 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Demonstrations via Capability-Aware Goal Sampling
Jan 13, 2026Despite its promise, imitation learning often fails in long-horizon environments where perfect replication of demonstrations is unrealistic and small errors can accumulate catastrophically. We introduce Cago (Capability-Aware Goal Sampling), a novel learning-from-demonstrations method that mitigates the brittle dependence on expert trajectories for direct imitation. Unlike prior methods that rely on demonstrations only for policy initialization or reward shaping, Cago dynamically tracks the agent's competence along expert trajectories and uses this signal to select intermediate steps--goals that are just beyond the agent's current reach--to guide learning. This results in an adaptive curriculum that enables steady progress toward solving the full task. Empirical results demonstrate that Cago significantly improves sample efficiency and final performance across a range of sparse-reward, goal-conditioned tasks, consistently outperforming existing learning from-demonstrations baselines.
* 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
Learning World Models for Unconstrained Goal Navigation
Nov 03, 2024



Learning world models offers a promising avenue for goal-conditioned reinforcement learning with sparse rewards. By allowing agents to plan actions or exploratory goals without direct interaction with the environment, world models enhance exploration efficiency. The quality of a world model hinges on the richness of data stored in the agent's replay buffer, with expectations of reasonable generalization across the state space surrounding recorded trajectories. However, challenges arise in generalizing learned world models to state transitions backward along recorded trajectories or between states across different trajectories, hindering their ability to accurately model real-world dynamics. To address these challenges, we introduce a novel goal-directed exploration algorithm, MUN (short for "World Models for Unconstrained Goal Navigation"). This algorithm is capable of modeling state transitions between arbitrary subgoal states in the replay buffer, thereby facilitating the learning of policies to navigate between any "key" states. Experimental results demonstrate that MUN strengthens the reliability of world models and significantly improves the policy's capacity to generalize across new goal settings.
Exploring the Edges of Latent State Clusters for Goal-Conditioned Reinforcement Learning
Nov 03, 2024Exploring unknown environments efficiently is a fundamental challenge in unsupervised goal-conditioned reinforcement learning. While selecting exploratory goals at the frontier of previously explored states is an effective strategy, the policy during training may still have limited capability of reaching rare goals on the frontier, resulting in reduced exploratory behavior. We propose "Cluster Edge Exploration" ($CE^2$), a new goal-directed exploration algorithm that when choosing goals in sparsely explored areas of the state space gives priority to goal states that remain accessible to the agent. The key idea is clustering to group states that are easily reachable from one another by the current policy under training in a latent space and traversing to states holding significant exploration potential on the boundary of these clusters before doing exploratory behavior. In challenging robotics environments including navigating a maze with a multi-legged ant robot, manipulating objects with a robot arm on a cluttered tabletop, and rotating objects in the palm of an anthropomorphic robotic hand, $CE^2$ demonstrates superior efficiency in exploration compared to baseline methods and ablations.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

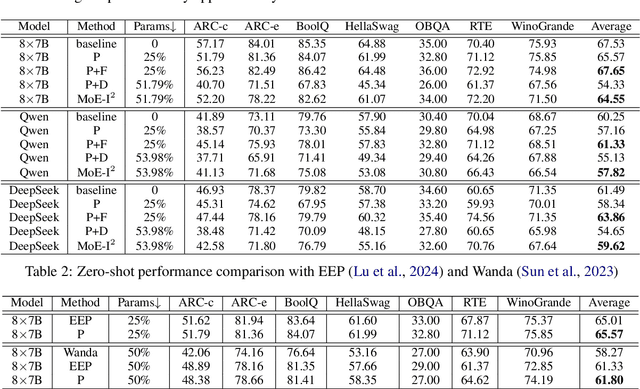
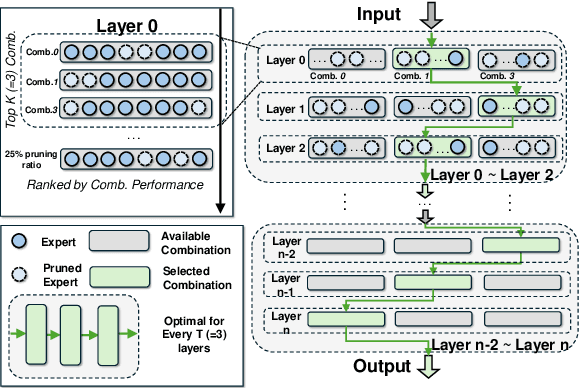
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}