 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
May 20, 2026Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions, potentially distorting effect estimates. We formalize the confounding or selection bias that can arise due to user drift and show how intervention-dependent shifts can inflate or attenuate observed differences in user responses under intervention. To diagnose confounding, we propose using negative control outcomes--attributes that should remain invariant under intervention--to identify distribution shifts across intervention conditions, providing evidence of user drift. To mitigate drift, we study adjusting the persona specification by eliciting additional confounders, finding that targeted, setting-relevant confounders can substantially reduce bias across survey-style and multi-turn agent evaluations.
Omitted Variable Bias in Language Models Under Distribution Shift
Feb 18, 2026Despite their impressive performance on a wide variety of tasks, modern language models remain susceptible to distribution shifts, exhibiting brittle behavior when evaluated on data that differs in distribution from their training data. In this paper, we describe how distribution shifts in language models can be separated into observable and unobservable components, and we discuss how established approaches for dealing with distribution shift address only the former. Importantly, we identify that the resulting omitted variable bias from unobserved variables can compromise both evaluation and optimization in language models. To address this challenge, we introduce a framework that maps the strength of the omitted variables to bounds on the worst-case generalization performance of language models under distribution shift. In empirical experiments, we show that using these bounds directly in language model evaluation and optimization provides more principled measures of out-of-distribution performance, improves true out-of-distribution performance relative to standard distribution shift adjustment methods, and further enables inference about the strength of the omitted variables when target distribution labels are available.
Better Think Thrice: Learning to Reason Causally with Double Counterfactual Consistency
Feb 18, 2026Despite their strong performance on reasoning benchmarks, large language models (LLMs) have proven brittle when presented with counterfactual questions, suggesting weaknesses in their causal reasoning ability. While recent work has demonstrated that labeled counterfactual tasks can be useful benchmarks of LLMs' causal reasoning, producing such data at the scale required to cover the vast potential space of counterfactuals is limited. In this work, we introduce double counterfactual consistency (DCC), a lightweight inference-time method for measuring and guiding the ability of LLMs to reason causally. Without requiring labeled counterfactual data, DCC verifies a model's ability to execute two important elements of causal reasoning: causal intervention and counterfactual prediction. Using DCC, we evaluate the causal reasoning abilities of various leading LLMs across a range of reasoning tasks and interventions. Moreover, we demonstrate the effectiveness of DCC as a training-free test-time rejection sampling criterion and show that it can directly improve performance on reasoning tasks across multiple model families.
Isolated Causal Effects of Natural Language
Oct 18, 2024



As language technologies become widespread, it is important to understand how variations in language affect reader perceptions -- formalized as the isolated causal effect of some focal language-encoded intervention on an external outcome. A core challenge of estimating isolated effects is the need to approximate all non-focal language outside of the intervention. In this paper, we introduce a formal estimation framework for isolated causal effects and explore how different approximations of non-focal language impact effect estimates. Drawing on the principle of omitted variable bias, we present metrics for evaluating the quality of isolated effect estimation and non-focal language approximation along the axes of fidelity and overlap. In experiments on semi-synthetic and real-world data, we validate the ability of our framework to recover ground truth isolated effects, and we demonstrate the utility of our proposed metrics as measures of quality for both isolated effect estimates and non-focal language approximations.
Sirius: Contextual Sparsity with Correction for Efficient LLMs
Sep 05, 2024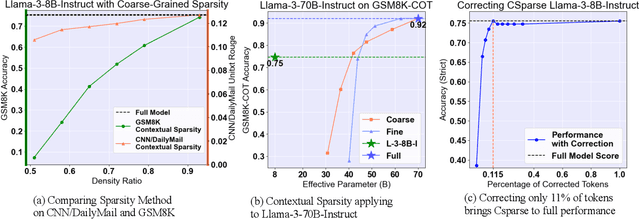
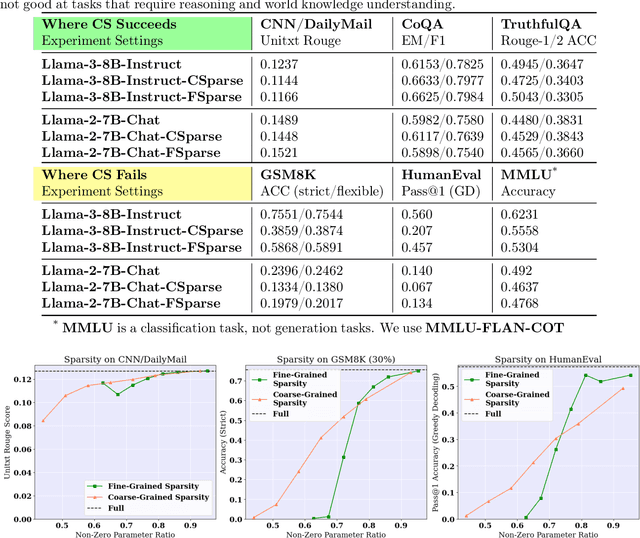


With the blossom of large language models (LLMs), inference efficiency becomes increasingly important. Various approximation methods are proposed to reduce the cost at inference time. Contextual Sparsity (CS) is appealing for its training-free nature and its ability to reach a higher compression ratio seemingly without quality degradation. However, after a comprehensive evaluation of contextual sparsity methods on various complex generation tasks, we find that although CS succeeds in prompt-understanding tasks, CS significantly degrades the model performance for reasoning, deduction, and knowledge-based tasks. Despite the gap in end-to-end accuracy, we observed that sparse models often share general problem-solving logic and require only a few token corrections to recover the original model performance. This paper introduces Sirius, an efficient correction mechanism, which significantly recovers CS models quality on reasoning tasks while maintaining its efficiency gain. Sirius is evaluated on 6 models with 8 difficult generation tasks in reasoning, math, and coding and shows consistent effectiveness and efficiency. Also, we carefully develop a system implementation for Sirius and show that Sirius achieves roughly 20% reduction in latency for 8B model on-chip and 35% reduction for 70B model offloading. We open-source our implementation of Sirius at https://github.com/Infini-AI-Lab/Sirius.git.
Optimizing Language Models for Human Preferences is a Causal Inference Problem
Feb 22, 2024



As large language models (LLMs) see greater use in academic and commercial settings, there is increasing interest in methods that allow language models to generate texts aligned with human preferences. In this paper, we present an initial exploration of language model optimization for human preferences from direct outcome datasets, where each sample consists of a text and an associated numerical outcome measuring the reader's response. We first propose that language model optimization should be viewed as a causal problem to ensure that the model correctly learns the relationship between the text and the outcome. We formalize this causal language optimization problem, and we develop a method--causal preference optimization (CPO)--that solves an unbiased surrogate objective for the problem. We further extend CPO with doubly robust CPO (DR-CPO), which reduces the variance of the surrogate objective while retaining provably strong guarantees on bias. Finally, we empirically demonstrate the effectiveness of (DR-)CPO in optimizing state-of-the-art LLMs for human preferences on direct outcome data, and we validate the robustness of DR-CPO under difficult confounding conditions.
Text-Transport: Toward Learning Causal Effects of Natural Language
Oct 31, 2023



As language technologies gain prominence in real-world settings, it is important to understand how changes to language affect reader perceptions. This can be formalized as the causal effect of varying a linguistic attribute (e.g., sentiment) on a reader's response to the text. In this paper, we introduce Text-Transport, a method for estimation of causal effects from natural language under any text distribution. Current approaches for valid causal effect estimation require strong assumptions about the data, meaning the data from which one can estimate valid causal effects often is not representative of the actual target domain of interest. To address this issue, we leverage the notion of distribution shift to describe an estimator that transports causal effects between domains, bypassing the need for strong assumptions in the target domain. We derive statistical guarantees on the uncertainty of this estimator, and we report empirical results and analyses that support the validity of Text-Transport across data settings. Finally, we use Text-Transport to study a realistic setting--hate speech on social media--in which causal effects do shift significantly between text domains, demonstrating the necessity of transport when conducting causal inference on natural language.
SenteCon: Leveraging Lexicons to Learn Human-Interpretable Language Representations
May 24, 2023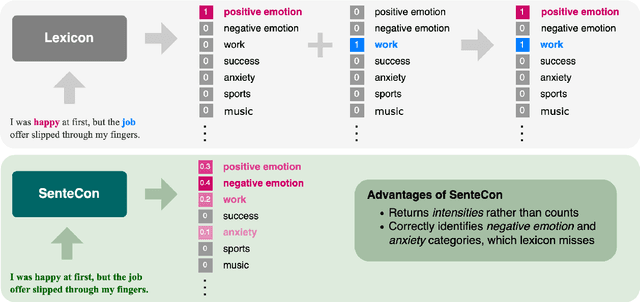
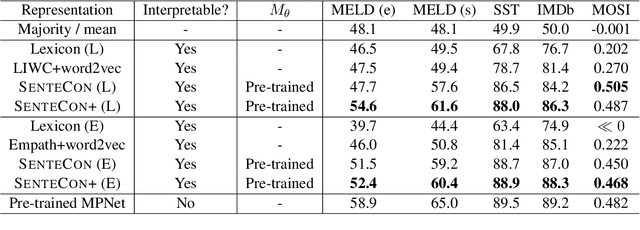
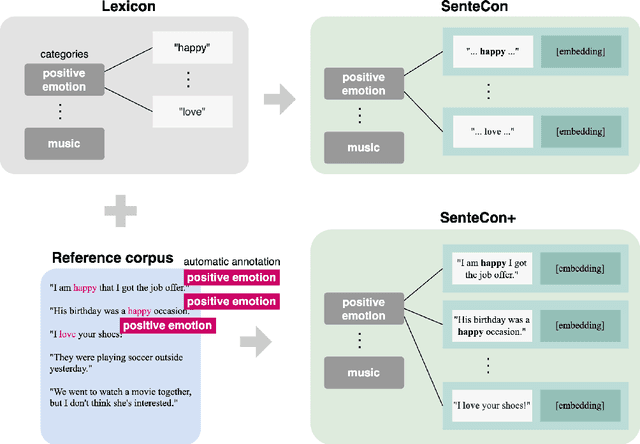
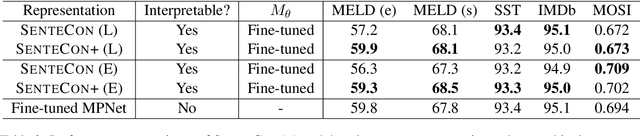
Although deep language representations have become the dominant form of language featurization in recent years, in many settings it is important to understand a model's decision-making process. This necessitates not only an interpretable model but also interpretable features. In particular, language must be featurized in a way that is interpretable while still characterizing the original text well. We present SenteCon, a method for introducing human interpretability in deep language representations. Given a passage of text, SenteCon encodes the text as a layer of interpretable categories in which each dimension corresponds to the relevance of a specific category. Our empirical evaluations indicate that encoding language with SenteCon provides high-level interpretability at little to no cost to predictive performance on downstream tasks. Moreover, we find that SenteCon outperforms existing interpretable language representations with respect to both its downstream performance and its agreement with human characterizations of the text.
Counterfactual Augmentation for Multimodal Learning Under Presentation Bias
May 23, 2023In real-world machine learning systems, labels are often derived from user behaviors that the system wishes to encourage. Over time, new models must be trained as new training examples and features become available. However, feedback loops between users and models can bias future user behavior, inducing a presentation bias in the labels that compromises the ability to train new models. In this paper, we propose counterfactual augmentation, a novel causal method for correcting presentation bias using generated counterfactual labels. Our empirical evaluations demonstrate that counterfactual augmentation yields better downstream performance compared to both uncorrected models and existing bias-correction methods. Model analyses further indicate that the generated counterfactuals align closely with true counterfactuals in an oracle setting.
SeedBERT: Recovering Annotator Rating Distributions from an Aggregated Label
Nov 23, 2022


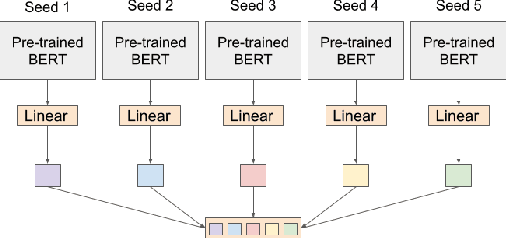
Many machine learning tasks -- particularly those in affective computing -- are inherently subjective. When asked to classify facial expressions or to rate an individual's attractiveness, humans may disagree with one another, and no single answer may be objectively correct. However, machine learning datasets commonly have just one "ground truth" label for each sample, so models trained on these labels may not perform well on tasks that are subjective in nature. Though allowing models to learn from the individual annotators' ratings may help, most datasets do not provide annotator-specific labels for each sample. To address this issue, we propose SeedBERT, a method for recovering annotator rating distributions from a single label by inducing pre-trained models to attend to different portions of the input. Our human evaluations indicate that SeedBERT's attention mechanism is consistent with human sources of annotator disagreement. Moreover, in our empirical evaluations using large language models, SeedBERT demonstrates substantial gains in performance on downstream subjective tasks compared both to standard deep learning models and to other current models that account explicitly for annotator disagreement.