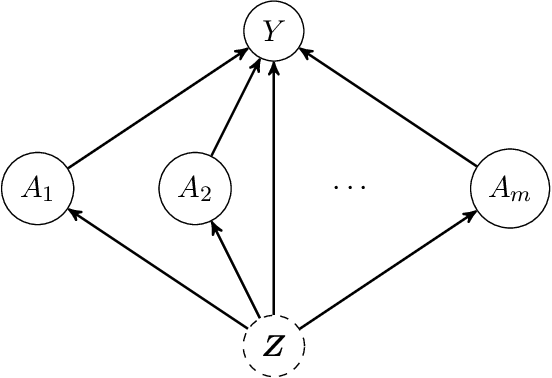



This commentary has two goals. We first critically review the deconfounder method and point out its advantages and limitations. We then briefly consider three possible ways to address some of the limitations of the deconfounder method.