 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Minimax Regret Estimation for Generalizing Heterogeneous Treatment Effects with Multisite Data
Dec 15, 2024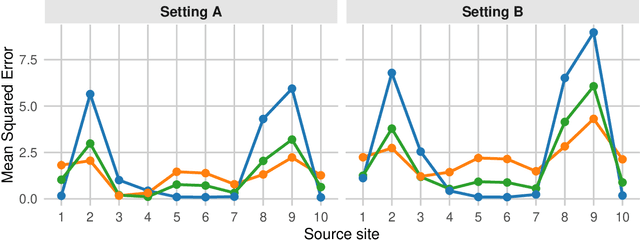



To test scientific theories and develop individualized treatment rules, researchers often wish to learn heterogeneous treatment effects that can be consistently found across diverse populations and contexts. We consider the problem of generalizing heterogeneous treatment effects (HTE) based on data from multiple sites. A key challenge is that a target population may differ from the source sites in unknown and unobservable ways. This means that the estimates from site-specific models lack external validity, and a simple pooled analysis risks bias. We develop a robust CATE (conditional average treatment effect) estimation methodology with multisite data from heterogeneous populations. We propose a minimax-regret framework that learns a generalizable CATE model by minimizing the worst-case regret over a class of target populations whose CATE can be represented as convex combinations of site-specific CATEs. Using robust optimization, the proposed methodology accounts for distribution shifts in both individual covariates and treatment effect heterogeneity across sites. We show that the resulting CATE model has an interpretable closed-form solution, expressed as a weighted average of site-specific CATE models. Thus, researchers can utilize a flexible CATE estimation method within each site and aggregate site-specific estimates to produce the final model. Through simulations and a real-world application, we show that the proposed methodology improves the robustness and generalizability of existing approaches.
Does AI help humans make better decisions? A methodological framework for experimental evaluation
Mar 18, 2024The use of Artificial Intelligence (AI) based on data-driven algorithms has become ubiquitous in today's society. Yet, in many cases and especially when stakes are high, humans still make final decisions. The critical question, therefore, is whether AI helps humans make better decisions as compared to a human alone or AI an alone. We introduce a new methodological framework that can be used to answer experimentally this question with no additional assumptions. We measure a decision maker's ability to make correct decisions using standard classification metrics based on the baseline potential outcome. We consider a single-blinded experimental design, in which the provision of AI-generated recommendations is randomized across cases with a human making final decisions. Under this experimental design, we show how to compare the performance of three alternative decision-making systems--human-alone, human-with-AI, and AI-alone. We apply the proposed methodology to the data from our own randomized controlled trial of a pretrial risk assessment instrument. We find that AI recommendations do not improve the classification accuracy of a judge's decision to impose cash bail. Our analysis also shows that AI-alone decisions generally perform worse than human decisions with or without AI assistance. Finally, AI recommendations tend to impose cash bail on non-white arrestees more often than necessary when compared to white arrestees.