 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATA: Bridging Implicit Reasoning with Attention-Guided and Action-Guided Inference for Vision-Language Action Models
Mar 02, 2026Vision-Language-Action (VLA) models rely on current observations, including images, language instructions, and robot states, to predict actions and complete tasks. While accurate visual perception is crucial for precise action prediction and execution, recent work has attempted to further improve performance by introducing explicit reasoning during inference. However, such approaches face significant limitations. They often depend on data-intensive resources such as Chain-of-Thought (CoT) style annotations to decompose tasks into step-by-step reasoning, and in many cases require additional visual grounding annotations (e.g., bounding boxes or masks) to highlight relevant image regions. Moreover, they involve time-consuming dataset construction, labeling, and retraining, which ultimately results in longer inference sequences and reduced efficiency. To address these challenges, we propose ATA, a novel training-free framework that introduces implicit reasoning into VLA inference through complementary attention-guided and action-guided strategies. Unlike CoT or explicit visual-grounding methods, ATA formulates reasoning implicitly by integrating attention maps with an action-based region of interest (RoI), thereby adaptively refining visual inputs without requiring extra training or annotations. ATA is a plug-and-play implicit reasoning approach for VLA models, lightweight yet effective. Extensive experiments show that it consistently improves task success and robustness while preserving, and even enhancing, inference efficiency.
InstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
EcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
HeadInfer: Memory-Efficient LLM Inference by Head-wise Offloading
Feb 18, 2025



Transformer-based large language models (LLMs) demonstrate impressive performance in long context generation. Extending the context length has disproportionately shifted the memory footprint of LLMs during inference to the key-value cache (KV cache). In this paper, we propose HEADINFER, which offloads the KV cache to CPU RAM while avoiding the need to fully store the KV cache for any transformer layer on the GPU. HEADINFER employs a fine-grained, head-wise offloading strategy, maintaining only selective attention heads KV cache on the GPU while computing attention output dynamically. Through roofline analysis, we demonstrate that HEADINFER maintains computational efficiency while significantly reducing memory footprint. We evaluate HEADINFER on the Llama-3-8B model with a 1-million-token sequence, reducing the GPU memory footprint of the KV cache from 128 GB to 1 GB and the total GPU memory usage from 207 GB to 17 GB, achieving a 92% reduction compared to BF16 baseline inference. Notably, HEADINFER enables 4-million-token inference with an 8B model on a single consumer GPU with 24GB memory (e.g., NVIDIA RTX 4090) without approximation methods.
COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
Nov 26, 2024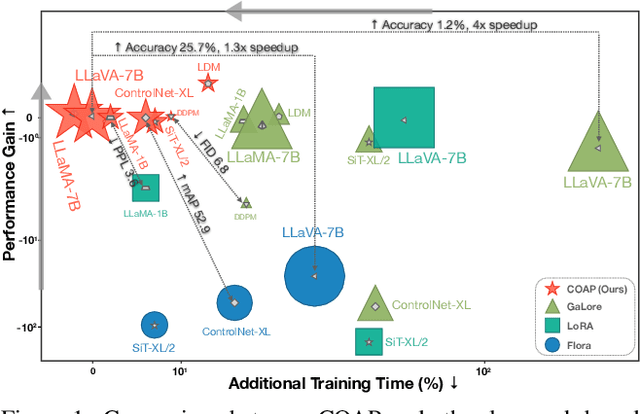
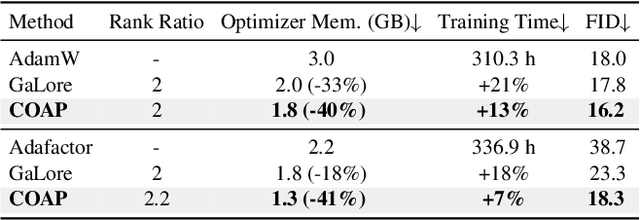
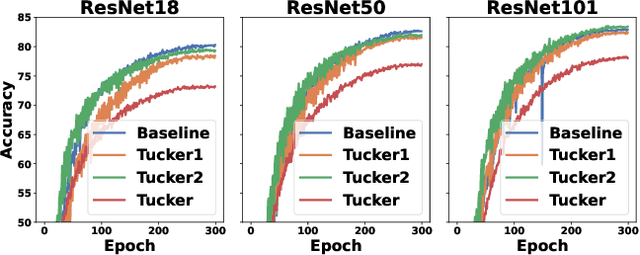
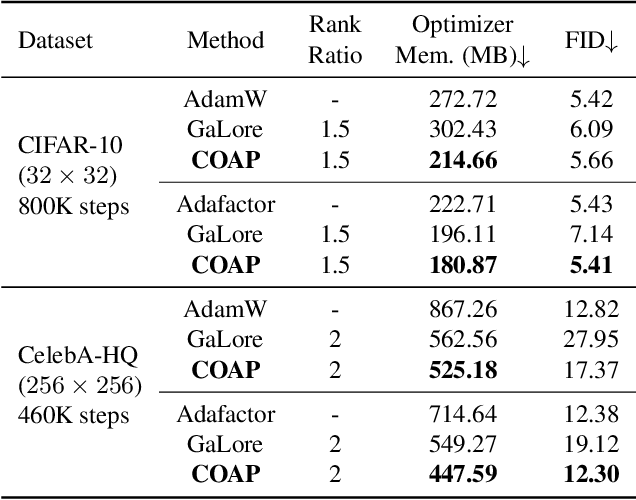
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (Correlation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

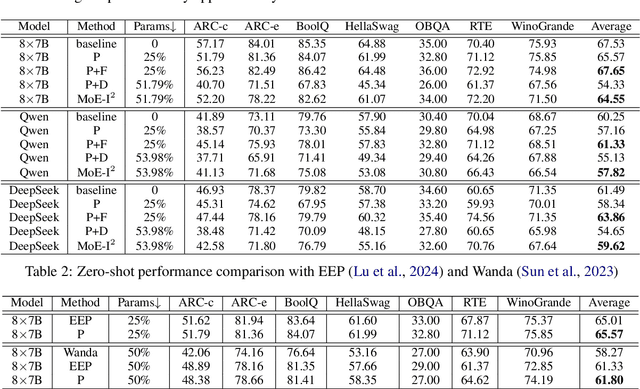
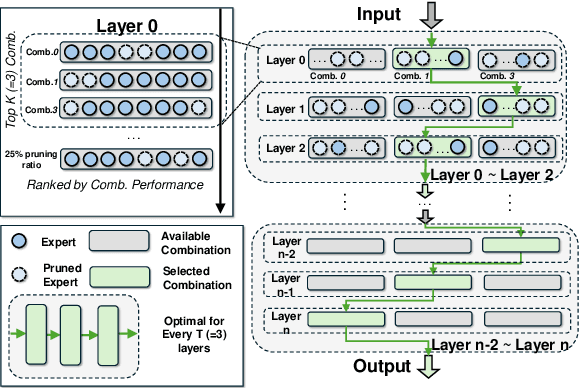
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}
DisDet: Exploring Detectability of Backdoor Attack on Diffusion Models
Feb 05, 2024
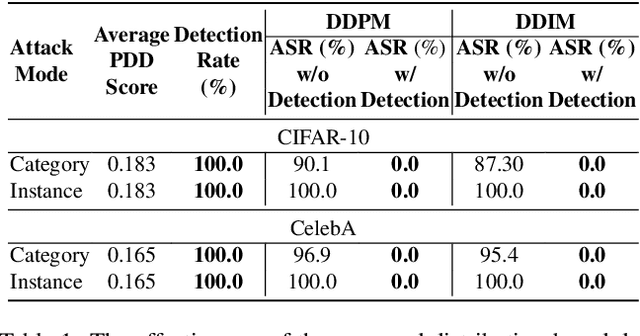

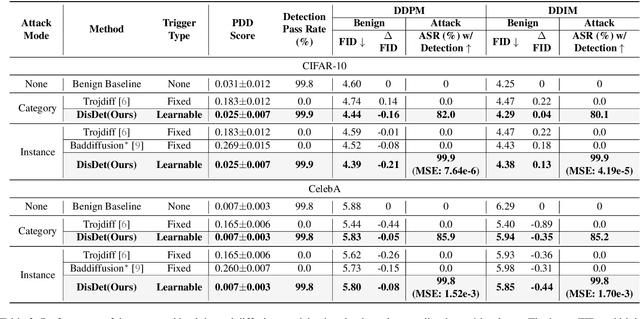
In the exciting generative AI era, the diffusion model has emerged as a very powerful and widely adopted content generation and editing tool for various data modalities, making the study of their potential security risks very necessary and critical. Very recently, some pioneering works have shown the vulnerability of the diffusion model against backdoor attacks, calling for in-depth analysis and investigation of the security challenges of this popular and fundamental AI technique. In this paper, for the first time, we systematically explore the detectability of the poisoned noise input for the backdoored diffusion models, an important performance metric yet little explored in the existing works. Starting from the perspective of a defender, we first analyze the properties of the trigger pattern in the existing diffusion backdoor attacks, discovering the important role of distribution discrepancy in Trojan detection. Based on this finding, we propose a low-cost trigger detection mechanism that can effectively identify the poisoned input noise. We then take a further step to study the same problem from the attack side, proposing a backdoor attack strategy that can learn the unnoticeable trigger to evade our proposed detection scheme. Empirical evaluations across various diffusion models and datasets demonstrate the effectiveness of the proposed trigger detection and detection-evading attack strategy. For trigger detection, our distribution discrepancy-based solution can achieve a 100\% detection rate for the Trojan triggers used in the existing works. For evading trigger detection, our proposed stealthy trigger design approach performs end-to-end learning to make the distribution of poisoned noise input approach that of benign noise, enabling nearly 100\% detection pass rate with very high attack and benign performance for the backdoored diffusion models.
ELRT: Efficient Low-Rank Training for Compact Convolutional Neural Networks
Jan 18, 2024Low-rank compression, a popular model compression technique that produces compact convolutional neural networks (CNNs) with low rankness, has been well-studied in the literature. On the other hand, low-rank training, as an alternative way to train low-rank CNNs from scratch, has been exploited little yet. Unlike low-rank compression, low-rank training does not need pre-trained full-rank models, and the entire training phase is always performed on the low-rank structure, bringing attractive benefits for practical applications. However, the existing low-rank training solutions still face several challenges, such as a considerable accuracy drop and/or still needing to update full-size models during the training. In this paper, we perform a systematic investigation on low-rank CNN training. By identifying the proper low-rank format and performance-improving strategy, we propose ELRT, an efficient low-rank training solution for high-accuracy, high-compactness, low-rank CNN models. Our extensive evaluation results for training various CNNs on different datasets demonstrate the effectiveness of ELRT.
COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models
Jun 09, 2023



Attention-based vision models, such as Vision Transformer (ViT) and its variants, have shown promising performance in various computer vision tasks. However, these emerging architectures suffer from large model sizes and high computational costs, calling for efficient model compression solutions. To date, pruning ViTs has been well studied, while other compression strategies that have been widely applied in CNN compression, e.g., model factorization, is little explored in the context of ViT compression. This paper explores an efficient method for compressing vision transformers to enrich the toolset for obtaining compact attention-based vision models. Based on the new insight on the multi-head attention layer, we develop a highly efficient ViT compression solution, which outperforms the state-of-the-art pruning methods. For compressing DeiT-small and DeiT-base models on ImageNet, our proposed approach can achieve 0.45% and 0.76% higher top-1 accuracy even with fewer parameters. Our finding can also be applied to improve the customization efficiency of text-to-image diffusion models, with much faster training (up to $2.6\times$ speedup) and lower extra storage cost (up to $1927.5\times$ reduction) than the existing works.
HALOC: Hardware-Aware Automatic Low-Rank Compression for Compact Neural Networks
Jan 20, 2023



Low-rank compression is an important model compression strategy for obtaining compact neural network models. In general, because the rank values directly determine the model complexity and model accuracy, proper selection of layer-wise rank is very critical and desired. To date, though many low-rank compression approaches, either selecting the ranks in a manual or automatic way, have been proposed, they suffer from costly manual trials or unsatisfied compression performance. In addition, all of the existing works are not designed in a hardware-aware way, limiting the practical performance of the compressed models on real-world hardware platforms. To address these challenges, in this paper we propose HALOC, a hardware-aware automatic low-rank compression framework. By interpreting automatic rank selection from an architecture search perspective, we develop an end-to-end solution to determine the suitable layer-wise ranks in a differentiable and hardware-aware way. We further propose design principles and mitigation strategy to efficiently explore the rank space and reduce the potential interference problem. Experimental results on different datasets and hardware platforms demonstrate the effectiveness of our proposed approach. On CIFAR-10 dataset, HALOC enables 0.07% and 0.38% accuracy increase over the uncompressed ResNet-20 and VGG-16 models with 72.20% and 86.44% fewer FLOPs, respectively. On ImageNet dataset, HALOC achieves 0.9% higher top-1 accuracy than the original ResNet-18 model with 66.16% fewer FLOPs. HALOC also shows 0.66% higher top-1 accuracy increase than the state-of-the-art automatic low-rank compression solution with fewer computational and memory costs. In addition, HALOC demonstrates the practical speedups on different hardware platforms, verified by the measurement results on desktop GPU, embedded GPU and ASIC accelerator.