 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEM: Scaling Transformers with Embedding Modules
Jan 15, 2026Fine-grained sparsity promises higher parametric capacity without proportional per-token compute, but often suffers from training instability, load balancing, and communication overhead. We introduce STEM (Scaling Transformers with Embedding Modules), a static, token-indexed approach that replaces the FFN up-projection with a layer-local embedding lookup while keeping the gate and down-projection dense. This removes runtime routing, enables CPU offload with asynchronous prefetch, and decouples capacity from both per-token FLOPs and cross-device communication. Empirically, STEM trains stably despite extreme sparsity. It improves downstream performance over dense baselines while reducing per-token FLOPs and parameter accesses (eliminating roughly one-third of FFN parameters). STEM learns embedding spaces with large angular spread which enhances its knowledge storage capacity. More interestingly, this enhanced knowledge capacity comes with better interpretability. The token-indexed nature of STEM embeddings allows simple ways to perform knowledge editing and knowledge injection in an interpretable manner without any intervention in the input text or additional computation. In addition, STEM strengthens long-context performance: as sequence length grows, more distinct parameters are activated, yielding practical test-time capacity scaling. Across 350M and 1B model scales, STEM delivers up to ~3--4% accuracy improvements overall, with notable gains on knowledge and reasoning-heavy benchmarks (ARC-Challenge, OpenBookQA, GSM8K, MMLU). Overall, STEM is an effective way of scaling parametric memory while providing better interpretability, better training stability and improved efficiency.
RLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
Oct 22, 2025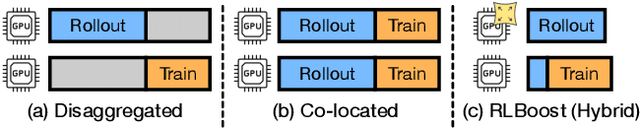
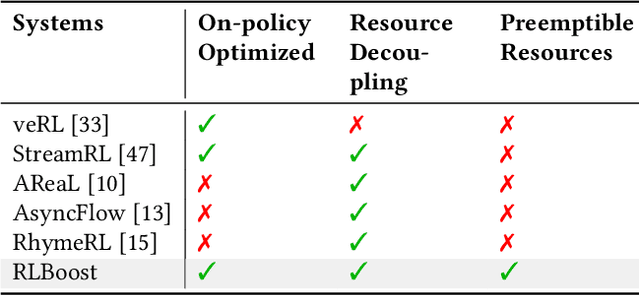
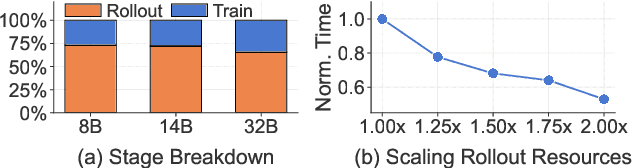
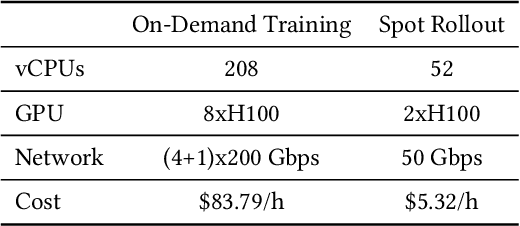
Reinforcement learning (RL) has become essential for unlocking advanced reasoning capabilities in large language models (LLMs). RL workflows involve interleaving rollout and training stages with fundamentally different resource requirements. Rollout typically dominates overall execution time, yet scales efficiently through multiple independent instances. In contrast, training requires tightly-coupled GPUs with full-mesh communication. Existing RL frameworks fall into two categories: co-located and disaggregated architectures. Co-located ones fail to address this resource tension by forcing both stages to share the same GPUs. Disaggregated architectures, without modifications of well-established RL algorithms, suffer from resource under-utilization. Meanwhile, preemptible GPU resources, i.e., spot instances on public clouds and spare capacity in production clusters, present significant cost-saving opportunities for accelerating RL workflows, if efficiently harvested for rollout. In this paper, we present RLBoost, a systematic solution for cost-efficient RL training that harvests preemptible GPU resources. Our key insight is that rollout's stateless and embarrassingly parallel nature aligns perfectly with preemptible and often fragmented resources. To efficiently utilize these resources despite frequent and unpredictable availability changes, RLBoost adopts a hybrid architecture with three key techniques: (1) adaptive rollout offload to dynamically adjust workloads on the reserved (on-demand) cluster, (2) pull-based weight transfer that quickly provisions newly available instances, and (3) token-level response collection and migration for efficient preemption handling and continuous load balancing. Extensive experiments show RLBoost increases training throughput by 1.51x-1.97x while improving cost efficiency by 28%-49% compared to using only on-demand GPU resources.
Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
Jun 11, 2025Autoregressive Large Language Models (AR-LLMs) frequently exhibit implicit parallelism in sequential generation. Inspired by this, we introduce Multiverse, a new generative model that enables natively parallel generation. Multiverse internalizes a MapReduce paradigm, generating automatically through three stages: (i) a Map stage for adaptive task decomposition, (ii) a Process stage for parallel subtask execution, and (iii) a Reduce stage for lossless result synthesis. Next, we build a real-world Multiverse reasoning model with co-design of data, algorithm, and system, enabling rapid and seamless transfer from frontier AR-LLMs. Starting from sequential reasoning chains, we create Multiverse 1K by converting them into structured training data using an automated LLM-assisted pipeline, avoiding costly human annotations. Algorithmically, we design Multiverse Attention to separate parallel reasoning steps while keeping compatibility with causal attention for efficient training. Systematically, we implement Multiverse Engine to enable parallel inference. It features a dedicated scheduler that dynamically switches between sequential and parallel generation, triggered directly by the model. After a 3-hour fine-tuning with 1K examples, our Multiverse-32B stands as the only open-sourced non-AR model achieving performance on par with leading AR-LLMs of the same scale, evidenced by AIME24 & 25 scores of 54% and 46%, respectively. Moreover, our budget control experiments show that Multiverse-32B exhibits superior scaling, outperforming AR-LLMs by 1.87% on average using the same context length. Such scaling further leads to practical efficiency gain, achieving up to 2x speedup across varying batch sizes. We have open-sourced the entire Multiverse ecosystem, including data, model weights, engine, supporting tools, as well as complete data curation prompts and detailed training and evaluation recipes.
Kinetics: Rethinking Test-Time Scaling Laws
Jun 06, 2025We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential and increasingly important with more computing invested, for realizing the full potential of test-time scaling where, unlike training, accuracy has yet to saturate as a function of computation, and continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
Scalable LLM Math Reasoning Acceleration with Low-rank Distillation
May 08, 2025Due to long generations, large language model (LLM) math reasoning demands significant computational resources and time. While many existing efficient inference methods have been developed with excellent performance preservation on language tasks, they often severely degrade math performance. In this paper, we propose Caprese, a low-cost distillation method to recover lost capabilities from deploying efficient inference methods, focused primarily in feedforward blocks. With original weights unperturbed, roughly 1% of additional parameters, and only 20K synthetic training samples, we are able to recover much if not all of the math capabilities lost from efficient inference for thinking LLMs and without harm to language tasks for instruct LLMs. Moreover, Caprese slashes the number of active parameters (~2B cut for Gemma 2 9B and Llama 3.1 8B) and integrates cleanly into existing model layers to reduce latency (>11% reduction to generate 2048 tokens with Qwen 2.5 14B) while encouraging response brevity.
HeadInfer: Memory-Efficient LLM Inference by Head-wise Offloading
Feb 18, 2025



Transformer-based large language models (LLMs) demonstrate impressive performance in long context generation. Extending the context length has disproportionately shifted the memory footprint of LLMs during inference to the key-value cache (KV cache). In this paper, we propose HEADINFER, which offloads the KV cache to CPU RAM while avoiding the need to fully store the KV cache for any transformer layer on the GPU. HEADINFER employs a fine-grained, head-wise offloading strategy, maintaining only selective attention heads KV cache on the GPU while computing attention output dynamically. Through roofline analysis, we demonstrate that HEADINFER maintains computational efficiency while significantly reducing memory footprint. We evaluate HEADINFER on the Llama-3-8B model with a 1-million-token sequence, reducing the GPU memory footprint of the KV cache from 128 GB to 1 GB and the total GPU memory usage from 207 GB to 17 GB, achieving a 92% reduction compared to BF16 baseline inference. Notably, HEADINFER enables 4-million-token inference with an 8B model on a single consumer GPU with 24GB memory (e.g., NVIDIA RTX 4090) without approximation methods.
APE: Faster and Longer Context-Augmented Generation via Adaptive Parallel Encoding
Feb 08, 2025Context-augmented generation (CAG) techniques, including RAG and ICL, require the efficient combination of multiple contexts to generate responses to user queries. Directly inputting these contexts as a sequence introduces a considerable computational burden by re-encoding the combined selection of contexts for every request. To address this, we explore the promising potential of parallel encoding to independently pre-compute and cache each context's KV states. This approach enables the direct loading of cached states during inference while accommodating more contexts through position reuse across contexts. However, due to misalignments in attention distribution, directly applying parallel encoding results in a significant performance drop. To enable effective and efficient CAG, we propose Adaptive Parallel Encoding ($\textbf{APE}$), which brings shared prefix, attention temperature, and scaling factor to align the distribution of parallel encoding with sequential encoding. Results on RAG and ICL tasks demonstrate that APE can preserve 98% and 93% sequential encoding performance using the same inputs while outperforming parallel encoding by 3.6% and 7.9%, respectively. It also scales to many-shot CAG, effectively encoding hundreds of contexts in parallel. Efficiency evaluation shows that APE can achieve an end-to-end 4.5$\times$ speedup by reducing 28$\times$ prefilling time for a 128K-length context.
GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity?
Feb 07, 2025Long-context large language models (LLMs) have recently shown strong performance in information retrieval and long-document QA. However, to tackle the most challenging intellectual problems, LLMs must reason effectively in long and complex contexts (e.g., frontier mathematical research). Studying how LLMs handle increasing reasoning complexity and context length is essential, yet existing benchmarks lack a solid basis for quantitative evaluation. Inspired by the abstraction of GSM-8K problems as computational graphs, and the ability to introduce noise by adding unnecessary nodes and edges, we develop a grade school math problem generator capable of producing arithmetic problems with infinite difficulty and context length under fine-grained control. Using our newly synthesized GSM-Infinite benchmark, we comprehensively evaluate existing LLMs. We find a consistent sigmoid decline in reasoning performance as complexity increases, along with a systematic inference scaling trend: exponentially increasing inference computation yields only linear performance gains. These findings underscore the fundamental limitations of current long-context LLMs and the key challenges in scaling reasoning capabilities. Our GSM-Infinite benchmark provides a scalable and controllable testbed for systematically studying and advancing LLM reasoning in long and complex contexts.
Speculative Prefill: Turbocharging TTFT with Lightweight and Training-Free Token Importance Estimation
Feb 05, 2025



Improving time-to-first-token (TTFT) is an essentially important objective in modern large language model (LLM) inference engines. Because optimizing TTFT directly results in higher maximal QPS and meets the requirements of many critical applications. However, boosting TTFT is notoriously challenging since it is purely compute-bounded and the performance bottleneck shifts from the self-attention to the MLP part. We present SpecPrefill, a training free framework that accelerates the inference TTFT for both long and medium context queries based on the following insight: LLMs are generalized enough to still preserve the quality given only a carefully chosen subset of prompt tokens. At its core, SpecPrefill leverages a lightweight model to speculate locally important tokens based on the context. These tokens, along with the necessary positional information, are then sent to the main model for processing. We evaluate SpecPrefill with a diverse set of tasks, followed by a comprehensive benchmarking of performance improvement both in a real end-to-end setting and ablation studies. SpecPrefill manages to serve Llama-3.1-405B-Instruct-FP8 with up to $7\times$ maximal end-to-end QPS on real downstream tasks and $7.66\times$ TTFT improvement during benchmarking.
S$^{2}$FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured Sparsity
Dec 10, 2024



Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability. Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (S$^{2}$FT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. S$^{2}$FT accomplishes this by "selecting sparsely and computing densely". It selects a few heads and channels in the MHA and FFN modules for each Transformer block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, S$^{2}$FT performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents overfitting and forgetting, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and surpasses full FT by 11.5% when generalizing to various domains after instruction tuning. Using our partial backpropagation algorithm, S$^{2}$FT saves training memory up to 3$\times$ and improves latency by 1.5-2.7$\times$ compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that the weight updates in S$^{2}$FT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.