 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmitted Variable Bias in Language Models Under Distribution Shift
Feb 18, 2026Despite their impressive performance on a wide variety of tasks, modern language models remain susceptible to distribution shifts, exhibiting brittle behavior when evaluated on data that differs in distribution from their training data. In this paper, we describe how distribution shifts in language models can be separated into observable and unobservable components, and we discuss how established approaches for dealing with distribution shift address only the former. Importantly, we identify that the resulting omitted variable bias from unobserved variables can compromise both evaluation and optimization in language models. To address this challenge, we introduce a framework that maps the strength of the omitted variables to bounds on the worst-case generalization performance of language models under distribution shift. In empirical experiments, we show that using these bounds directly in language model evaluation and optimization provides more principled measures of out-of-distribution performance, improves true out-of-distribution performance relative to standard distribution shift adjustment methods, and further enables inference about the strength of the omitted variables when target distribution labels are available.
Isolated Causal Effects of Natural Language
Oct 18, 2024



As language technologies become widespread, it is important to understand how variations in language affect reader perceptions -- formalized as the isolated causal effect of some focal language-encoded intervention on an external outcome. A core challenge of estimating isolated effects is the need to approximate all non-focal language outside of the intervention. In this paper, we introduce a formal estimation framework for isolated causal effects and explore how different approximations of non-focal language impact effect estimates. Drawing on the principle of omitted variable bias, we present metrics for evaluating the quality of isolated effect estimation and non-focal language approximation along the axes of fidelity and overlap. In experiments on semi-synthetic and real-world data, we validate the ability of our framework to recover ground truth isolated effects, and we demonstrate the utility of our proposed metrics as measures of quality for both isolated effect estimates and non-focal language approximations.
Does AI help humans make better decisions? A methodological framework for experimental evaluation
Mar 18, 2024The use of Artificial Intelligence (AI) based on data-driven algorithms has become ubiquitous in today's society. Yet, in many cases and especially when stakes are high, humans still make final decisions. The critical question, therefore, is whether AI helps humans make better decisions as compared to a human alone or AI an alone. We introduce a new methodological framework that can be used to answer experimentally this question with no additional assumptions. We measure a decision maker's ability to make correct decisions using standard classification metrics based on the baseline potential outcome. We consider a single-blinded experimental design, in which the provision of AI-generated recommendations is randomized across cases with a human making final decisions. Under this experimental design, we show how to compare the performance of three alternative decision-making systems--human-alone, human-with-AI, and AI-alone. We apply the proposed methodology to the data from our own randomized controlled trial of a pretrial risk assessment instrument. We find that AI recommendations do not improve the classification accuracy of a judge's decision to impose cash bail. Our analysis also shows that AI-alone decisions generally perform worse than human decisions with or without AI assistance. Finally, AI recommendations tend to impose cash bail on non-white arrestees more often than necessary when compared to white arrestees.
Optimizing Language Models for Human Preferences is a Causal Inference Problem
Feb 22, 2024



As large language models (LLMs) see greater use in academic and commercial settings, there is increasing interest in methods that allow language models to generate texts aligned with human preferences. In this paper, we present an initial exploration of language model optimization for human preferences from direct outcome datasets, where each sample consists of a text and an associated numerical outcome measuring the reader's response. We first propose that language model optimization should be viewed as a causal problem to ensure that the model correctly learns the relationship between the text and the outcome. We formalize this causal language optimization problem, and we develop a method--causal preference optimization (CPO)--that solves an unbiased surrogate objective for the problem. We further extend CPO with doubly robust CPO (DR-CPO), which reduces the variance of the surrogate objective while retaining provably strong guarantees on bias. Finally, we empirically demonstrate the effectiveness of (DR-)CPO in optimizing state-of-the-art LLMs for human preferences on direct outcome data, and we validate the robustness of DR-CPO under difficult confounding conditions.
Text-Transport: Toward Learning Causal Effects of Natural Language
Oct 31, 2023



As language technologies gain prominence in real-world settings, it is important to understand how changes to language affect reader perceptions. This can be formalized as the causal effect of varying a linguistic attribute (e.g., sentiment) on a reader's response to the text. In this paper, we introduce Text-Transport, a method for estimation of causal effects from natural language under any text distribution. Current approaches for valid causal effect estimation require strong assumptions about the data, meaning the data from which one can estimate valid causal effects often is not representative of the actual target domain of interest. To address this issue, we leverage the notion of distribution shift to describe an estimator that transports causal effects between domains, bypassing the need for strong assumptions in the target domain. We derive statistical guarantees on the uncertainty of this estimator, and we report empirical results and analyses that support the validity of Text-Transport across data settings. Finally, we use Text-Transport to study a realistic setting--hate speech on social media--in which causal effects do shift significantly between text domains, demonstrating the necessity of transport when conducting causal inference on natural language.
Bayesian Safe Policy Learning with Chance Constrained Optimization: Application to Military Security Assessment during the Vietnam War
Jul 17, 2023Algorithmic and data-driven decisions and recommendations are commonly used in high-stakes decision-making settings such as criminal justice, medicine, and public policy. We investigate whether it would have been possible to improve a security assessment algorithm employed during the Vietnam War, using outcomes measured immediately after its introduction in late 1969. This empirical application raises several methodological challenges that frequently arise in high-stakes algorithmic decision-making. First, before implementing a new algorithm, it is essential to characterize and control the risk of yielding worse outcomes than the existing algorithm. Second, the existing algorithm is deterministic, and learning a new algorithm requires transparent extrapolation. Third, the existing algorithm involves discrete decision tables that are common but difficult to optimize over. To address these challenges, we introduce the Average Conditional Risk (ACRisk), which first quantifies the risk that a new algorithmic policy leads to worse outcomes for subgroups of individual units and then averages this over the distribution of subgroups. We also propose a Bayesian policy learning framework that maximizes the posterior expected value while controlling the posterior expected ACRisk. This framework separates the estimation of heterogeneous treatment effects from policy optimization, enabling flexible estimation of effects and optimization over complex policy classes. We characterize the resulting chance-constrained optimization problem as a constrained linear programming problem. Our analysis shows that compared to the actual algorithm used during the Vietnam War, the learned algorithm assesses most regions as more secure and emphasizes economic and political factors over military factors.
Policy learning with asymmetric utilities
Jun 21, 2022
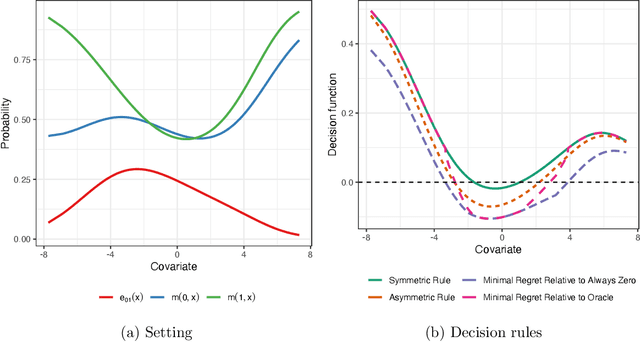

Data-driven decision making plays an important role even in high stakes settings like medicine and public policy. Learning optimal policies from observed data requires a careful formulation of the utility function whose expected value is maximized across a population. Although researchers typically use utilities that depend on observed outcomes alone, in many settings the decision maker's utility function is more properly characterized by the joint set of potential outcomes under all actions. For example, the Hippocratic principle to ``do no harm'' implies that the cost of causing death to a patient who would otherwise survive without treatment is greater than the cost of forgoing life-saving treatment. We consider optimal policy learning with asymmetric utility functions of this form. We show that asymmetric utilities lead to an unidentifiable social welfare function, and so we first partially identify it. Drawing on statistical decision theory, we then derive minimax decision rules by minimizing the maximum regret relative to alternative policies. We show that one can learn minimax decision rules from observed data by solving intermediate classification problems. We also establish that the finite sample regret of this procedure is bounded by the mis-classification rate of these intermediate classifiers. We apply this conceptual framework and methodology to the decision about whether or not to use right heart catheterization for patients with possible pulmonary hypertension.
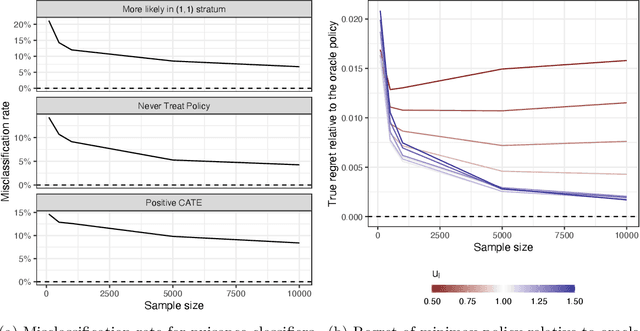
Safe Policy Learning through Extrapolation: Application to Pre-trial Risk Assessment
Sep 22, 2021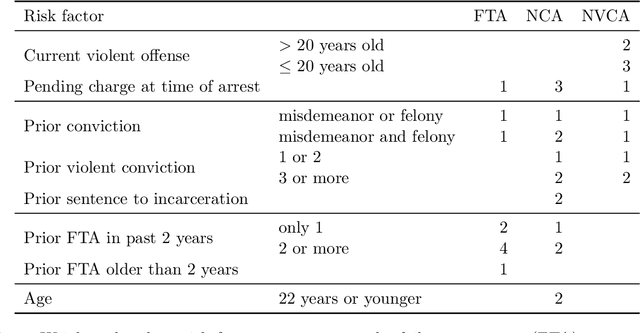
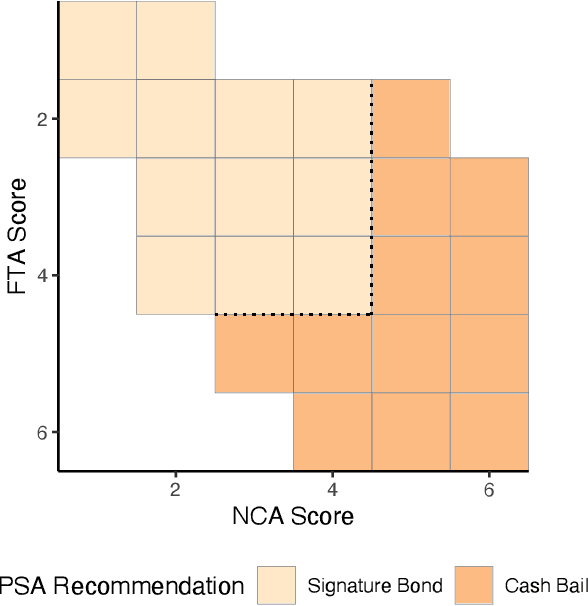

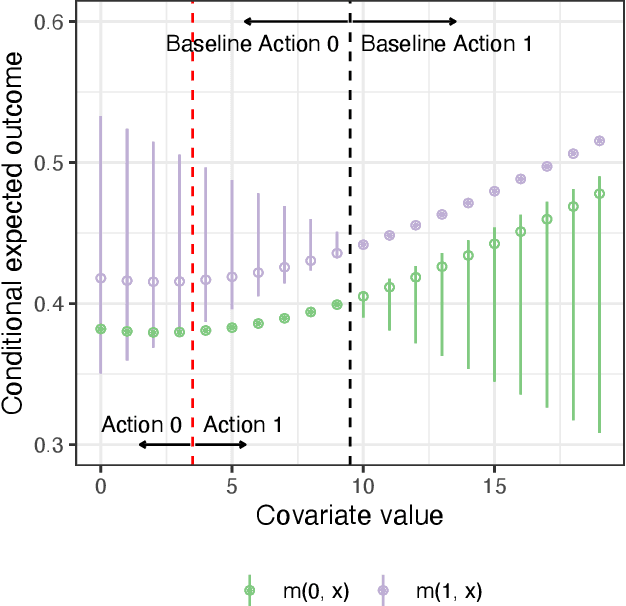
Algorithmic recommendations and decisions have become ubiquitous in today's society. Many of these and other data-driven policies are based on known, deterministic rules to ensure their transparency and interpretability. This is especially true when such policies are used for public policy decision-making. For example, algorithmic pre-trial risk assessments, which serve as our motivating application, provide relatively simple, deterministic classification scores and recommendations to help judges make release decisions. Unfortunately, existing methods for policy learning are not applicable because they require existing policies to be stochastic rather than deterministic. We develop a robust optimization approach that partially identifies the expected utility of a policy, and then finds an optimal policy by minimizing the worst-case regret. The resulting policy is conservative but has a statistical safety guarantee, allowing the policy-maker to limit the probability of producing a worse outcome than the existing policy. We extend this approach to common and important settings where humans make decisions with the aid of algorithmic recommendations. Lastly, we apply the proposed methodology to a unique field experiment on pre-trial risk assessments. We derive new classification and recommendation rules that retain the transparency and interpretability of the existing risk assessment instrument while potentially leading to better overall outcomes at a lower cost.